Table des matières
Un.、K-MeansPrincipes
1.Introduction au regroupement
①Regroupement stratifié
②Regroupement des centroïdes
③Autres regroupements
2.K-meansLe principe
3.K-meansScénarios d'application pour
2.、K-MeansLe cas de
1.Affichage des données
① Importation de données et visualisation de la structure
②Voir la description des données
2. Visualisation et prétraitement des données
①Diagramme à barres
②Thermographe
③Carte de densité nucléaire
④Diagramme de dispersion
⑤Schéma du type de boîte
3. Formation au modèle et évaluation de la précision
①Sélection des échantillons
②Formation sur modèle
③Évaluation de la précision
④Paramètres du modèle
Trois、Conclusions
Dans cet article,Vous apprendrez:
0 K-meansLes principes mathématiques de
1 K-meansDeScikit-LearnExplication de la fonction
2 K-meansLe cas de

Il y a 100 Algorithme de regroupement multiple, Leur utilisation dépend de la nature des données disponibles . Nous discutons de quelques algorithmes principaux .
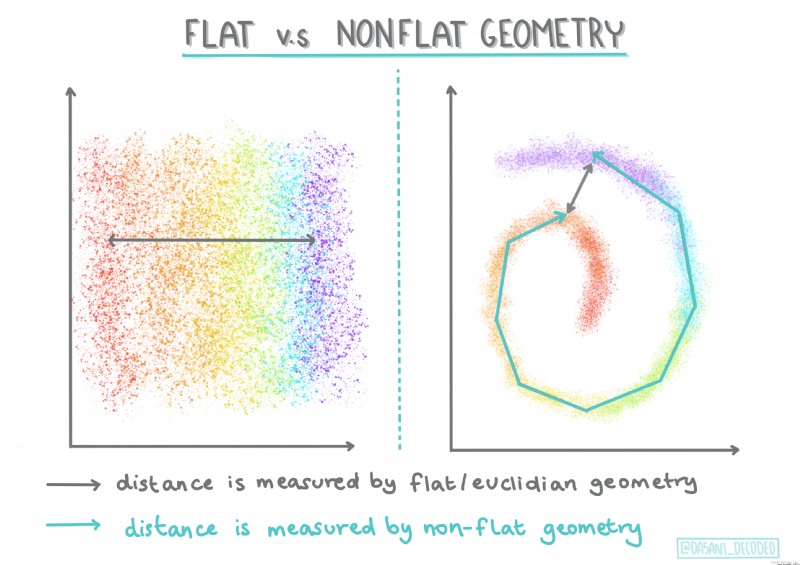
Regroupement stratifié. Si un objet est classé en fonction de sa proximité d'un objet voisin et non d'un objet plus éloigné , Pour former un Cluster basé sur la distance entre ses membres et d'autres objets .
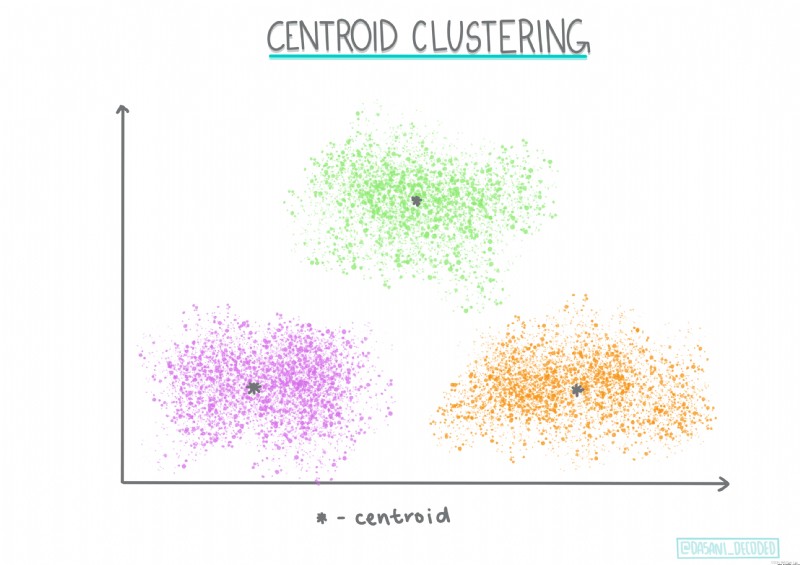
Regroupement des centroïdes. Cet algorithme de regroupement populaire nécessite un choix K(Nombre de grappes), Ensuite, l'algorithme détermine le point central du cluster et recueille des données autour de ce point. .K Regroupement moyen Est une version populaire du regroupement des centroïdes . Le Centre de masse est déterminé par la moyenne de tous les points d'échantillonnage de sa catégorie. ,D'où son nom.
