多線程簡單理解就是:一個CPU,也就是單核,將時間切成一片一片的,CPU輪轉著去處理一件一件的事情,到了規定的時間片就處理下一件事情。
# coding:utf-8
# 導入threading包
import threading
if __name__ == "__main__":
print("當前活躍線程的數量", threading.active_count())
print("將當前所有線程的具體信息展示出來", threading.enumerate())
print("當前的線程的信息展示", threading.current_thread())
效果圖: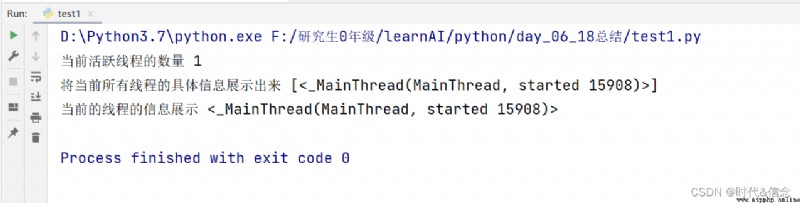
# coding:utf-8
import threading
import time
def job1():
# 讓這個線程多執行幾秒
time.sleep(5)
print("the number of T1 is %s" % threading.current_thread())
if __name__ == "__main__":
# 創建一個新的線程
new_thread = threading.Thread(target=job1, name="T1")
# 啟動新線程
new_thread.start()
print("當前線程數量為", threading.active_count())
print("所有線程的具體信息", threading.enumerate())
print("當前線程具體信息", threading.current_thread())
效果圖: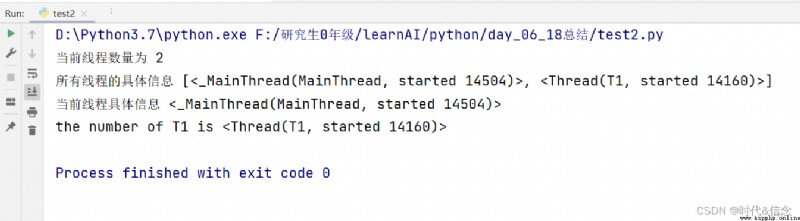
(1)預想的是,執行完線程1,然後輸出All done…
“理想很豐滿,現實卻不是這樣的”
# coding:utf-8
import threading
import time
def job1():
print("T1 start")
for i in range(5):
time.sleep(1)
print(i)
print("T1 finish")
def main():
# 新創建一個線程
new_thread = threading.Thread(target=job1, name="T1")
# 啟動新線程
new_thread.start()
print("All done...")
if __name__ == "__main__":
main()
效果圖:
(2)為了達到我們的預期,我們使用join函數,將T1線程進行阻塞。join函數進行阻塞是什麼意思?就是哪個線程使用了join函數,當這個線程正在執行時,在他之後的線程程序不能執行,得等這個被阻塞的線程全部執行完畢之後,方可執行!
# coding:utf-8
import threading
import time
def job1():
print("T1 start")
for i in range(5):
time.sleep(1)
print(i)
print("T1 finish")
def main():
# 新創建一個線程
new_thread = threading.Thread(target=job1, name="T1")
# 啟動新線程
new_thread.start()
# 阻塞這個T1線程
new_thread.join()
print("All done...")
