Preface
1. Create a process
2. In progress Queue
3. Performance comparison between multi process and multi thread
4. The process of pool pool
5. Shared memory
6. Process lock lock
PrefaceNow our computers are multi-core , Generally speaking, it means multiple processing or computing units . In order to speed up computation and processing , We can delegate different tasks to multiple cores for simultaneous processing , Thus, the operation speed and efficiency are improved , Simultaneous operation of multiple cores means simultaneous operation of multiple processes , This is multi process .
1. Create a processThe method of creating process and thread is basically the same , Look at the following code :
# coding:utf-8# Import multi process packages , And rename to mpimport multiprocessing as mp# Main work def p1(): print("zxy")if __name__ == "__main__": # Create a new process new_process = mp.Process(target=p1, name="p1") # Start the process new_process.start() # Block the process new_process.join()Console rendering :
Why use in multiprocessing queue Well ?
Because multiprocessing is like multithreading , In the working function , Unable to get return Returns the result in the process function , So use queue Store the results , Take it out when you need it .
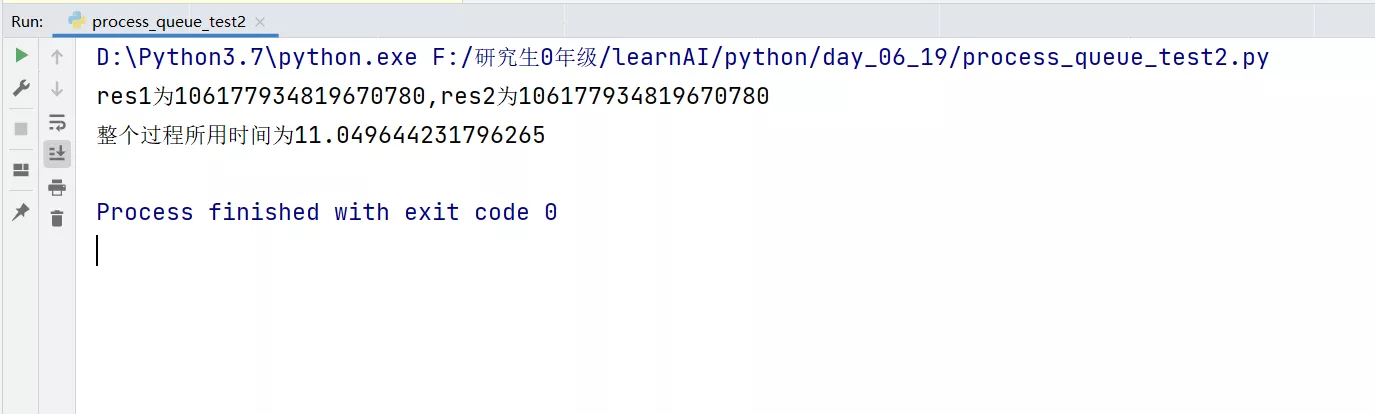
# coding:utf-8import timeimport multiprocessing as mp""" When using multiprocessing , Time taken to run the program """def job1(q): res = 0 for i in range(100): res += i + i**5 +i**8 time.sleep(0.1) # Put the results in the queue q.put(res)def job2(q): res = 0 for i in range(100): res += i + i**5 +i**8 time.sleep(0.1) q.put(res)if __name__ == "__main__": start_time = time.time() # Create a queue q = mp.Queue() # Create a process 1 process1 = mp.Process(target=job1, args=(q,)) # Create a process 2 process2 = mp.Process(target=job2, args=(q,)) process1.start() process2.start() # Get the value through the queue res1 = q.get() res2 = q.get() print("res1 by %d,res2 by %d" % (res1, res2)) end_time = time.time() print(" The whole process takes %s" %(end_time-start_time))design sketch :

Next, use multi process 、 Multithreading 、 And the common way of doing things without anything , See how effective their three methods are ?