Regroupement basé sur la distribution . Basé sur la modélisation statistique , L'analyse de regroupement basée sur la distribution met l'accent sur la détermination de la probabilité que les points de données appartiennent au regroupement. , Et l'assigner en conséquence . La méthode de mélange gaussienne appartient à ce type .
Regroupement basé sur la densité. Les points de données sont attribués au regroupement en fonction de leur densité ou de leur regroupement entre eux. . Les points de données éloignés du Groupe sont considérés comme des valeurs aberrantes ou du bruit .DBSCAN、 Les décalages moyens, etc., appartiennent tous à ce type de regroupement .
Clusters basés sur la grille .Pour cube, Un maillage sera créé , Et diviser les données entre les cellules de la grille , Pour créer un Cluster .
Pour faciliter l'étude , Dans cet article, nous ne discuterons que de K-MeansAlgorithmes, D'autres algorithmes de regroupement que j'écrirai séparément .
Commençons par un classique K-meansL'histoire:
0 Il était une fois, Il y a quatre prêtres sur le sentier de banlieue. , Au début, le pasteur a choisi quelques sermons. , Et j'ai fait connaître ces sermons à tous les habitants de la banlieue. , Alors chaque habitant est allé à l'endroit le plus proche de sa maison pour prendre des leçons .
1 Après les cours,Tout le monde pense que c'est trop loin, Chaque Pasteur a compté les adresses de tous les résidents de sa classe ,Au cœur de toutes les adresses,Et a mis à jour la position de son point de prédication sur l'affiche.
2 Chaque mouvement d'un prêtre ne peut pas être plus proche de tout le monde,Quelqu'un a découvertA Quand le pasteur se déplace, autant y aller seul. BL'aumônerie est plus proche, Et chaque habitant est retourné au lieu de prédication le plus proche. ...C'est tout.,Les prêtres renouvellent leur position chaque semaine, Les habitants choisissent les lieux de prédication en fonction de leur situation ,Enfin stabilisé.
C'estK-meansÉtapes de calcul pour:
0 Définissez d'abord le nombre total de catégories (Cluster)
1 Chaque centre de Cluster (Centroïde) Répartition aléatoire des coordonnées
2 Associer chaque point de données de l'échantillon au centre de masse le plus proche du point de l'échantillon , C'est - à - dire l'attribution de sa catégorie
3 Trouver le point central de tous les points associés pour chaque Cluster ( Moyenne de la distance euclidienne entre l'échantillon et le Centre de masse )
4 Utilisez ce point moyen comme nouveau centre de masse pour cette catégorie
5 C'est comme ça qu'on s'entraîne. , Jusqu'à ce que la position du point que chaque grappe possède ne change pas
Attention!!Dans ce processus, Seule la position du Centre de masse change , La position du point d'échantillonnage reste inchangée !
C'est la formule de calcul de la distance euclidienne entre le Centre de masse et le point d'échantillonnage :
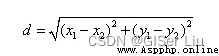
Cette histoire classique est vraie K La compréhension de la moyenne est utile ,Dans l'histoire, La position du pasteur est le centroïde , L'emplacement de la résidence est le point d'échantillonnage. . Chaque fois que la position du prêtre est ajustée, Une itération.Différents types deK-means La méthode de calcul de la distance correspondant à l'algorithme est également différente .
0 Classificateur de changement de rapport
1 Optimisation de la transmission des articles
2 Identifier le lieu de l'événement
3 Classification des utilisateurs
4 Analyse du Statut du personnel
5 Détection de fraude en matière d'assurance
6 Analyse des données de voyage
7 Analyse des réseaux criminels
8 Polygone Tyson
...
Entrez le code suivant, Importer les ensembles de données musicales nigérianes dont nous avons besoin notebook Et voir sa structure organisationnelle .
import matplotlib.pyplot as plt
import pandas as pd
df = pd.read_csv("nigerian-songs.csv")#ParpandasDe la bibliothèqueread_csvLecture de la fonctioncsvDocumentation
df.head()#Avant de voir5Données de ligneLes résultats sont les suivants::
Il y a des informations de base sur la musique (Nom、Artistes、 Date de publication, etc. ),Entrez le code suivant, Voir sa structure de données :
df.info()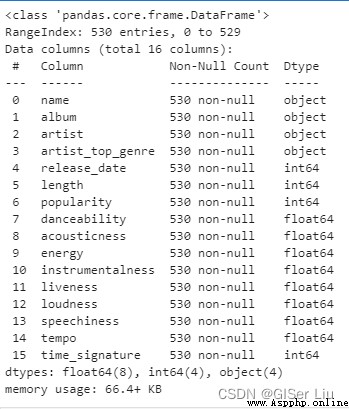
Je vois., L'ensemble de données musicales du Nigeria contient au total 539Exemple de ligne.Oui.16 Caractéristiques des données à sélectionner : Les données numériques sont 12- Oui., Les données de type caractère ont 4- Oui..