if __name__ == "__main__":
main()
效果圖:
線程的執行結果,無法通過return進行返回,使用Queue存儲。
# coding:utf-8
import threading
from queue import Queue
""" Queue的使用 """
def job(l, q):
for i in range(len(l)):
l[i] = l[i] ** 2
q.put(l)
def multithreading():
# 創建隊列
q = Queue()
# 線程列表
threads = []
# 二維列表
data = [[1, 2, 3], [4, 5, 6], [7, 8, 9], [6, 6, 6]]
for i in range(4):
t = threading.Thread(target=job, args=(data[i], q))
t.start()
threads.append(t)
# 對所有線程進行阻塞
for thread in threads:
thread.join()
results = []
# 將新隊列中的每個元素挨個放到結果列表中
for _ in range(4):
results.append(q.get())
print(results)
if __name__ == "__main__":
multithreading()
效果圖:
當同時啟動多個線程時,各個線程之間會互相搶占計算資源,會造成程序混亂。
舉個栗子:
當我們在選課系統選課時,當前籃球課還有2個名額,我們三個人去選課。
選課順序為stu1 stu2 stu3,應該依次打印他們三個的選課過程,但是現實情況卻是:
# coding:utf-8
import threading
import time
def stu1():
print("stu1開始選課")
global course
if course > 0:
course -= 1
time.sleep(2)
print("stu1選課成功,現在籃球課所剩名額為%d" % course)
else:
time.sleep(2)
print("stu1選課失敗,籃球課名額為0,請選擇其他課程")
def stu2():
print("stu2開始選課")
global course
if course > 0:
course -= 1
time.sleep(2)
print("stu2選課成功,現在籃球課所剩名額為%d" % course)
else:
time.sleep(2)
print("stu2選課失敗,籃球課名額為0,請選擇其他課程")
def stu3():
print("stu3開始選課")
global course
if course > 0:
course -= 1
time.sleep(2)
print("stu3選課成功")
print("籃球課所剩名額為%d" %course)
else:
time.sleep(2)
print("stu3選課失敗,籃球課名額為0,請選擇其他課程")
if __name__ == "__main__":
# 籃球課名額
course = 2
T1 = threading.Thread(target=stu1, name="T1")
T2 = threading.Thread(target=stu2, name="T2")
T3 = threading.Thread(target=stu3, name="T3")
T1.start()
T2.start()
T3.start()
效果圖: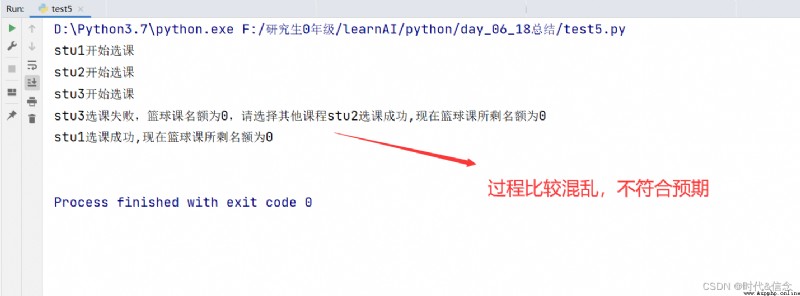
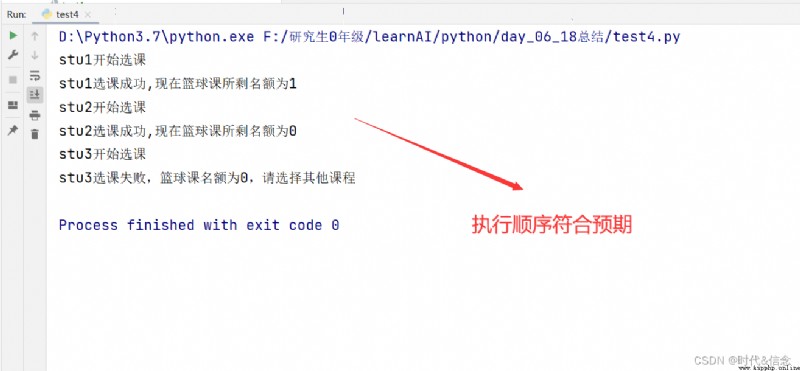
為了解決這種情況,我們使用lock線程同步鎖,在線程並發執行時,保證每個線程執行的原子性。有效防止了共享統一數據時,線程並發執行的混亂。改進的代碼如下:
# coding:utf-8
import threading
import time
def stu1():
global lock
lock.acquire()
print("stu1開始選課")
global course
if course > 0:
course -= 1
time.sleep(2)
print("stu1選課成功,現在籃球課所剩名額為%d" % course)
else:
time.sleep(2)
print("stu1選課失敗,籃球課名額為0,請選擇其他課程")
lock.release()
def stu2():
global lock
lock.acquire()
print("stu2開始選課")
global course
if course > 0:
course -= 1
print("stu2選課成功,現在籃球課所剩名額為%d" % course)
else:
time.sleep(1)
print("stu2選課失敗,籃球課名額為0,請選擇其他課程")
lock.release()
def stu3():
global lock
lock.acquire()
print("stu3開始選課")
global course
if course > 0:
course -= 1
time.sleep(1)
print("stu3選課成功,現在籃球課所剩名額為%d" % course)
else:
time.sleep(1)
print("stu3選課失敗,籃球課名額為0,請選擇其他課程")
lock.release()
if __name__ == "__main__":
# 籃球課名額
course = 2
# 創建同步鎖
lock = threading.Lock()
T1 = threading.Thread(target=stu1, name="T1")
T2 = threading.Thread(target=stu2, name="T2")
T3 = threading.Thread(target=stu3, name="T3")
T1.start()
T2.start()
T3.start()
效果圖: