一、數據庫封裝
1.1數據庫基本配置
1.2 編寫單例模式注解
1.3 構建連接池
1.4 封裝Python操作MYSQL的代碼
二、連接池測試
場景一:同一個實例,執行2次sql
場景二:依次創建2個實例,各自執行sql
場景三:啟動2個線程,但是線程在創建連接池實例時,有時間間隔
場景四:啟動2個線程,線程在創建連接池實例時,沒有時間間隔
前言:
線程安全問題:當2個線程同時用到線程池時,會同時創建2個線程池。如果多個線程,錯開用到線程池,就只會創建一個線程池,會共用一個線程池。我用的注解方式的單例模式,感覺就是這個注解的單例方式,解決了多線程問題,但是沒解決線程安全問題,需要優化這個單例模式。
主要通過 PooledDB 模塊實現。
一、數據庫封裝1.1數據庫基本配置db_config.py
# -*- coding: UTF-8 -*-import pymysql# 數據庫信息DB_TEST_HOST = "127.0.0.1"DB_TEST_PORT = 3308DB_TEST_DBNAME = "bt"DB_TEST_USER = "root"DB_TEST_PASSWORD = "123456"# 數據庫連接編碼DB_CHARSET = "utf8"# mincached : 啟動時開啟的閒置連接數量(缺省值 0 開始時不創建連接)DB_MIN_CACHED = 5# maxcached : 連接池中允許的閒置的最多連接數量(缺省值 0 代表不閒置連接池大小)DB_MAX_CACHED = 0# maxshared : 共享連接數允許的最大數量(缺省值 0 代表所有連接都是專用的)如果達到了最大數量,被請求為共享的連接將會被共享使用DB_MAX_SHARED = 5# maxconnecyions : 創建連接池的最大數量(缺省值 0 代表不限制)DB_MAX_CONNECYIONS = 300# blocking : 設置在連接池達到最大數量時的行為(缺省值 0 或 False 代表返回一個錯誤<toMany......> 其他代表阻塞直到連接數減少,連接被分配)DB_BLOCKING = True# maxusage : 單個連接的最大允許復用次數(缺省值 0 或 False 代表不限制的復用).當達到最大數時,連接會自動重新連接(關閉和重新打開)DB_MAX_USAGE = 0# setsession : 一個可選的SQL命令列表用於准備每個會話,如["set datestyle to german", ...]DB_SET_SESSION = None# creator : 使用連接數據庫的模塊DB_CREATOR = pymysql設置連接池最大最小為5個。則啟動連接池時,就會建立5個連接。
1.2 編寫單例模式注解singleton.py