Saisissez le code suivant pour voir la description des données :
df.describe()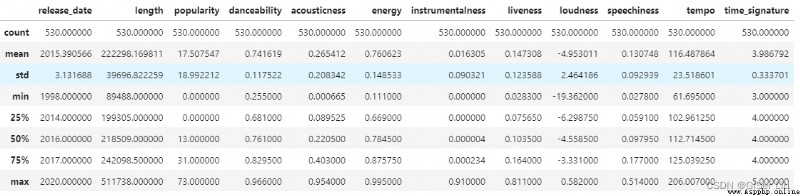 En regardant la description des données , Nous pouvons voir le nombre de caractéristiques de données différentes 、Moyenne、 Variance et valeurs à différents niveaux . Cette information peut nous aider à choisir le modèle ou le traitement approprié pour le traitement ultérieur. .
En regardant la description des données , Nous pouvons voir le nombre de caractéristiques de données différentes 、Moyenne、 Variance et valeurs à différents niveaux . Cette information peut nous aider à choisir le modèle ou le traitement approprié pour le traitement ultérieur. .
Si nous utilisons l'analyse en grappes , Il s'agit d'une méthode non supervisée qui n'exige pas de données marquées , Pourquoi avons - nous besoin de cette information? ? Au cours de la phase d'exploration des données ,Ils seront utiles!
Visualisation des données, Caractéristiques de visualisation des données . Cette fois, l'auteur utilise seaborn Visualisation de la bibliothèque ,seabornLa bibliothèque est basée surmatplotlibBibliothèque encapsulée, Meilleure visualisation !
Avant cela, nous enlevons les échantillons de données qui contiennent des valeurs manquantes , Éviter ses effets . Voir les données pour les valeurs manquantes ou anormales ,Entrez le code suivant:
df.isnull().sum()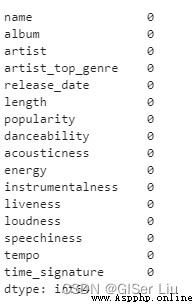
Je vois., Les données sont relativement propres cette fois ,Aucune valeur manquante. On commence à visualiser !
Avant d'entrer le code suivant pour voir le nombre d'ensembles de données 5 Nom de l'artiste type nombre de barres :
import seaborn as sns#ImporterseabornSac
top = df['artist_top_genre'].value_counts()# Un résumé statistique des différents types de musiciens ,Le format est une liste
plt.figure(figsize=(10,7))#Définir la taille du diagramme
sns.barplot(x=top[:5].index,y=top[:5].values)#Avant le retrait5Ligne de donnéesindexEn tant queXType d'arbre, La quantité de musique est Y La valeur de l'axe dessine un diagramme à barres
plt.xticks(rotation=45)#SiX L'étiquette de l'axe est trop longue, ce qui entraîne une mauvaise visualisation , Rotation de l'étiquette réglable
plt.title('Top genres',color = 'blue')# Définir le contenu et la couleur du titre du diagramme à barres 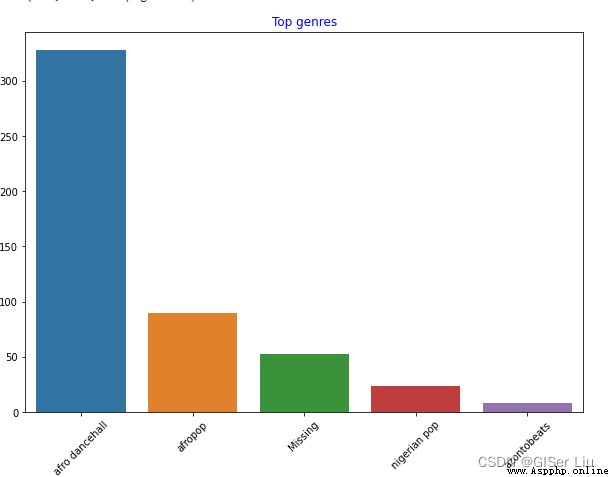
Je vois.,Avant5 Parmi les styles ,afro dancehall Le plus grand nombre de musique de style ; Les étudiants aux yeux pointus pourraient trouver , Une partie de ces données est “Missing”, Cela signifie qu'il n'y a pas d'étiquette de type pour cette partie des données , Pour faciliter l'analyse , Nous rejetons cette partie des données !
Dans la plupart des ensembles de données ,🤨Similaire à"Missing" Les données de type ne sont pas faciles à trouver dans le filtrage des valeurs manquantes , Mais ils occupent souvent une plus grande part , Nous pouvons tracer des barres sur ces caractéristiques pour les trouver et les éliminer !
