Reference article https://blog.csdn.net/c406495762/article/details/75172850
Personal feeling KNN Algorithm (K-NearestNeighbor) An extremely simple and crude classification method , For example , For example, you want to know if a person likes playing games , We can observe whether his closest friends like playing games , If most people like playing games , It can be inferred that this person also likes playing games .KNN It's based on this “ Birds of a feather flock together , Birds of a feather flock together ” Simple and crude ideas to classify .
Given a training data set , Then give a data that needs to be predicted , And then in Search in the training data set k( This is KNN Of K The origin of ) Which are closest to the data to be predicted ( Usually we can take Euclidean distance as the measure of distance ) The data of . Finally, select k The most frequent categories in the data As the classification of data to be predicted .
Euclidean distance :
def KNN(inpudata,data_matrix,label_matrix,k):
''' :param inpudata: Data to be predicted :param data_matrix: Data sets :param label_matrix: Tags for data sets :param k: Number of nearest neighbors to find :return: The result of the classification '''
datalen=data_matrix.shape[0]
inpudata=np.tile(inpudata,(datalen,1))# Helen's dating example turns data into (datalen,3)
sub=inpudata-data_matrix
sq=sub**2
sum=sq.sum(axis=1)# Sum in row direction
distance=sum*0.5
sorteddisarg=distance.argsort()# Index sorted from small to large by distance
classcount={
}# Record the number of occurrences
for i in range(k):
vote=label_matrix[sorteddisarg[i]]# The first i A category of elements
classcount[vote]=classcount.get(vote,0)+1 # to vote Add one to the value of this key , If this key doesn't exist , Create and set default values 0
# key=operator.itemgetter(1) Sort by dictionary value , by 0 Sort by dictionary key
# reverse Sort dictionary in descending order
result=sorted(classcount.items(),key=operator.itemgetter(1),reverse=True)
return result[0][0] # Returns the result of the classification
The following is an example of Helen's dating KNN Algorithm
Helen date data set download
The total data is 1000 That's ok
features
1. Annual mileage
2. Play game time
3. Litres of ice cream consumed per week
label
1.didntLike
2.smallDoses
3.largeDoses
The visualization results of the dataset are shown below :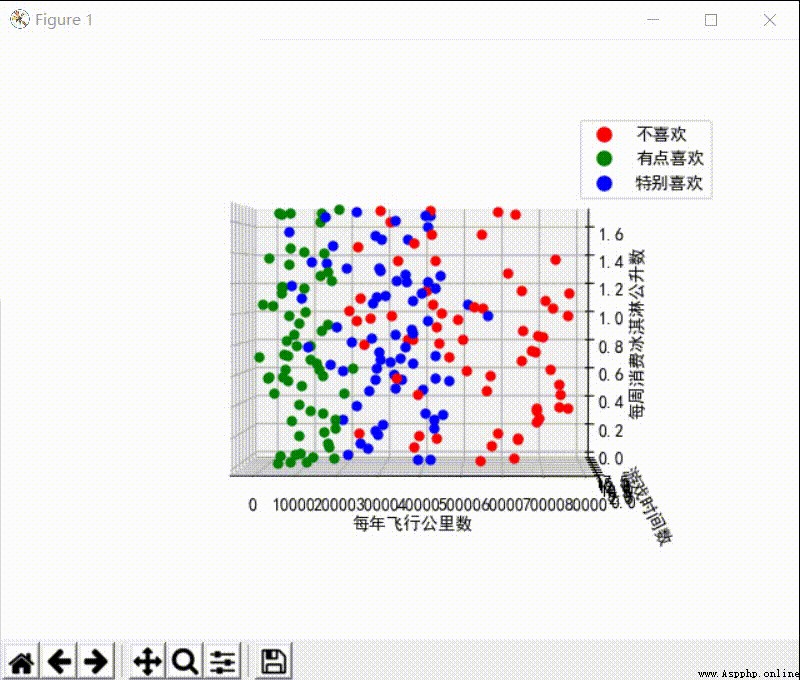
Visible from above , Helen likes people who have the right number of kilometers to fly every year ( In about 40000 about ), And a man with a certain amount of playing time , But I don't like the man who always flies outside .
Let's start KNN The accuracy of the algorithm is calculated :
We take the first tenth of the data set as the test set , The last nine tenths are the training set , Check the accuracy of classification :
It is suggested to normalize the data in the implementation process , Because in this dataset , Compared to game time and weekly ice cream consumption liters , The number of kilometers flown by the aircraft is the largest in value , Its change has a greater impact on the calculation of distance , It is easier to affect the final classification results . But in Helen's dating case, we think three characteristics are equally important , Therefore, we need to limit the value range of all features , Let the three features have the same impact on the final classification results .
After testing, it is found that the accuracy of the test data before and after normalization is 80%, The latter is 96%
Before normalization : After normalization :

Finally, we give 3 Group data and then use KNN To make predictions :
Predicted results :
advantage :1. Only find the nearest point to be predicted K It's worth , Insensitive to outliers
2. It is easy to understand and implement
shortcoming :1. Large amount of computation , High memory overhead
Click here to view