本實戰項目通過python爬取豆瓣電影Top250榜單,利用flask框架和Echarts圖表分析評分、上映年份並將結果可視化,並制作了詞雲,項目已經上傳至服務器,歡迎各位大佬批評指正。
項目展示:http://121.36.81.197:5000/
源碼地址:https://github.com/lzz110/douban_movies_top250
學習資料:Python爬蟲技術5天速成(2020全新合集)
項目技術棧:Flask框架、Echarts、WordCloud、SQLite
環境:Python3
開發工具:PyCharm
爬取鏈接: https://movie.douban.com/top250
excel 與數據庫文件:excel 與數據庫文件下載
from bs4 import BeautifulSoup # 網頁解析,獲取數據
import re # 正則表達式,與文字匹配
import xlwt # 制定URL,獲取網頁數據
import urllib.request, urllib.error # 進行excel操作
import sqlite3 # 進行sqlite數據庫操作
def askURL(url):
head = {
# 模擬浏覽器頭部信息,向服務器發送消息
"User-Agent": " Mozilla / 5.0(Windows NT 10.0;Win64;x64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 83.0.4103.116Safari / 537.36"
} # 告訴浏覽器我們接受什麼水平的文件內容
request = urllib.request.Request(url, headers=head)
try:
response = urllib.request.urlopen(request)
html = response.read().decode("utf-8")
# print(html)
except urllib.error.URLError as e:
if hasattr(e, "code"):
print(e.code)
if hasattr(e, "reason"):
print(e.reason)
return html
def getData(baseurl):
datalist = []
for i in range(0, 10):
url = baseurl + str(i * 25)
html = askURL(url) # 保存爬取的網頁源碼
# 逐一解析數據
soup = BeautifulSoup(html, "html.parser")
for item in soup.find_all('div', class_="item"):
# print(item) # 測試
data = [] # 保存
item = str(item)
# re庫正則表達式來查找指定字符串,形成列表
Link = re.findall(findLink, item)[0] # 鏈接
# print(Link)
data.append(Link)
ImaSrc = re.findall(findImaSrc, item)[0] # 圖片鏈接
# print(ImaSrc)
data.append(ImaSrc)
Title = re.findall(findTitle, item)[0] # 片名:可能只有一個中文名,沒有外譯名字
if (len(Title) == 2):
# print("完整title="+Title)
cTitle = Title[0] # 添加中文名
# print(cTitle)
data.append(Title)
oTitle = Title[1].replace("/", "") # 外譯片名
# print(oTitle)
# data.append(' ')
else:
data.append(Title)
# data.append(' ')
# print(Title)
Rating = re.findall(findRating, item)[0] # 評分
data.append(Rating)
Judge = re.findall(findJudge, item)[0] # 評價人數
data.append(Judge)
Inq = re.findall(findInq, item) # 概述
if len(Inq) != 0:
Inq = Inq[0].replace("。", "") # 去掉句號
data.append(Inq)
else:
data.append(" ") # 留空
Bd = re.findall(findBd, item)[0] # 相關內容
temp = re.search('[0-9]+.*\/?', Bd).group().split('/')
year, country, category = temp[0], temp[1], temp[2] # 得到年份、地區、類型
data.append(year)
data.append(country)
data.append(category)
datalist.append(data) # 把處理好的一部電影信息放入datalist
return datalist
將爬取結果數據保存成兩種格式(數據庫 和 excel表格):
def saveData(datalist, savepath):
print("save...")
book = xlwt.Workbook(encoding="utf-8") # 創建workbook對象
sheet = book.add_sheet('豆瓣電影Top250', cell_overwrite_ok=True) # 創建工作表
# 制作表頭
col = ("電影詳情鏈接", "圖片鏈接", "中文名", "評分", "評價數", "概述", "上映年份","制片國家","類型")
for i in range(0, len(col)):
sheet.write(0, i, col[i])
for i in range(0, 250):
# print("第%d條"%(i+1))
data = datalist[i]
for j in range(0, len(col)):
sheet.write(i + 1, j, data[j])
book.save(savepath) # 保存
保存至excel結果: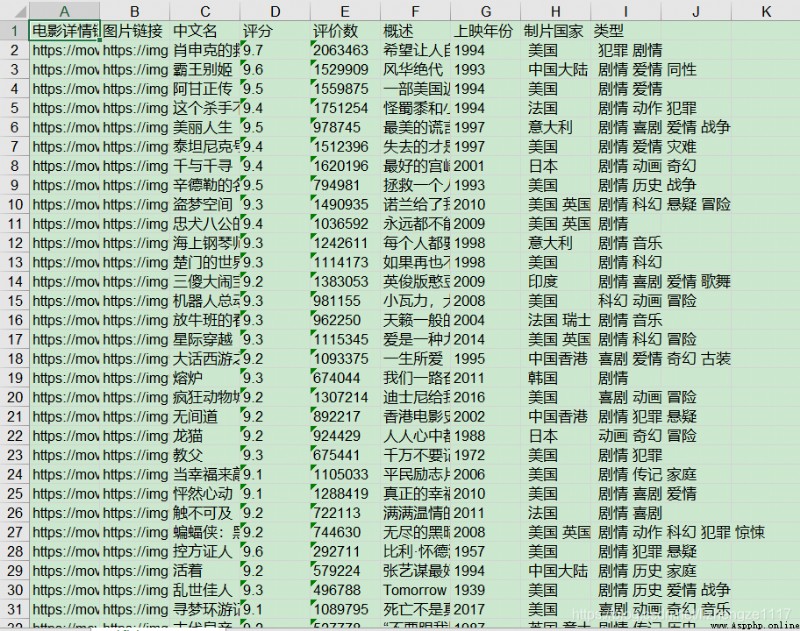
def saveData2DB(datalist, dbpath):
init_db(dbpath)
conn = sqlite3.connect(dbpath)
cur = conn.cursor()
for data in datalist:
for index in range(len(data)):
data[index] = '"' + data[index] + '"'
sql = ''' insert into movie250( info_link, pic_link, cname, score,rated, introduction,year_release,country,category ) values(%s)''' % ",".join(data)
# print(sql)
cur.execute(sql)
conn.commit()
cur.close()
conn.close
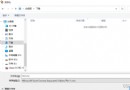
保存至數據庫結果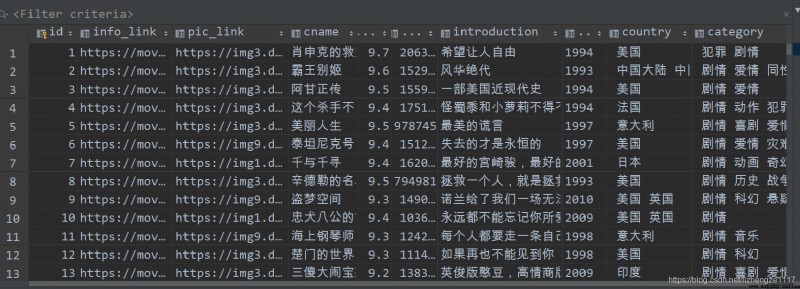
至此爬取數據部分結束,下一章是電影數據處理和可視化