# coding:utf-8import multiprocessing as mpimport timeimport threading as th""" Multi process 、 Multithreading 、 Performance comparison of common methods """# Multiprocess work def mp_job(res): for i in range(10000000): res += i**5 + i**6 print(res)# Multithreading def mt_job(res): for i in range(10000000): res += i**5 + i**6 print(res)# Common methods of working def normal_job(res): for i in range(10000000): res += i ** 5 + i ** 6 print(res)if __name__ == "__main__": mp_sum = 0 mp_start = time.time() process1 =mp.Process(target=mp_job, args=(mp_sum, )) process2 = mp.Process(target=mp_job, args=(mp_sum,)) process1.start() process2.start() process1.join() process2.join() mp_end = time.time() print(" Multi process usage time is ", (mp_end-mp_start)) mt_start = time.time() mt_sum = 0 thread1 = th.Thread(target=mt_job, args=(mt_sum, )) thread2 = th.Thread(target=mt_job, args=(mt_sum, )) thread1.start() thread2.start() thread1.join() thread2.join() mt_end = time.time() print(" The time used by multithreading is ", (mt_end-mt_start)) normal_start = time.time() normal_sum = 0 # Do it twice normal_job(normal_sum) normal_job(normal_sum) normal_end = time.time() print(" The common method used is ", (normal_end-normal_start))design sketch :
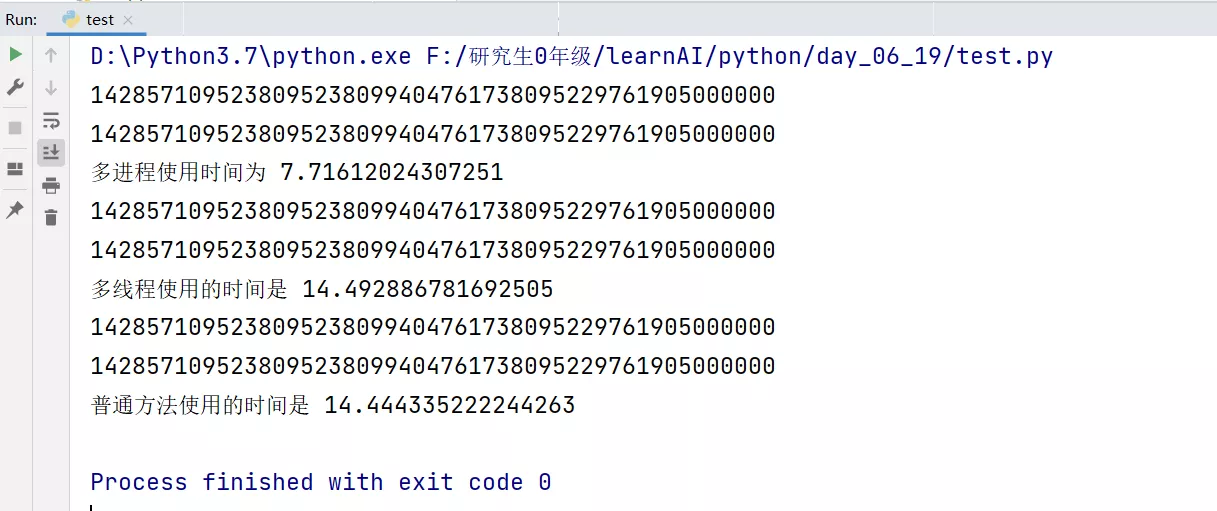
Experimental results show that : Multi process efficiency is really high !!!
4. The process of pool pool What is the process pool for ?
The process pool is python A pool provided by multiple processes , Put all processes in this pool , Let the computer use the resources in the process pool by itself , So many processes can process some programs , In order to improve the work efficiency .
(1) By default, all processes in the process pool are used