#單例模式函數,用來修飾類def singleton(cls,*args,**kw): instances = {} def _singleton(): if cls not in instances: instances[cls] = cls(*args,**kw) return instances[cls] return _singleton1.3 構建連接池db_dbutils_init.py
from dbutils.pooled_db import PooledDBimport db_config as config# import randomfrom singleton import singleton"""@功能:創建數據庫連接池"""class MyConnectionPool(object): # 私有屬性 # 能通過對象直接訪問,但是可以在本類內部訪問; __pool = None # def __init__(self): # self.conn = self.__getConn() # self.cursor = self.conn.cursor() # 創建數據庫連接conn和游標cursor def __enter__(self): self.conn = self.__getconn() self.cursor = self.conn.cursor() # 創建數據庫連接池 def __getconn(self): if self.__pool is None: # i = random.randint(1, 100) # print("創建線程池的數量"+str(i)) self.__pool = PooledDB( creator=config.DB_CREATOR, mincached=config.DB_MIN_CACHED, maxcached=config.DB_MAX_CACHED, maxshared=config.DB_MAX_SHARED, maxconnections=config.DB_MAX_CONNECYIONS, blocking=config.DB_BLOCKING, maxusage=config.DB_MAX_USAGE, setsession=config.DB_SET_SESSION, host=config.DB_TEST_HOST, port=config.DB_TEST_PORT, user=config.DB_TEST_USER, passwd=config.DB_TEST_PASSWORD, db=config.DB_TEST_DBNAME, use_unicode=False, charset=config.DB_CHARSET ) return self.__pool.connection() # 釋放連接池資源 def __exit__(self, exc_type, exc_val, exc_tb): self.cursor.close() self.conn.close() # 關閉連接歸還給鏈接池 # def close(self): # self.cursor.close() # self.conn.close() # 從連接池中取出一個連接 def getconn(self): conn = self.__getconn() cursor = conn.cursor() return cursor, conn# 獲取連接池,實例化@singletondef get_my_connection(): return MyConnectionPool()1.4 封裝Python操作MYSQL的代碼mysqlhelper.py