Continuer à visualiser toutes les données .Entrez le code suivant:
df = df[df['artist_top_genre'] != 'Missing']# Supprimer les données sans étiquette de style musical
top = df['artist_top_genre'].value_counts()# Compter le nombre de musiques de différents styles musicaux
plt.figure(figsize=(10,7))#Définir la taille de la toile
sns.barplot(x=top.index,y=top.values)# Tracer un diagramme à barres pour l'étiquetage et la quantité de toutes les données de style musical
plt.xticks(rotation=45)#AjustementX Angle de l'étiquette de l'axe
plt.title('Top genres',color = 'blue')#Définir les propriétés du titre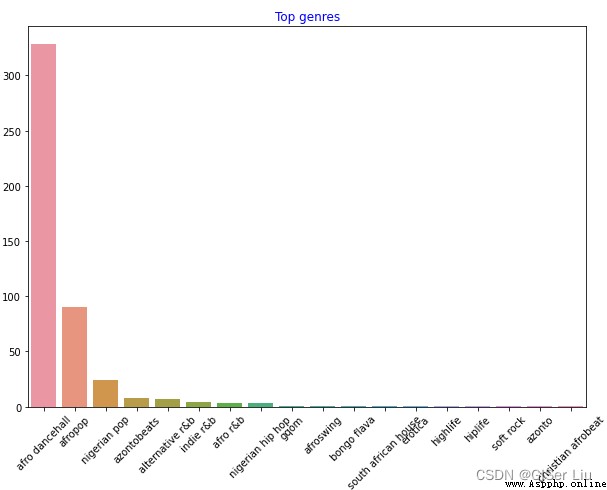
Et ainsi de suite., Les données musicales de différents styles sont clairement affichées .
Pour faciliter nos expériences de regroupement , Nous avons extrait le plus grand nombre de trois types d'échantillons et la popularité était supérieure à 0 L'échantillon est utilisé comme corps de l'ensemble de données pour le regroupement ultérieur .Entrez le code suivant:
df = df[(df['artist_top_genre'] == 'afro dancehall') | (df['artist_top_genre'] == 'afropop') | (df['artist_top_genre'] == 'nigerian pop')]# Échantillons prélevés pour les trois premières quantités
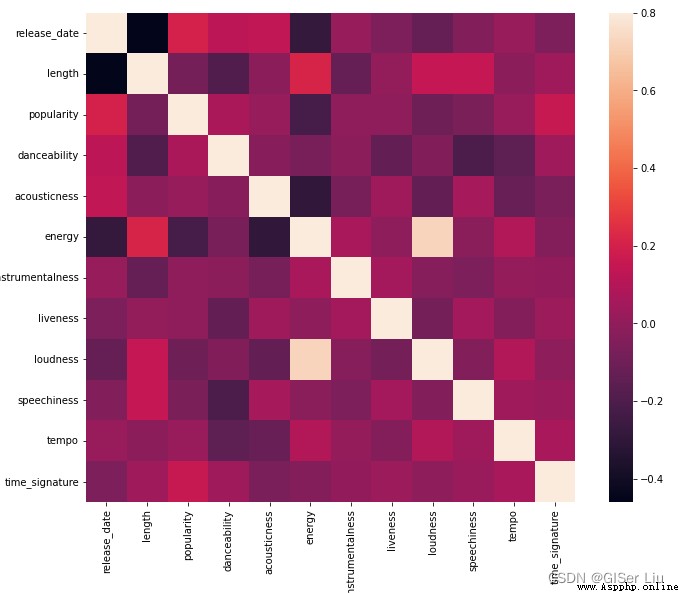
df = df[(df['popularity'] > 0)]# La popularité extraite est supérieure à 0ÉchantillonsFaites un test rapide , Voir quelles caractéristiques des données sont fortement corrélées . Nous calculons le coefficient de corrélation des données sélectionnées , Et présenter la corrélation sous forme de thermographe .Entrez le code suivant :
corrmat = df.corr()# Utilisé pour calculer le coefficient de corrélation
f, ax = plt.subplots(figsize=(12, 9))#subplots() La fonction crée à la fois une toile contenant une zone de sous - Diagramme ,Un autre figure Objets de dessin.
sns.heatmap(corrmat, vmax=.8, square=True)#corrmat La valeur est le coefficient de corrélation ,vmax La plage de cartographie utilisée pour définir la couleur pour la valeur maximale du coefficient de corrélation ,squarePourboolParamètre de type, Si chaque cellule du thermographe est carrée ,Par défautFalse
Exclure la corrélation sur la diagonale de la matrice ( Je suis très lié à moi - même. ),Nous pouvons voirenergyEtloudness Les formes de corrélation des caractéristiques sont plus élevées .Ce n'est pas surprenant, .Parce que la musique bruyante est souvent passionnée .