# coding:utf-8import timeimport multiprocessing as mp""" The process of pool pool Use """def job(num): time.sleep(1) return num * numif __name__ == "__main__": start_time = time.time() # When there is no parameter in the bracket , All processes in the process pool are used by default pool = mp.Pool() res = pool.map(job, range(10)) print(res) end_time = time.time() print(" Run at ", (end_time-start_time))design sketch :
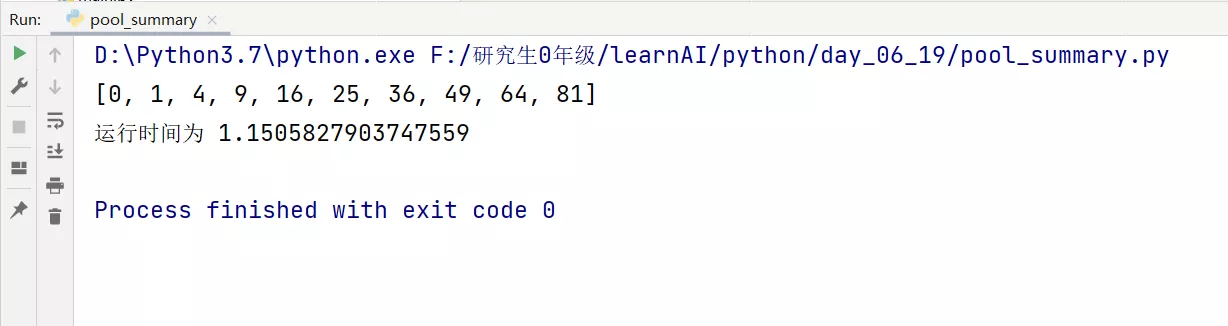
(2) When specifying the number of processes in the process pool
# coding:utf-8import timeimport multiprocessing as mp""" The process of pool pool Use """def job(num): time.sleep(1) return num * numif __name__ == "__main__": start_time = time.time() # When adding parameters in brackets , Specify two processes to process pool = mp.Pool(processes=2) res = pool.map(job, range(10)) print(res) end_time = time.time() print(" Run at ", (end_time-start_time))design sketch :
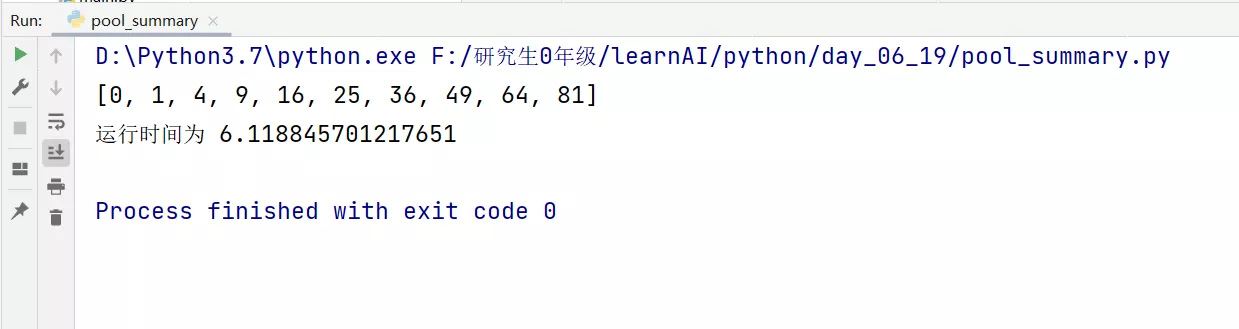
(3) When multiple processes are not used
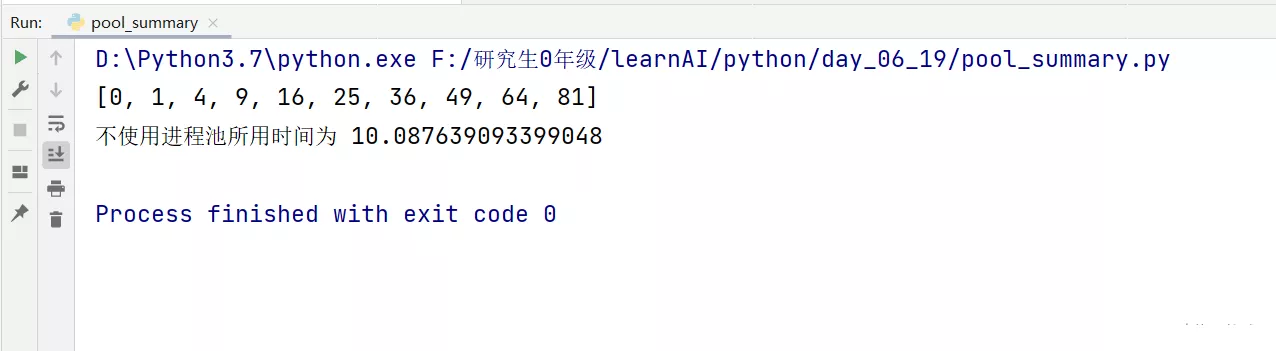
# coding:utf-8import timedef job(res): for i in range(10): res.append(i*i) time.sleep(1)if __name__ == "__main__": start_time = time.time() res = [] job(res) print(res) end_time =time.time() print(" The time taken to not use the process pool is ", (end_time-start_time))design sketch :

The experimental conclusion : Multi process processing , It's very efficient !!! The more cores , The faster the process !
5. Shared memory One core , When we multithread , You can use global variables to share data . But it is not possible between multiple processes , How should we share data among multiple processes ?
Then you have to use shared memory !
# coding:utf-8import multiprocessing as mp""" Shared memory """if __name__ == "__main__": # The first parameter is the code of the data type ,i For integer type # The second parameter is the value of the shared data v = mp.Value("i", 0)6. Process lock lockThe usage of process lock and thread lock are basically the same . The birth of process lock is to avoid preemption of shared data among multiple processes , This will lead to the chaotic modification of shared memory among multiple processes .
(1) Before locking
# coding:utf-8import multiprocessing as mpimport time""" Lock in process lock"""def job(v, num): for i in range(10): v.value += num print(v.value) time.sleep(0.2)if __name__ == "__main__": # Shared memory in multiple processes v = mp.Value("i", 0) # process 1 Let the shared variable be added each time 1 process1 = mp.Process(target=job, args=(v, 1)) # process 2 Let the shared variable be added each time 3 process2 = mp.Process(target=job, args=(v, 3)) process1.start() process2.start()design sketch :
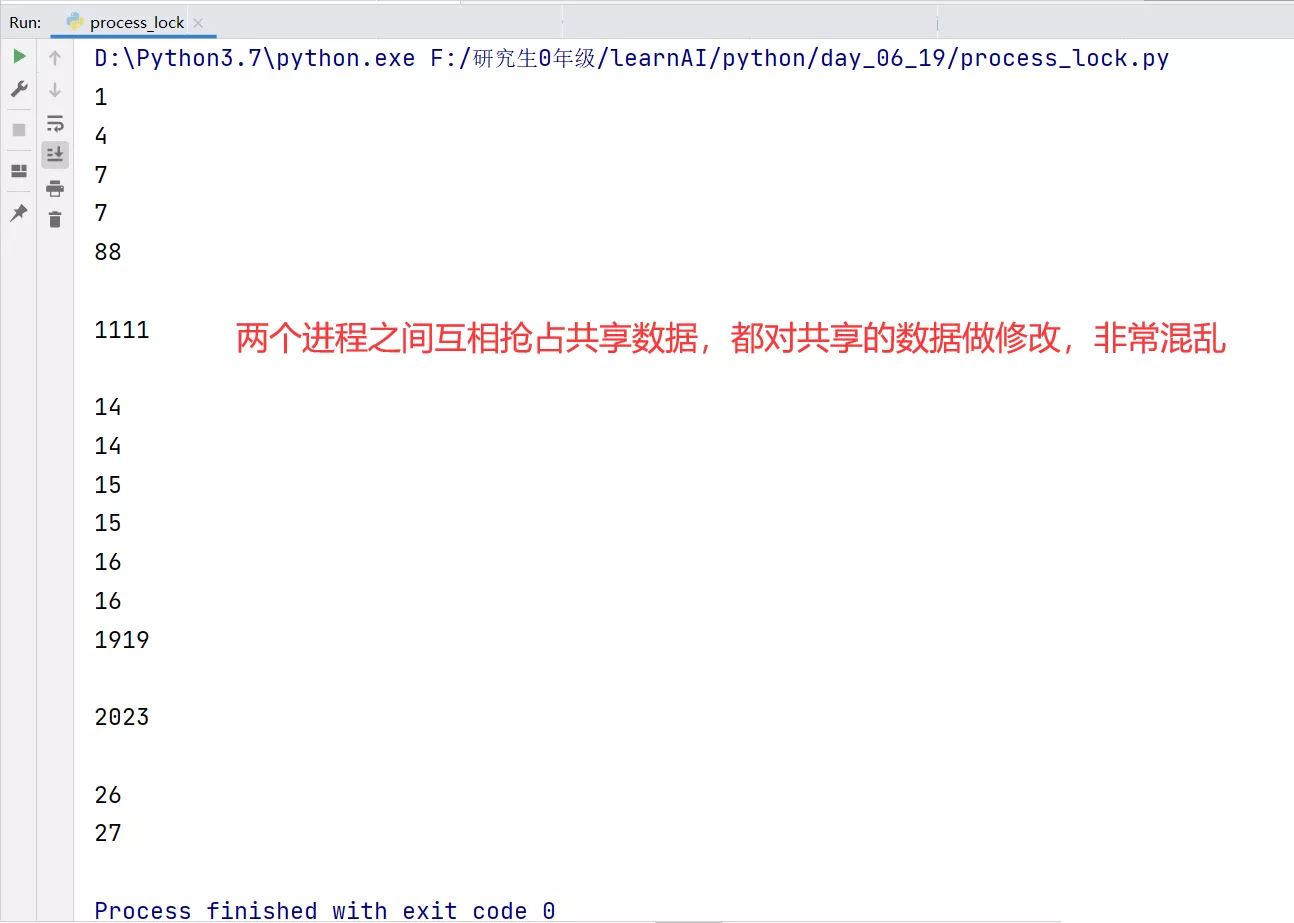
(2) After lock up
# coding:utf-8import multiprocessing as mpimport time""" Lock in process lock"""def job(v, num, l): # Lock l.acquire() for i in range(10): v.value += num print(v.value) time.sleep(0.2) # Unlock l.release()if __name__ == "__main__": # Create process lock l = mp.Lock() # Shared memory in multiple processes v = mp.Value("i", 0) process1 = mp.Process(target=job, args=(v, 1, l)) process2 = mp.Process(target=job, args=(v, 3, l)) process1.start() process2.start()design sketch :
This is about in-depth analysis Python This is the end of the multi process article in , More about Python For multi process content, please search the previous articles of SDN or continue to browse the relevant articles below. I hope you will support SDN more in the future !