import timefrom db_dbutils_init import get_my_connection"""執行語句查詢有結果返回結果沒有返回0;增/刪/改返回變更數據條數,沒有返回0"""class MySqLHelper(object): def __init__(self): self.db = get_my_connection() # 從數據池中獲取連接 # # def __new__(cls, *args, **kwargs): # if not hasattr(cls, 'inst'): # 單例 # cls.inst = super(MySqLHelper, cls).__new__(cls, *args, **kwargs) # return cls.inst # 封裝執行命令 def execute(self, sql, param=None, autoclose=False): """ 【主要判斷是否有參數和是否執行完就釋放連接】 :param sql: 字符串類型,sql語句 :param param: sql語句中要替換的參數"select %s from tab where id=%s" 其中的%s就是參數 :param autoclose: 是否關閉連接 :return: 返回連接conn和游標cursor """ cursor, conn = self.db.getconn() # 從連接池獲取連接 count = 0 try: # count : 為改變的數據條數 if param: count = cursor.execute(sql, param) else: count = cursor.execute(sql) conn.commit() if autoclose: self.close(cursor, conn) except Exception as e: pass return cursor, conn, count # 釋放連接 def close(self, cursor, conn): """釋放連接歸還給連接池""" cursor.close() conn.close() # 查詢所有 def selectall(self, sql, param=None): cursor = None conn = None count = None try: cursor, conn, count = self.execute(sql, param) res = cursor.fetchall() return res