This practical project has passed python Crawling for Douban movie Top250 The list , utilize flask frame and Echarts Chart Analysis score 、 Release year and visualize results , And made The word cloud , The project has been uploaded to the server , Welcome to criticize and correct .
Project presentation :http://121.36.81.197:5000/
Source code address :https://github.com/lzz110/douban_movies_top250
Learning materials :Python Reptile technology 5 It's a quick success (2020 New collection )
Project technology stack :Flask frame 、Echarts、WordCloud、SQLite
Environmental Science :Python3
development tool :PyCharm
Crawling Links : https://movie.douban.com/top250
excel And database files :excel And database file download
from bs4 import BeautifulSoup # Web page parsing , get data
import re # Regular expressions , Match with text
import xlwt # To develop URL, Get web data
import urllib.request, urllib.error # Conduct excel operation
import sqlite3 # Conduct sqlite Database operation
def askURL(url):
head = {
# Simulate browser header information , Send a message to the server
"User-Agent": " Mozilla / 5.0(Windows NT 10.0;Win64;x64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 83.0.4103.116Safari / 537.36"
} # Tell the browser what level of file content we accept
request = urllib.request.Request(url, headers=head)
try:
response = urllib.request.urlopen(request)
html = response.read().decode("utf-8")
# print(html)
except urllib.error.URLError as e:
if hasattr(e, "code"):
print(e.code)
if hasattr(e, "reason"):
print(e.reason)
return html
def getData(baseurl):
datalist = []
for i in range(0, 10):
url = baseurl + str(i * 25)
html = askURL(url) # Save the crawled web page source code
# Parse the data one by one
soup = BeautifulSoup(html, "html.parser")
for item in soup.find_all('div', class_="item"):
# print(item) # test
data = [] # preservation
item = str(item)
# re Library regular expression to find the specified string , Form a list
Link = re.findall(findLink, item)[0] # link
# print(Link)
data.append(Link)
ImaSrc = re.findall(findImaSrc, item)[0] # Picture links
# print(ImaSrc)
data.append(ImaSrc)
Title = re.findall(findTitle, item)[0] # title : There may only be one Chinese name , There is no translated name
if (len(Title) == 2):
# print(" complete title="+Title)
cTitle = Title[0] # Add Chinese name
# print(cTitle)
data.append(Title)
oTitle = Title[1].replace("/", "") # Translated title
# print(oTitle)
# data.append(' ')
else:
data.append(Title)
# data.append(' ')
# print(Title)
Rating = re.findall(findRating, item)[0] # score
data.append(Rating)
Judge = re.findall(findJudge, item)[0] # Number of evaluators
data.append(Judge)
Inq = re.findall(findInq, item) # summary
if len(Inq) != 0:
Inq = Inq[0].replace(".", "") # Remove the full stop
data.append(Inq)
else:
data.append(" ") # leave a blank
Bd = re.findall(findBd, item)[0] # Related content
temp = re.search('[0-9]+.*\/?', Bd).group().split('/')
year, country, category = temp[0], temp[1], temp[2] # Get the year 、 region 、 type
data.append(year)
data.append(country)
data.append(category)
datalist.append(data) # Put the processed information of a movie into datalist
return datalist
Save the crawl result data in two formats ( database and excel form ):
def saveData(datalist, savepath):
print("save...")
book = xlwt.Workbook(encoding="utf-8") # establish workbook object
sheet = book.add_sheet(' Watercress movie Top250', cell_overwrite_ok=True) # Create sheet
# Make header
col = (" Movie details link ", " Picture links ", " Chinese name ", " score ", " Evaluation number ", " summary ", " Release year "," Producer country "," type ")
for i in range(0, len(col)):
sheet.write(0, i, col[i])
for i in range(0, 250):
# print(" The first %d strip "%(i+1))
data = datalist[i]
for j in range(0, len(col)):
sheet.write(i + 1, j, data[j])
book.save(savepath) # preservation
Save to excel result :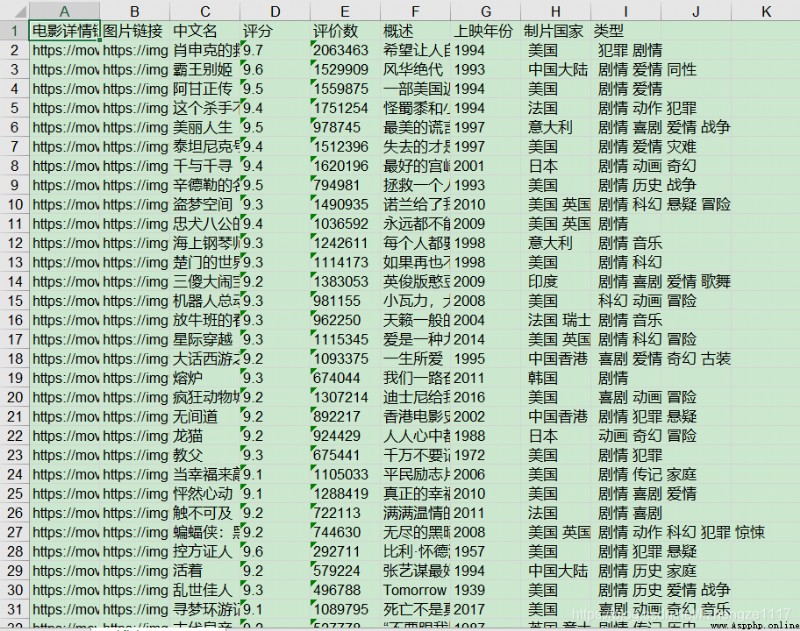
def saveData2DB(datalist, dbpath):
init_db(dbpath)
conn = sqlite3.connect(dbpath)
cur = conn.cursor()
for data in datalist:
for index in range(len(data)):
data[index] = '"' + data[index] + '"'
sql = ''' insert into movie250( info_link, pic_link, cname, score,rated, introduction,year_release,country,category ) values(%s)''' % ",".join(data)
# print(sql)
cur.execute(sql)
conn.commit()
cur.close()
conn.close
Save to database results 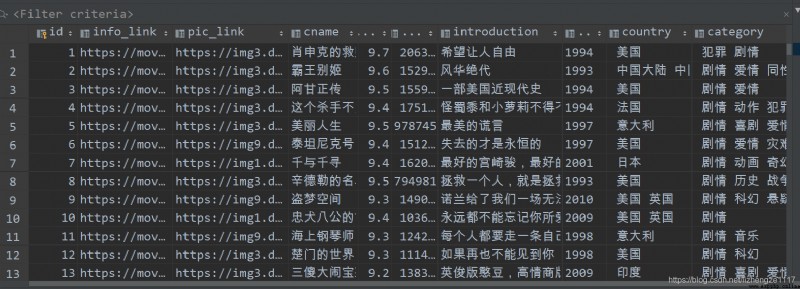
This completes the crawling data section , The next chapter is Movie data processing and visualization