There are screenshots to be submitted for the questions in the student's test paper , There are also documents to be submitted , In order to facilitate the students' examination , Allow separate intersection or embedding Word Submitted in , Then how to sort out the students' answers afterwards ? It is more convenient to submit separately , Directly scan the file name to match the name and put it into the specified folder . But embedded in Word How to extract the pictures and files in ?
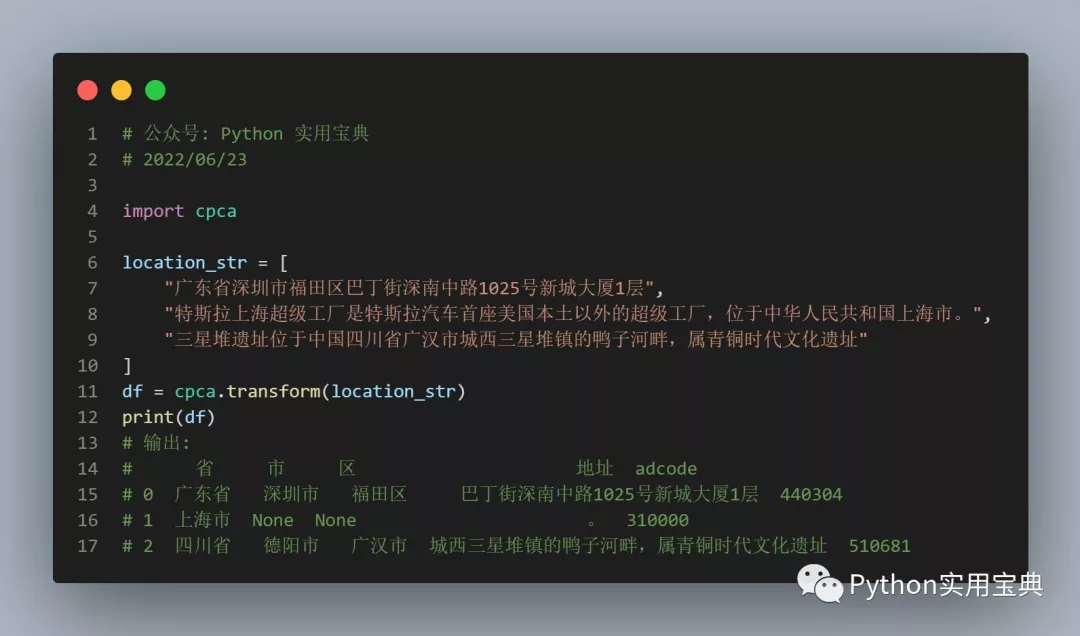
There are the following needs : Extract one Word All the pictures in the document (png、jpg) And embedded files ( Any format ) Put it in the specified folder .
solve
docx It's a compressed package , The decompressed image is usually placed in the document name .docx\word\media\ Under the table of contents :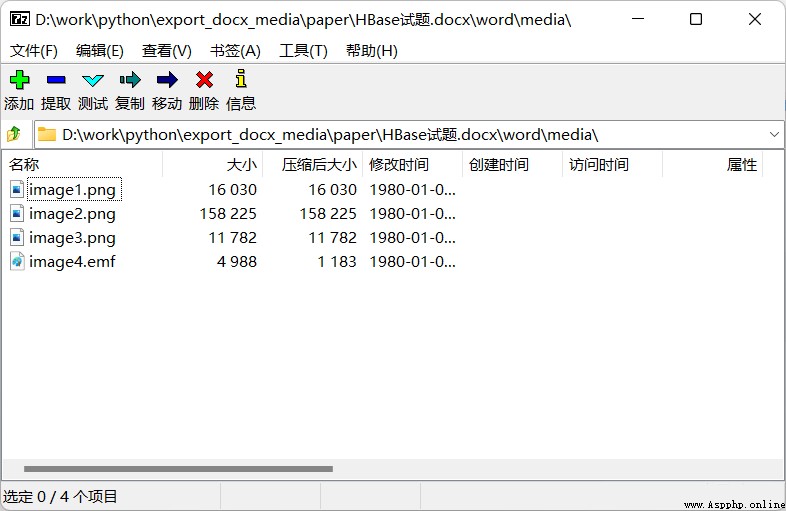
Embedded files are usually placed in the document name .docx\word\embeddings\ Under the table of contents :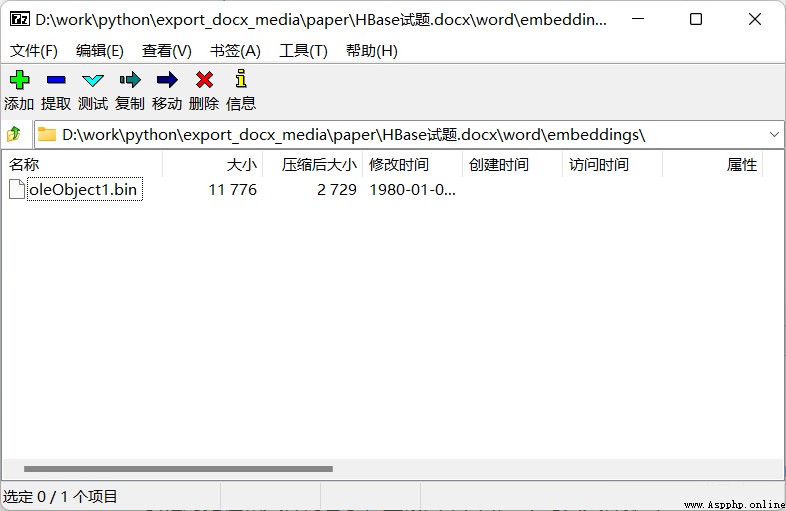
After asking Du Niang , I found it easy to extract pictures , Use it directly docx In the library Document.part.rels{k:v.target_ref} Find the relative path of the file , use Document.part.rels{k:v.target_part.blob} Read file contents . Simply judge whether the path and file suffix are what we need media Under the png Document and embeddings Under the bin file , If yes, write to the new file :
To extract the image
install python-docx library
pip install python-docx
extract
import os
from docx import Document # pip install python-docx
is_debug = True
if __name__ == '__main__':
# Need to export Word Document path
# Python Learning and communication base 279199867
target_file = r'paper\HBase test questions .docx'
# The directory where the exported file is located
output_dir = r'paper\output'
# load Word file
doc = Document(target_file)
# Traverse Word All the files in the package
dict_rel = doc.part.rels
# r_id: Document id ,rel: File object
for r_id, rel in dict_rel.items():
if not ( # If the file is not in media perhaps embeddings Medium , Just skip
str(rel.target_ref).startswith('media')
or str(rel.target_ref).startswith('embeddings')
):
continue
# If the file is not the suffix we want , Also skip directly
file_suffix = str(rel.target_ref).split('.')[-1:][0]
if file_suffix.lower() not in ['png', 'jpg', 'bin']:
continue
# If the output directory does not exist , establish
if not os.path.exists(output_dir):
os.makedirs(output_dir)
# Build the name and path of the export file
file_name = r_id + '_' + str(rel.target_ref).replace('/', '_')
file_path = os.path.join(output_dir,file_name)
# Write binary data to a file in a new location
with open(file_path, "wb") as f:
f.write(rel.target_part.blob)
# Print the results
if is_debug:
print(' Export file succeeded :', file_name)
Running results :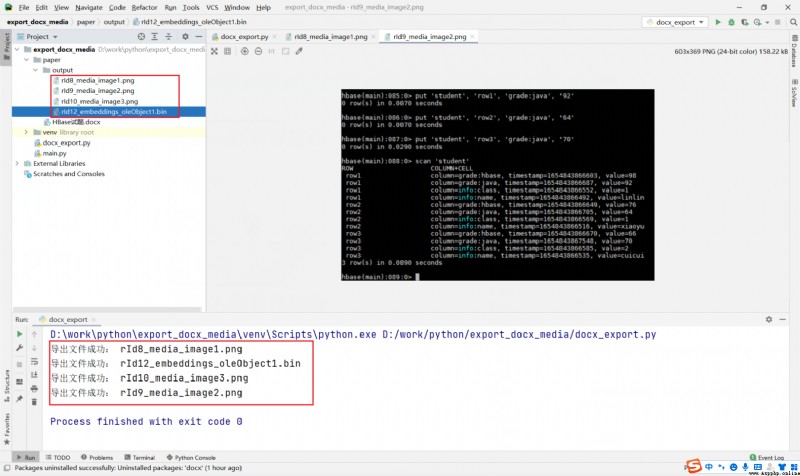
You can see , Pictures can be exported normally , But the students embed JAVA The file was not exported , In other words, the export is bin file , Not completely exported .
Extract embedded files
Ask Du Niang again and find , In fact, this is also zip Compressed package , But it can't be extracted directly , It has a more professional name , It's called ole file , Our previous doc、xls、ppt Wait till you don't bring it x All the ancient documents are in this format . So how to extract the file ? Du Niang told me that there was a man named oletools Projects can , So I downloaded it and analyzed it , It turns out that it can !
oletools Project address :https://github.com/decalage2/oletools
perhaps gitee To the address of someone else :https://gitee.com/yunqimg/oletools
I am using gitee Previous editions , because github Cannot be opened QwQ
Introduced by relevant documents , Under the project of oletools-master\oletools\oleobj.py You can extract this bin Suffix ole file , Just give it a try , stay oleobj.py Open the command line in the directory , Take the just extracted rId12_embeddings_oleObject1.bin File copy to oleobj.py In the directory , Execute the following command :
Be careful : Before that, I performed the installation oletools The order of , If you do not install it, you may make an error :pip install oletools, Or say oleobj.py rely on olefile:pip install olefile, In the installation oletools By the way olefile.
python oleobj.py rId12_embeddings_oleObject1.bin
Successfully exported
Microsoft Windows [ edition 10.0.22000.708]
(c) Microsoft Corporation. All rights reserved .
D:\Minuy\Downloads\oletools-master\oletools-master\oletools>python oleobj.py rId12_embeddings_oleObject1.bin
oleobj 0.56 - http://decalage.info/oletools
THIS IS WORK IN PROGRESS - Check updates regularly!