except Exception as e: print(e) self.close(cursor, conn) return count # 查詢單條 def selectone(self, sql, param=None): cursor = None conn = None count = None try: cursor, conn, count = self.execute(sql, param) res = cursor.fetchone() self.close(cursor, conn) return res except Exception as e: print("error_msg:", e.args) self.close(cursor, conn) return count # 增加 def insertone(self, sql, param): cursor = None conn = None count = None try: cursor, conn, count = self.execute(sql, param) # _id = cursor.lastrowid() # 獲取當前插入數據的主鍵id,該id應該為自動生成為好 conn.commit() self.close(cursor, conn) return count except Exception as e: print(e) conn.rollback() self.close(cursor, conn) return count # 增加多行 def insertmany(self, sql, param): """ :param sql: :param param: 必須是元組或列表[(),()]或((),()) :return: """ cursor, conn, count = self.db.getconn() try: cursor.executemany(sql, param) conn.commit() return count except Exception as e: print(e) conn.rollback() self.close(cursor, conn) return count # 刪除 def delete(self, sql, param=None): cursor = None conn = None count = None try: cursor, conn, count = self.execute(sql, param) self.close(cursor, conn) return count except Exception as e: print(e) conn.rollback() self.close(cursor, conn) return count # 更新 def update(self, sql, param=None): cursor = None conn = None count = None try: cursor, conn, count = self.execute(sql, param) conn.commit() self.close(cursor, conn) return count except Exception as e: print(e) conn.rollback() self.close(cursor, conn) return count# if __name__ == '__main__':# db = MySqLHelper()# sql = "SELECT SLEEP(10)"# db.execute(sql)# time.sleep(20) # TODO 查詢單條 # sql1 = 'select * from userinfo where name=%s' # args = 'python' # ret = db.selectone(sql=sql1, param=args) # print(ret) # (None, b'python', b'123456', b'0') # TODO 增加單條 # sql2 = 'insert into hotel_urls(cname,hname,cid,hid,url) values(%s,%s,%s,%s,%s)' # ret = db.insertone(sql2, ('1', '2', '1', '2', '2')) # print(ret) # TODO 增加多條 # sql3 = 'insert into userinfo (name,password) VALUES (%s,%s)' # li = li = [ # ('分省', '123'), # ('到達','456') # ] # ret = db.insertmany(sql3,li) # print(ret) # TODO 刪除 # sql4 = 'delete from userinfo WHERE name=%s' # args = 'xxxx' # ret = db.delete(sql4, args) # print(ret) # TODO 更新 # sql5 = r'update userinfo set password=%s WHERE name LIKE %s' # args = ('993333993', '%old%') # ret = db.update(sql5, args) # print(ret)二、連接池測試修改 db_dbutils_init.py 文件,在創建連接池def __getconn(self):方法下,加一個打印隨機數,方便將來我們定位是否時單例的線程池。
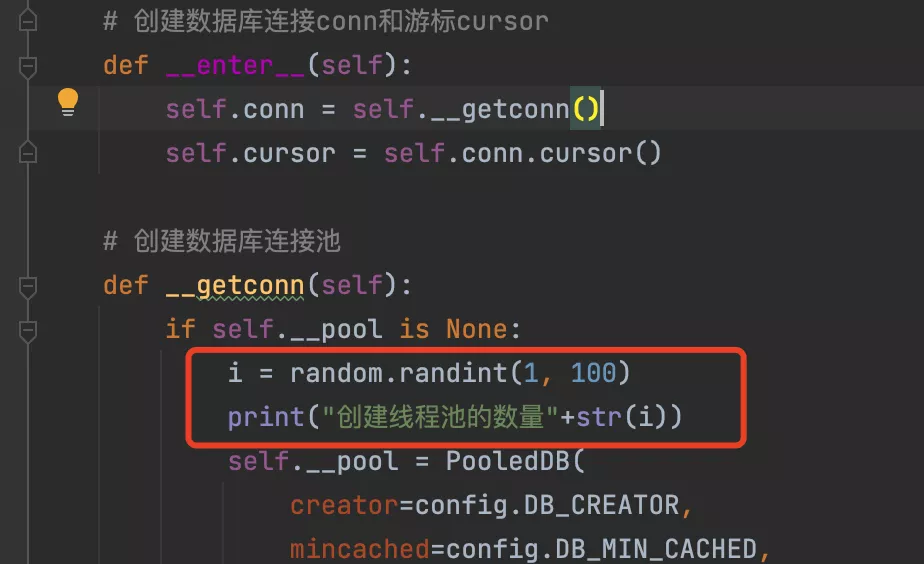
修改後的db_dbutils_init.py 文件:
from dbutils.pooled_db import PooledDBimport db_config as configimport randomfrom singleton import singleton"""@功能:創建數據庫連接池"""class MyConnectionPool(object): # 私有屬性 # 能通過對象直接訪問,但是可以在本類內部訪問; __pool = None # def __init__(self): # self.conn = self.__getConn() # self.cursor = self.conn.cursor() # 創建數據庫連接conn和游標cursor def __enter__(self): self.conn = self.__getconn() self.cursor = self.conn.cursor() # 創建數據庫連接池 def __getconn(self): if self.__pool is None: i = random.randint(1, 100) print("線程池的隨機數"+str(i)) self.__pool = PooledDB( creator=config.DB_CREATOR, mincached=config.DB_MIN_CACHED, maxcached=config.DB_MAX_CACHED, maxshared=config.DB_MAX_SHARED, maxconnections=config.DB_MAX_CONNECYIONS, blocking=config.DB_BLOCKING, maxusage=config.DB_MAX_USAGE, setsession=config.DB_SET_SESSION, host=config.DB_TEST_HOST, port=config.DB_TEST_PORT, user=config.DB_TEST_USER, passwd=config.DB_TEST_PASSWORD, db=config.DB_TEST_DBNAME, use_unicode=False, charset=config.DB_CHARSET ) return self.__pool.connection() # 釋放連接池資源 def __exit__(self, exc_type, exc_val, exc_tb): self.cursor.close() self.conn.close() # 關閉連接歸還給鏈接池 # def close(self): # self.cursor.close() # self.conn.close() # 從連接池中取出一個連接 def getconn(self): conn = self.__getconn() cursor = conn.cursor() return cursor, conn # 獲取連接池,實例化@singletondef get_my_connection(): return MyConnectionPool()開始測試:
場景一:同一個實例,執行2次sqlfrom mysqlhelper import MySqLHelperimport timeif __name__ == '__main__': sql = "SELECT SLEEP(10)" sql1 = "SELECT SLEEP(15)" db = MySqLHelper() db.execute(sql) db.execute(sql1) time.sleep(20)在數據庫中,使用 show processlist;
show processlist;當執行第一個sql時。數據庫連接顯示。
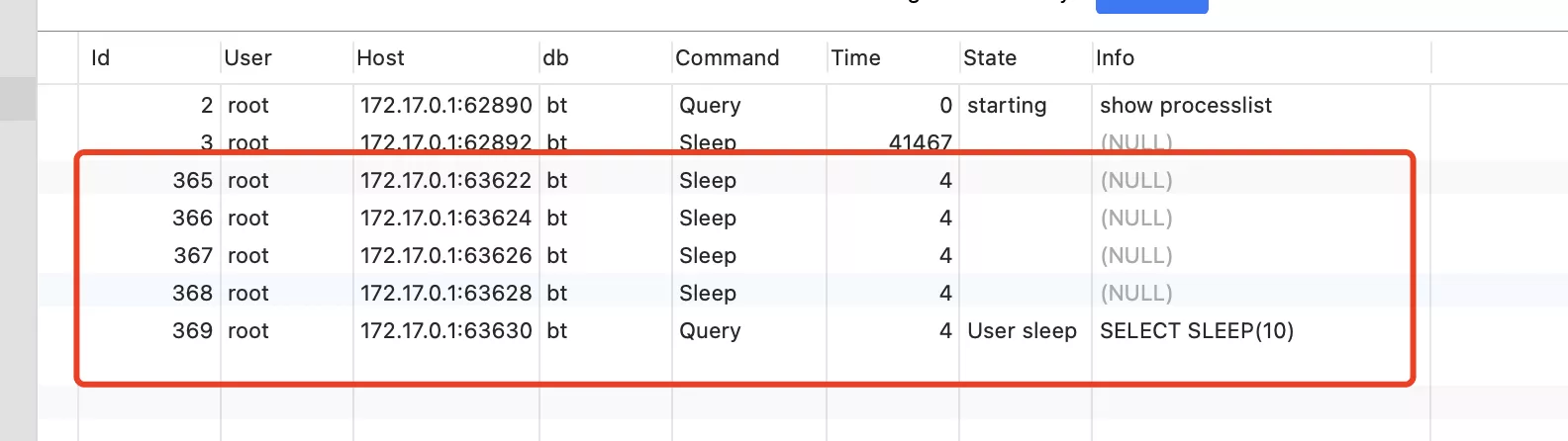
當執行第二個sql時。數據庫連接顯示:
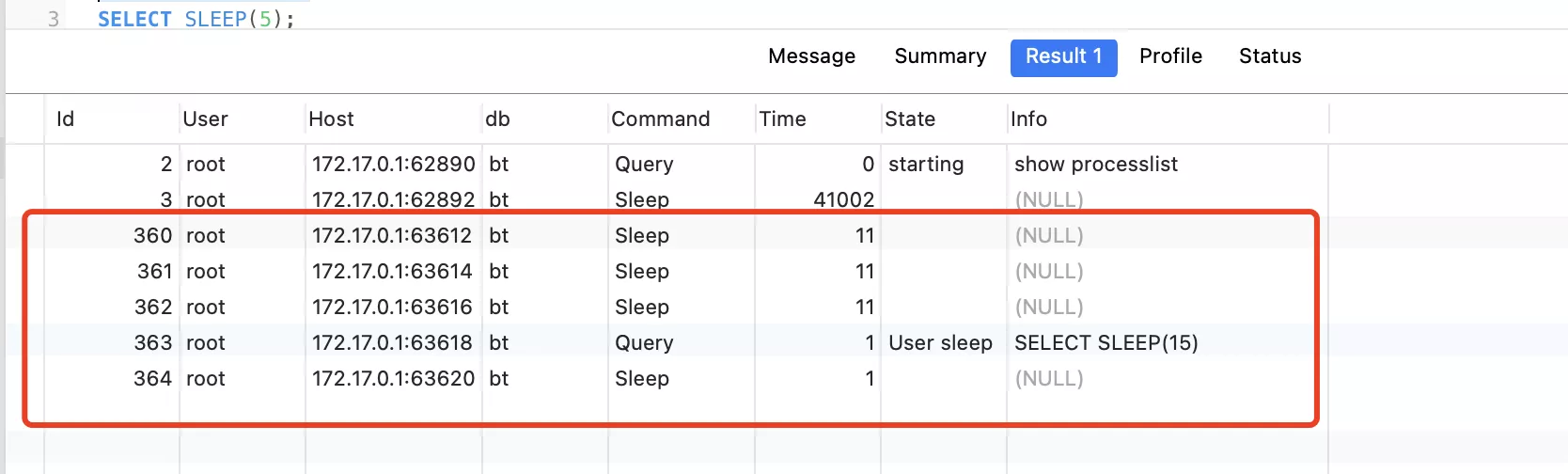
當執行完sql,程序sleep時。數據庫連接顯示:
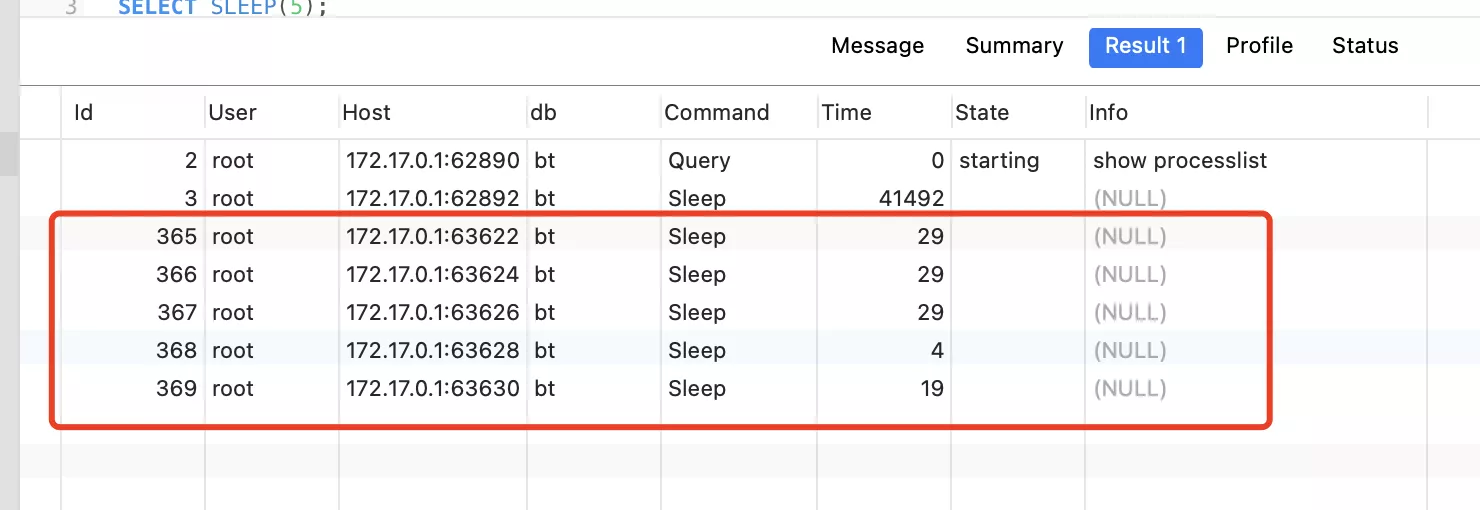
程序打印結果:
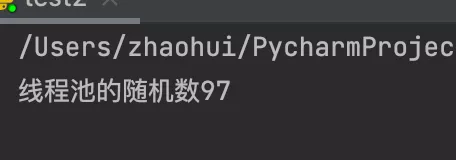
線程池的隨機數43
由以上可以得出結論:
線程池啟動後,生成了5個連接。執行第一個sql時,使用了1個連接。執行完第一個sql後,使用了另外1個連接。 這是一個線性的,線程池中一共5個連接,但是每次執行,只使用了其中一個。
有個疑問,連接池如果不支持並發是不是就毫無意義?
如上,雖然開了線程池5個連接,但是每次執行sql,只用到了一個連接。那為何不設置線程池大小為1呢?設置線程池大小的意義何在呢?(如果在非並發的場景下,是不是設置大小無意義?)
相比於不用線程池的優點:
如果不用線程池,則每次執行一個sql都要創建、斷開連接。 像我們這樣使用連接池,不用反復創建、斷開連接,拿現成的連接直接用就好了。
場景二:依次創建2個實例,各自執行sqlfrom mysqlhelper import MySqLHelperimport timeif __name__ == '__main__': db = MySqLHelper() db1 = MySqLHelper() sql = "SELECT SLEEP(10)" sql1 = "SELECT SLEEP(15)" db.execute(sql) db1.execute(sql1) time.sleep(20)第一個實例db,執行sql。線程池啟動了5個連接
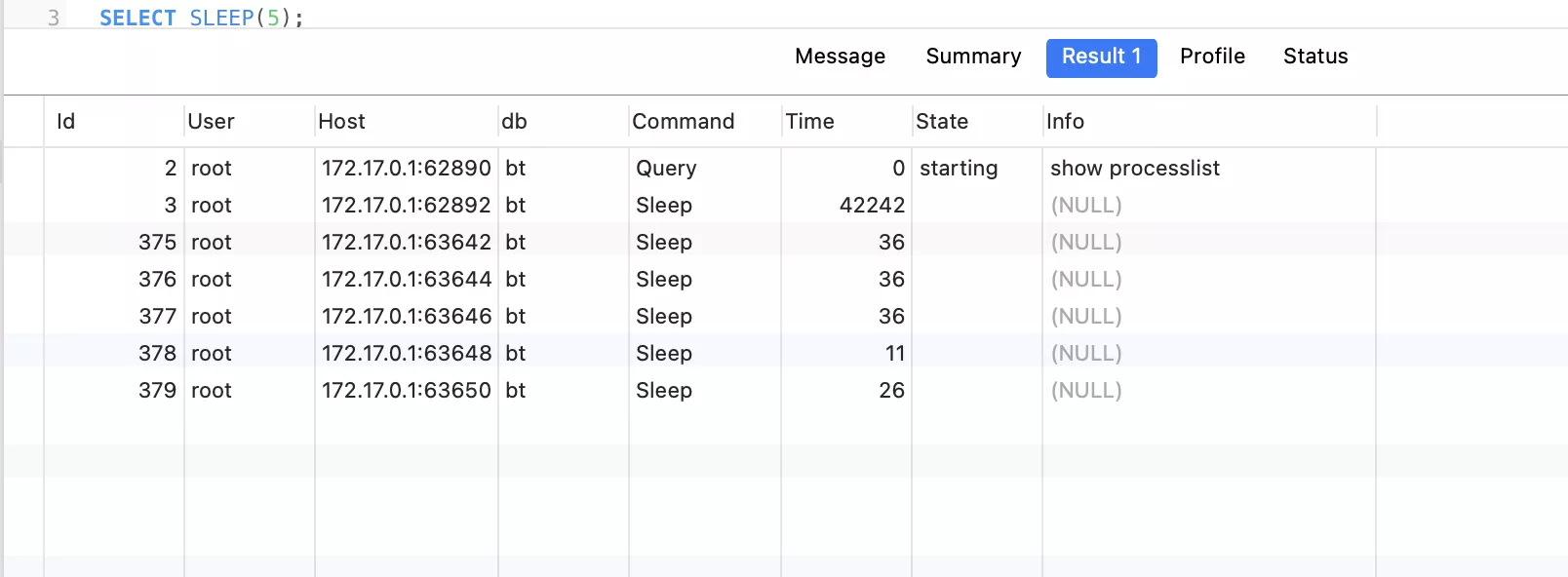
第二個實例db1,執行sql:
程序睡眠時,一共5個線程池:
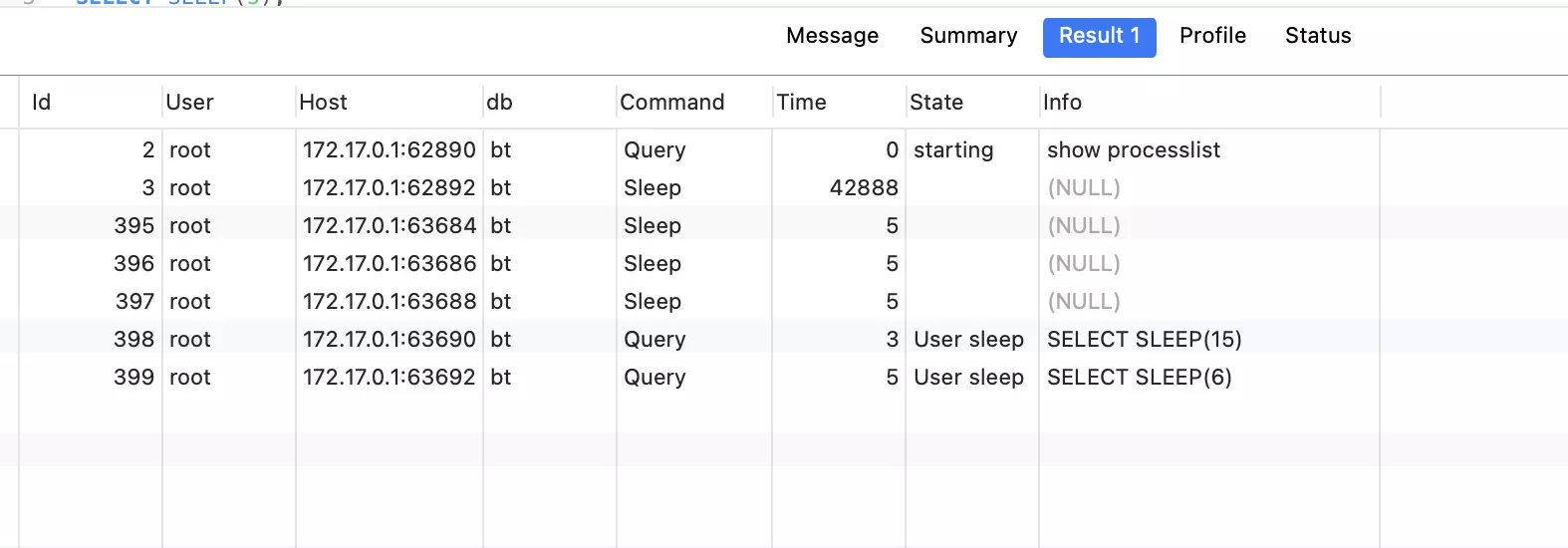
打印結果:
結果證明:
雖然我們依次創建了2個實例,但是(1)創建線程池的打印結果,只打印1次,且從始至終,線程池一共只啟動了5個連接,且連接的id沒有發生改變,說明一直是這5個連接。
證明,我們雖然創建了2個實例,但是這2個實例其實是一個實例。(單例模式是生效的)