Votre attention, s'il vous plaît.,La pertinence ne signifie pas la causalité! Nous prouvons qu'ils sont pertinents , Mais il n'y a aucune preuve de causalité entre eux .
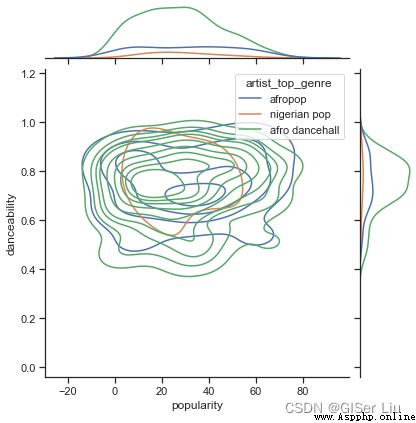
Selon leur popularité , Les trois écoles ont - elles des points de vue différents sur la dansabilité? ? Basé sur la popularité des données musicales XAxe, En fonction de la dansabilité Y Densité du noyau de dessin de l'axe (KDE) Figure affichage de la distribution des données .Entrez le code suivant:
sns.set_theme()#set_style( ) Est utilisé pour définir le thème ,Seaborn Il y a cinq thèmes prédéfinis : darkgrid , whitegrid , dark , white ,Et ticks
g = sns.jointplot(#jointplot Fonction utilisée pour dessiner un diagramme à deux variables
data=df,# Les données sont des données pré - traitées filtrées
x="popularity", y="danceability", hue="artist_top_genre",#Sélectionnez deux variables, Ajouterhue La variable ajoute une couleur conditionnelle au dessin , Et tracer une courbe de densité séparée sur l'axe du bord
kind="kde",#Définir le type de dessin KDE Diagramme de densité des doigts et des noyaux
)
Au stade de l'exploration des données, nous sommes libres d'explorer les relations entre les différentes caractéristiques. , Si vous trouvez ça fastidieux Vous pouvez également utiliser la fonction Batch pour voir rapidement les résultats , Mais c'est moins intéressant. .
Vu de l'image, Les trois genres sont vaguement alignés en termes de popularité et de chorégraphie . Cela signifie que nous aurons plus de mal à le regrouper , La différence entre les données est trop faible .
Nous continuons à créer des diagrammes de dispersion pour ces deux caractéristiques pour voir la distribution des données .Entrez le code suivant:
sns.FacetGrid(df, hue="artist_top_genre", size=5) \
.map(plt.scatter, "popularity", "danceability") \
.add_legend()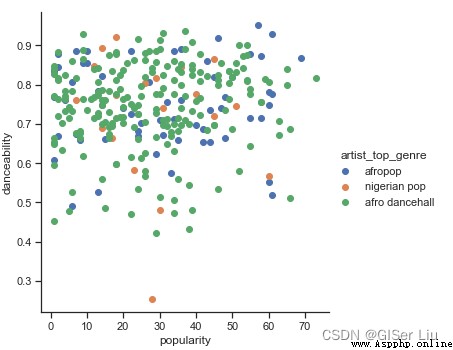
Hum - Hum, A vérifié notre hypothèse ci - dessus , La distribution des données est complexe ,C'est un gâchis..
Pour l'analyse en grappes , Nous pouvons généralement utiliser des diagrammes de dispersion pour afficher visuellement les regroupements de données , Il est très utile de maîtriser ce type de visualisation .
Pour les données confuses , Nous pouvons utiliser des diagrammes de type boîte pour visualiser la distribution des données , Trouver des données anormales et les éliminer . Saisissez le code suivant pour voir la distribution du diagramme de boîte pour différentes caractéristiques numériques :
plt.figure(figsize=(20,20), dpi=200)
plt.subplot(4,3,1)#subplot Fonction divisée 4D'accord3 La zone de toile de la colonne , Le troisième paramètre indique la position de l'image
sns.boxplot(x = 'popularity', data = df)
plt.subplot(4,3,2)
sns.boxplot(x = 'acousticness', data = df)
plt.subplot(4,3,3)
sns.boxplot(x = 'energy', data = df)
plt.subplot(4,3,4)
sns.boxplot(x = 'instrumentalness', data = df)
plt.subplot(4,3,5)
sns.boxplot(x = 'liveness', data = df)
plt.subplot(4,3,6)
sns.boxplot(x = 'loudness', data = df)
plt.subplot(4,3,7)
sns.boxplot(x = 'speechiness', data = df)
plt.subplot(4,3,8)
sns.boxplot(x = 'tempo', data = df)
plt.subplot(4,3,9)
sns.boxplot(x = 'time_signature', data = df)
plt.subplot(4,3,10)
sns.boxplot(x = 'danceability', data = df)
plt.subplot(4,3,11)
sns.boxplot(x = 'length', data = df)
plt.subplot(4,3,12)
sns.boxplot(x = 'release_date', data = df)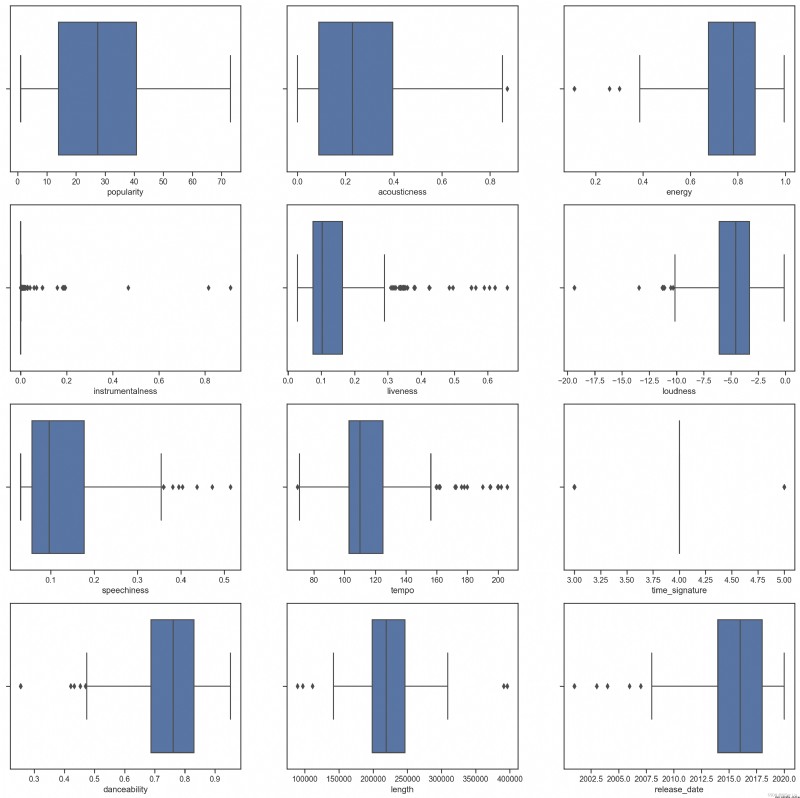
Nous pouvons voir,* Un astérisque indique une valeur anormale , L'emplacement de la boîte indique la zone de distribution des données . Un grand nombre des caractéristiques du graphique sont inégalement réparties , Les caractéristiques de l'échantillon avec des valeurs aberrantes plus élevées ne conviennent pas au regroupement , On peut encore l'éliminer .
Maintenant, Sélectionnez la colonne caractéristique à utiliser pour l'exercice d'analyse en grappes . Ces colonnes caractéristiques doivent avoir une plage similaire ; Les données des colonnes de texte doivent être codées en données numériques. :
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()# Créer un encodeur
X = df.loc[:,('artist_top_genre','popularity','danceability','acousticness','loudness','energy')]#locPourSelection by LabelFonctions, C'est - à - dire obtenir des données par étiquette ; Extraire les données d'étiquette requises comme suit: X Exemple de caractéristiques de formation
y = df['artist_top_genre']# Le genre d'artiste comme Y Vérifier l'étiquette de précision du modèle
X['artist_top_genre'] = le.fit_transform(X['artist_top_genre'])# Étiqueter les données textuelles en format numérique
y = le.transform(y)# Étiqueter les données textuelles en format numérique Maintenant, Nous devons sélectionner des grappes (Cluster)Nombre. On sait qu'on peut en sortir. 3 Types de chansons ,Nous allons doncnclustersAssigner comme3,Entrez le code suivant:
from sklearn.cluster import KMeans
nclusters = 3 # Initialiser le nombre de centroïdes , Parce qu'on veut diviser 3 Type de musique moyenne , Il est donc attribué comme suit: 3
seed = 0 # Sélectionnez une graine d'initialisation aléatoire
km = KMeans(n_clusters=nclusters, random_state=seed)#Unrandom_stateNombre aléatoire de graines correspondant à une initialisation aléatoire d'un centroïde. Si vous ne spécifiez pas de graines aléatoires ,Et sklearnDansKMeansIl n'y a pas qu'un seul mode aléatoire pour lancer les résultats
km.fit(X)#C'est exact.KmeansModèle pour la formation
#Prévoir à l'aide d'un modèle bien formé
y_cluster_kmeans = km.predict(X)
y_cluster_kmeans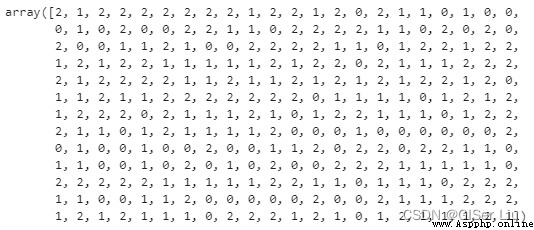
Le tableau est K-meansRésultats prévus du modèle, Où le nombre est le résultat du regroupement pour chaque ligne d'échantillon (0、1 Ou 2).
Nous utilisons ensuite les résultats de cette prévision pour calculer “Facteur de profil”,Entrez le code suivant:
from sklearn import metrics
score = metrics.silhouette_score(X, y_cluster_kmeans)# metrics.silhouette_score Fonction utilisée pour calculer le coefficient de profil
score0 Facteur de profil(Silhouette Coefficient), C'est une façon d'évaluer l'effet de regroupement .
La meilleure valeur est1,La différence maximale est-1.Approche0 La valeur de représente un Cluster qui se chevauche . Une valeur négative indique généralement que l'échantillon a été attribué au mauvais regroupement , Parce que différents Clusters sont plus similaires Oui..
1 Formule du coefficient de profil Pour:S=(b-a)/max(a,b),Parmi euxa Est la moyenne de la distance entre un seul échantillon et tous les échantillons du même groupe ,b Est la moyenne de tous les échantillons d'un seul échantillon à différents groupes .
Le coefficient de profil représente la distance minimale entre les échantillons du même type , Mesure de la distance maximale entre les échantillons de différentes classes
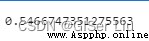
Notre modèle Le facteur de profil est 0.54, Cela indique que nos données ne sont pas particulièrement adaptées à ce type de regroupement. , Mais ça n'affecte pas notre enseignement. , Il y a toujours toutes sortes de problèmes dans la pratique . On va s'entraîner :
Importer des bibliothèques tierces, Ajuster les paramètres pour un nouveau cycle de formation , Nous effectuons le traitement par lots du nombre de grappes , Voir combien de valeurs de paramètres fonctionnent le mieux :
from sklearn.cluster import KMeans
wcss = []
for i in range(1, 11):
kmeans = KMeans(n_clusters = i, init = 'k-means++', random_state = 42)
kmeans.fit(X)
wcss.append(kmeans.inertia_)
Description des paramètres:
0 range():Ici.for La boucle est pour itérer le nombre de tours d'entraînement , Ici, nous mettons en place l'entraînement 10Rotation
1 random_state: Déterminer la génération aléatoire de centroïdes initialisés .
2 wcss:Pour le stockage“ Somme des carrés dans le cluster ” Mesure de la distance moyenne carrée entre tous les points du cluster et le Centre de masse du cluster .
3 inertia_:K-Means L'algorithme tente de sélectionner le Centre de masse pour minimiser “Inertie”,“ Mesure du regroupement cohérent interne ”. Cette valeur est ajoutée à chaque itération wcss Dans la variable. Ce paramètre d'évaluation représente la somme de la distance entre un point d'un Cluster et un Cluster , Bien que cette méthode présente la plus petite finesse de regroupement dans l'évaluation des paramètres
4 k-means++:InScikit-learnMoyenne,Vous pouvez utiliser'k-means++'Optimisation,C'est“Initialiser le Centre de masse(En général) Loin l'un de l'autre , Peut - être mieux que l'initialisation aléatoire .
Nous utilisonslineplot La fonction dessine avec la catégorie (Cluster)Augmentation du volume,inertia_ Diagramme linéaire de la tendance à la variation des valeurs des paramètres .
plt.figure(figsize=(10,5))
sns.lineplot(range(1, 11), wcss,marker='o',color='red')
plt.title('Elbow')
plt.xlabel('Number of clusters')
plt.ylabel('WCSS')
plt.show()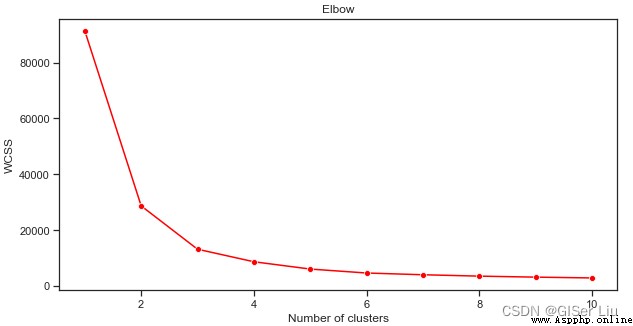
Comme le montre cette image,,K Algorithme de moyenne lorsque le nombre de grappes est 3Heure,Leinertia_ Les paramètres fonctionnent bien ,Nous avons le choix3Classe ou4 Classe pour la prédiction quadratique des ensembles de données , Évaluer sa précision .
Encore une fois, essayez le processus de formation au modèle et d'évaluation de la précision , Ce réglage 3 Regroupement des cycles , Et afficher les résultats du regroupement sous forme de diagramme de dispersion :
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters = 3)# Définir le cluster pour le cluster (Catégorie)Nombre
kmeans.fit(X)#Former le modèle
labels = kmeans.predict(X)#Prévisions de sortie
plt.scatter(df['popularity'],df['danceability'],c = labels)# Popularité XAxe, La chorégraphie est YAxe, Étiquette pour dessiner un diagramme de dispersion pour la catégorie
plt.xlabel('popularity')
plt.ylabel('danceability')
plt.show()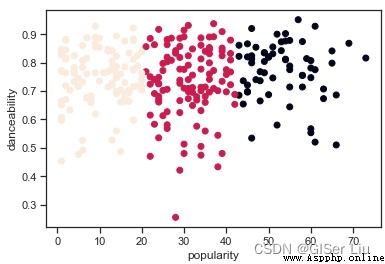
Oui.?
Entrez le code suivant pour vérifier l'exactitude du modèle :
labels = kmeans.labels_# Extraire les valeurs prédictives des échantillons du modèle labels
correct_labels = sum(y == labels)# Les statistiques prédisent les valeurs correctes
print("Result: %d out of %d samples were correctly labeled." % (correct_labels, y.size))
print('Accuracy score: {0:0.2f}'. format(correct_labels/float(y.size)))
Comme vous pouvez le voir,, Bien que nous ayons ajusté les paramètres ;De tous les échantillons,Seulement38% L'échantillon a été prédit avec succès ,En d'autres termes,,La nôtre.K-means Le modèle n'est pas bon. .🤨 Mais la plupart du temps, c'est comme ça. , Je vous ai donné la méthode d'analyse. , Vous pouvez peut - être choisir d'autres caractéristiques ou d'autres modèles de regroupement pour améliorer encore la performance du modèle. .
Dans cet article,On a apprisK-meansLes principes mathématiques de l'algorithme, L'auteur prend l'ensemble de données musicales du Nigeria comme exemple . Découvrez comment visualiser les caractéristiques sous - jacentes des données . Enfin, la formation K-meansLe modèle a été évalué.

Si mon article vous aide,Trois compagnies+L'attention est le plus grand encouragement à ma création!
“Tous les articles de ce site sont originaux,Bienvenue à la réimpression,Veuillez indiquer la source de l'article:https://blog.csdn.net/qq_45590504/category_11752103.html?spm=1001.2014.3001.5482Baidu et toutes sortes de stations de collecte ne sont pas fiables,Recherche Veuillez identifier soigneusement.Les articles techniques sont généralement limités dans le temps,J'ai l'habitude de modifier et de mettre à jour mon blog de temps à autre,Consultez donc la source pour la dernière version de cet article.”
Série d'articles recommandés
Série d'apprentissage automatique0 La machine apprend la pensée _GISer LiuBlog de-CSDNBlogs
Série d'apprentissage automatique1 Histoire de l'apprentissage automatique _GISer LiuBlog de-CSDNBlogs
Série d'apprentissage automatique2 Équité de l'apprentissage automatique_GISer LiuBlog de-CSDNBlogs_ Equitable Machine Learning
Série d'apprentissage automatique3 Processus d'apprentissage automatique_GISer LiuBlog de-CSDNBlogs
Série d'apprentissage automatique4 UtiliserPythonCréationScikit-LearnModèle de régression_GISer LiuBlog de-CSDNBlogs
Série d'apprentissage automatique5 UtilisationScikit-learnConstruire un modèle de régression: Préparation et visualisation des données (Tutoriel de baby - sitting)_GISer LiuBlog de-CSDNBlogs
Série d'apprentissage automatique6 UtiliserScikit-learnConstruire un modèle de régression:Régression linéaire simple、 Régression polynomiale et régression linéaire multiple _GISer LiuBlog de-CSDNBlogs_Régression polynomiale multipleSérie d'apprentissage automatique7 Basé surPythonDeScikit-learn Modèle de régression logique de la construction de la bibliothèque _GISer LiuBlog de-CSDNBlogsSérie d'apprentissage automatique8 Basé surPythonConstruireWeb Appliquer pour utiliser le modèle d'apprentissage automatique _GISer LiuBlog de-CSDNBlogs
Lire l'ensemble du processus de classification de l'apprentissage automatique _GISer LiuBlog de-CSDNBlogs
Basé surPython Construire l'apprentissage automatique WebApplication_GISer LiuBlog de-CSDNBlogs