Please report any issue at https://github.com/decalage2/oletools/issues
-------------------------------------------------------------------------------
File: 'rId12_embeddings_oleObject1.bin'
extract file embedded in OLE object from stream '\x01Ole10Native':
Parsing OLE Package
Filename = "Boos.java"
Source path = "D:\111\´ó20´óÊý¾Ý Àî¾üÁé\Boos.java"
Temp path = "C:\Users\ADMINI~1\AppData\Local\Temp\Boos.java"
saving to file rId12_embeddings_oleObject1.bin_Boos.java
D:\Minuy\Downloads\oletools-master\oletools-master\oletools>
The exported files can also be accessed normally :
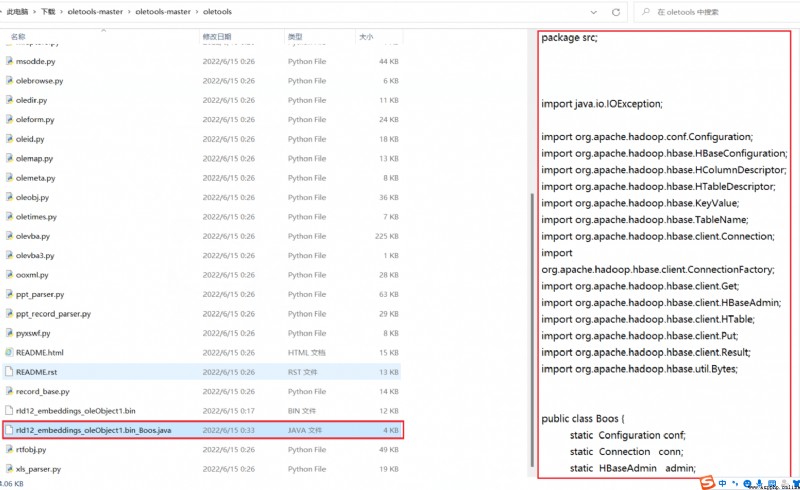
So the oletools Copy the directory to the project , I'm going to modify it a little bit oleobj.py Can make my code call it , stay oleobj.py Add the following code to :
def export_main(ole_files, output_dir, log_leve=DEFAULT_LOG_LEVEL):
ensure_stdout_handles_unicode()
logging.basicConfig(level=LOG_LEVELS[log_leve], stream=sys.stdout,
format='%(levelname)-8s %(message)s')
# Enable the log module
log.setLevel(logging.NOTSET)
any_err_stream = False
any_err_dumping = False
any_did_dump = False
for container, filename, data \
in xglob.iter_files(ole_files,
recursive=False,
zip_password=None,
zip_fname='*'):
if container and filename.endswith('/'):
continue
# Output folder
err_stream, err_dumping, did_dump = \
process_file(filename, data, output_dir)
any_err_stream |= err_stream
any_err_dumping |= err_dumping
any_did_dump |= did_dump
return_val = RETURN_NO_DUMP
if any_did_dump:
return_val += RETURN_DID_DUMP
if any_err_stream:
return_val += RETURN_ERR_STREAM
if any_err_dumping:
return_val += RETURN_ERR_DUMP
return return_val
def export_ole_file(ole_files, output_dir, debug=False):
debug_leve = 'critical'
if debug:
debug_leve = 'info'
# export
result = export_main(
ole_files,
output_dir,
debug_leve
)
if result and debug:
print(' export ole File error ', ole_files)
Add the following call to the code that extracts the file :
if str(rel.target_ref).startswith('embeddings'):
# Unzip the embedded file
export_ole_file([file_path], output_dir)
Run again
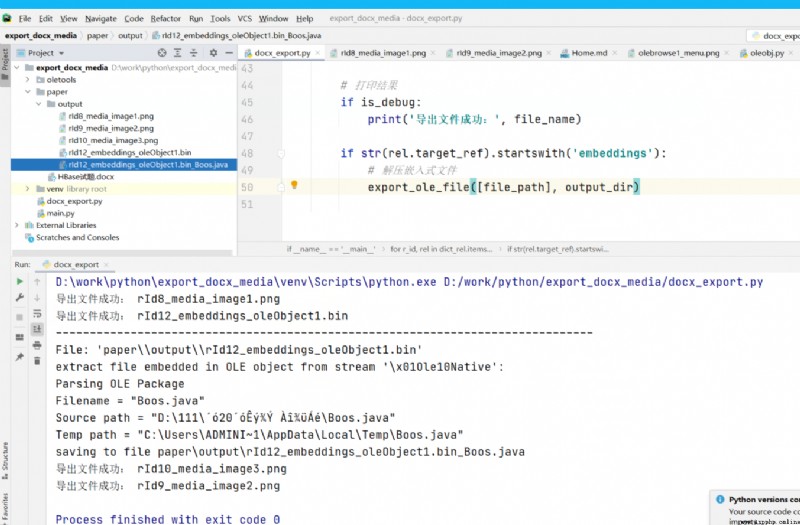
Successfully exported embedded into Word Documents in !
Solve the problem successfully ~
Brothers, go and have a try !