場景三:啟動2個線程,但是線程在創建連接池實例時,有時間間隔import threadingfrom mysqlhelper import MySqLHelperimport timedef sl1(): time.sleep(2) db = MySqLHelper() sql = "SELECT SLEEP(6)" db.execute(sql)def sl2(): time.sleep(4) db = MySqLHelper() sql = "SELECT SLEEP(15)" db.execute(sql)if __name__ == '__main__': threads = [] t1 = threading.Thread(target=sl1) threads.append(t1) t2 = threading.Thread(target=sl2) threads.append(t2) for t in threads: t.setDaemon(True) t.start() time.sleep(20)2個線程間隔了2秒。
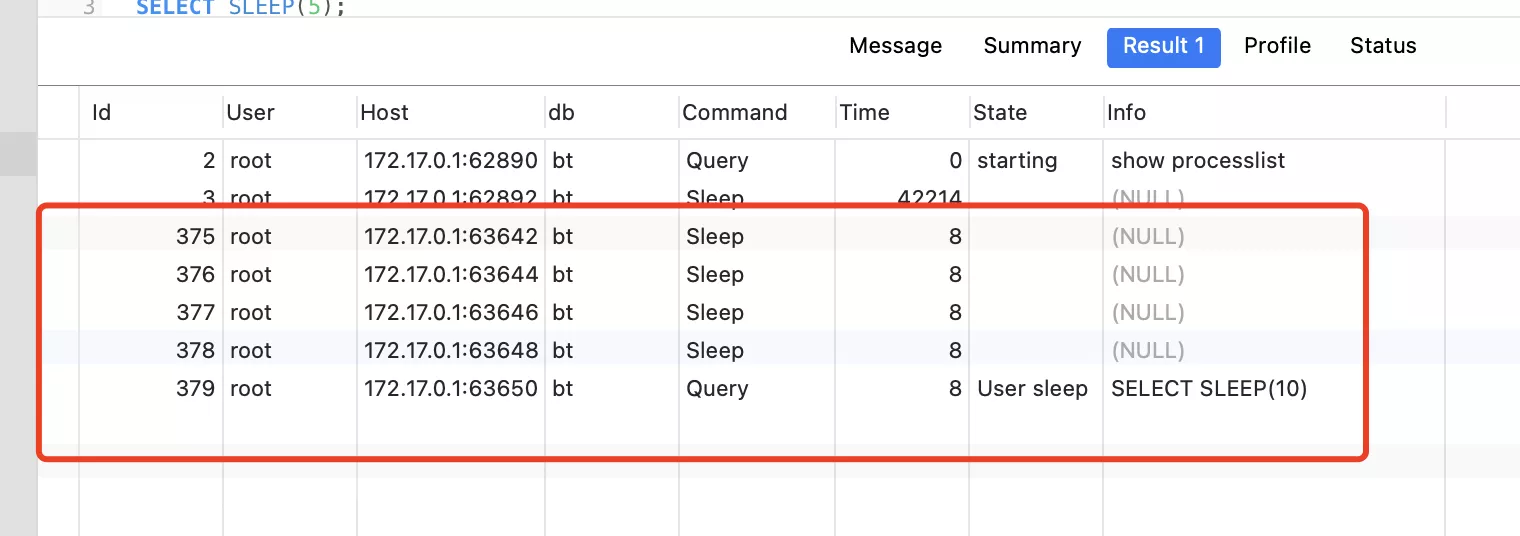
觀察數據庫的連接數量:
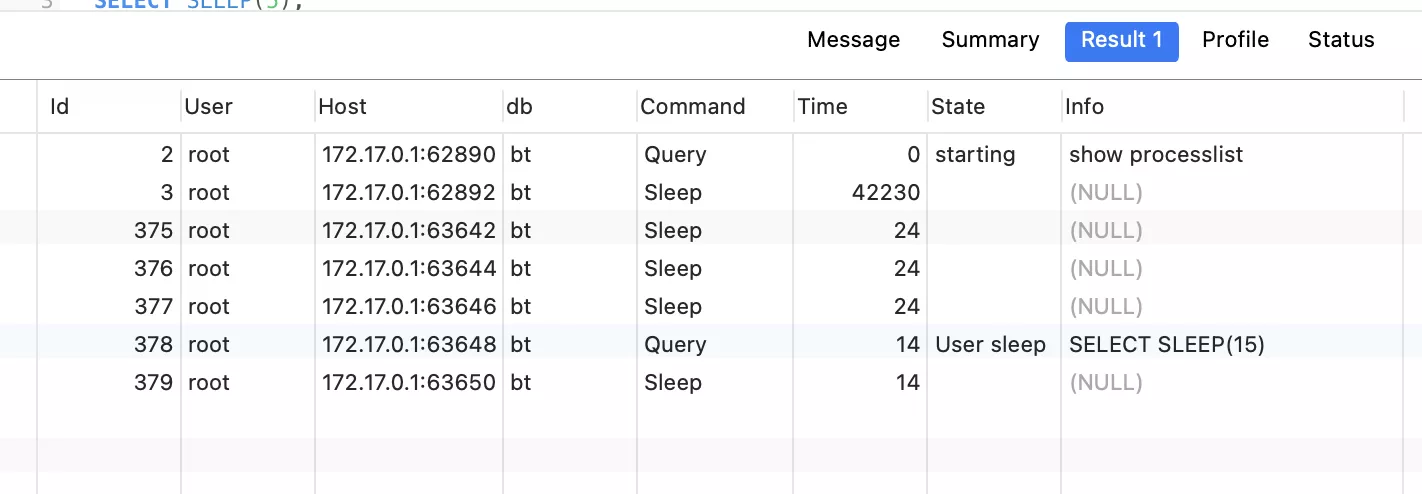
打印結果:
在並發執行2個sql時,共用了這5個連接,且打印結果只打印了一次,說明雖然並發創建了2次實例,但真正只創建了一個連接池。
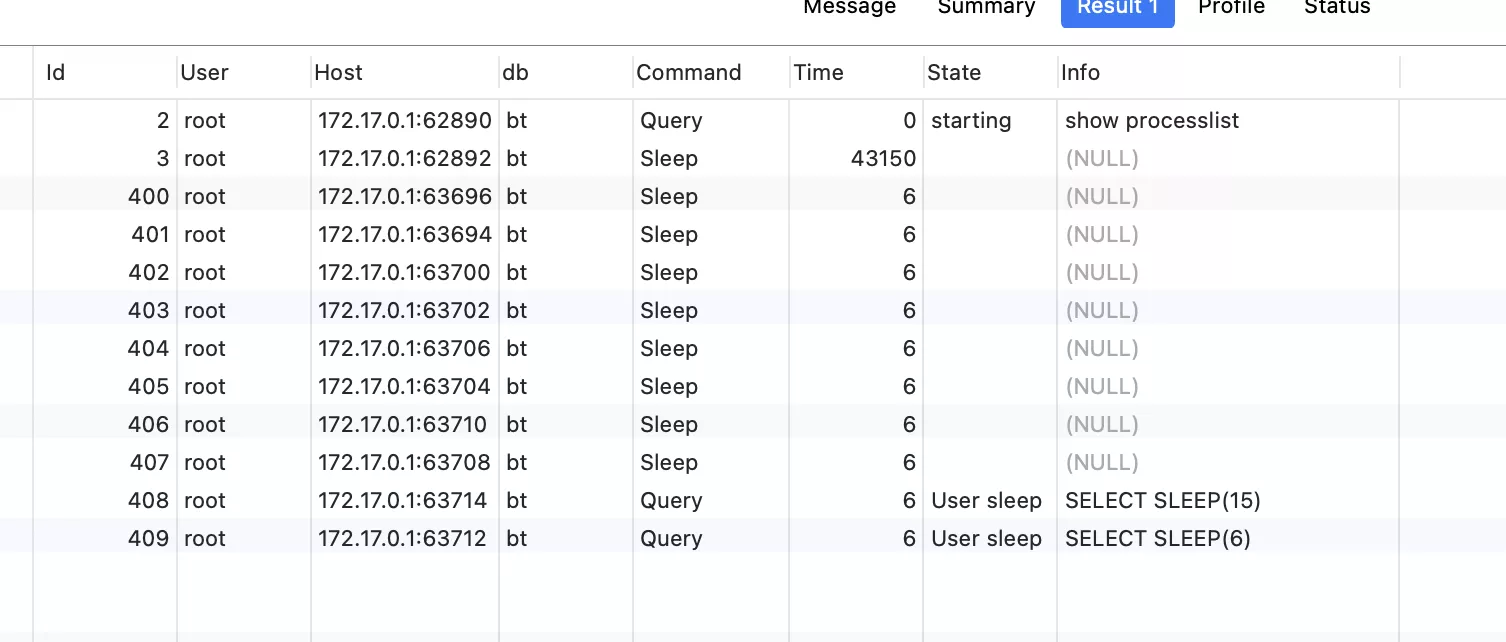
場景四:啟動2個線程,線程在創建連接池實例時,沒有時間間隔import threadingfrom mysqlhelper import MySqLHelperimport timeif __name__ == '__main__': db = MySqLHelper() sql = "SELECT SLEEP(6)" sql1 = "SELECT SLEEP(15)" threads = [] t1 = threading.Thread(target=db.execute, args=(sql,)) threads.append(t1) t2 = threading.Thread(target=db.execute, args=(sql1,)) threads.append(t2) for t in threads: t.setDaemon(True) t.start() time.sleep(20)觀察數據庫連接 :
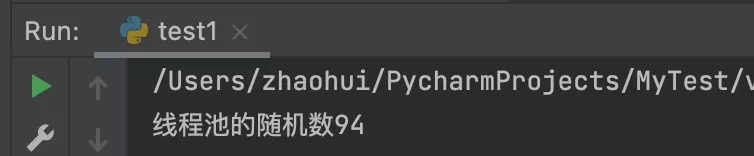
打印結果:
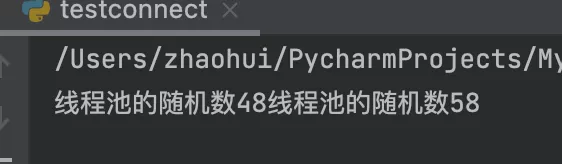
結果表明:
終端打印了2次,數據庫建立了10個連接,說明創建了2個線程池。這樣的單例模式,存在線程安全問題。
到此這篇關於Python封裝數據庫連接池詳解的文章就介紹到這了,更多相關Python連接池內容請搜索軟件開發網以前的文章或繼續浏覽下面的相關文章希望大家以後多多支持軟件開發網!