資源下載地址:https://download.csdn.net/download/sheziqiong/85705488
資源下載地址:https://download.csdn.net/download/sheziqiong/85705488
"拍拍貸"提供的數據包括信用違約標簽(因變量)、建模所需的基礎與加工字段(自變量)、相關用戶的網絡行為原始數據,數據字段已經做脫敏處理。本次實戰采用的是初賽數據,包括3萬條訓練集和2萬條測試集。數據文檔包括:
Master:每一行代表一個樣本(一筆成功成交借款),每個樣本包含200多個各類字段。
Log_Info:借款人的登陸信息,每個樣本含多條數據。
Userupdate_Info:借款人修改信息,每個樣本多條數據。
基於訓練集數據構建預測模型,使用模型計算測試集的評分(評分數值越高,表示越有可能出現貸款違約),評價標准為AUC。
數據清洗工作,主要做一下缺失值處理,常變量處理,空格符處理,字符大小寫轉換等
特征處理工作,分為特征轉換和特征衍生。主要做了以下工作:
Master數據:地理位置信息的處理(省份,城市),運營商和微博特征的轉換,以及對排序特征,periods特征的交叉組合等。
Log_Info數據:衍生出"累計登陸次數",“登錄時間的平均間隔”,"最近一次的登錄時間距離成交時間差"等特征。
Userupdate_Info數據:衍生出"最近的修改時間距離成交時間差",“修改信息的總次數”, "每種信息修改的次數"等特征。
特征篩選工作:利用lightgbm輸出特征重要性進行篩選。
建模工作:
單模型,選用的機器學習模型是lightgbm。
bagging模型:基於bagging的思想,通過對模型參數進行隨機擾動,構建多個子模型,選用的基模型是lightgbm。
數據離群值判定,清洗
利用XGboost,按特征重要性系統衍生新特征,剝離沒用的特征
特征的離散化,二值化,數值型特征衍生排序
交叉驗證,網格搜索完成lightGBM超參數設置
bagging lightGBM模型
Mater數據包含約50000個樣本,200多個字段。
# 樣本的好壞比
data1.target.value_counts()

好壞比約11:1,屬於不平衡數據集,因為最後模型用的是lightgbm,故本次實戰先不采用過采樣方法來進行數據抽樣,直接用原始數據來建模。
缺失變量的數據可視化

有一些變量缺失率很高,如果將缺失填充為0,這類變量其實可看做一類稀疏特征,由於xgboost,lightgbm等GBDT類樹模型對高維稀疏特征處理不太好,並考慮到這些變量的業務含義未知,攜帶的信息量太少,故對缺失率高的變量作刪除處理。
除了要考慮變量的缺失情況,也要考慮樣本缺失特征個數的情況,一個樣本如果缺失的特征很多,說明用戶的信息完善程度很低,通過對缺失樣本的可視化,發現了這些離群點,可以考慮刪除。
# 樣本的趨勢個數可視化
sc.plot_missing_user(df=data1,plt_size=(16,5))
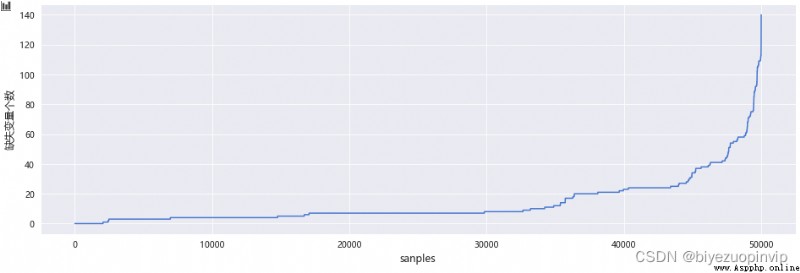
# 刪除變量缺失個數在100個以上的用戶
data1 = sc.missing_delete_user(df=data1,threshold=100)
缺失變量個數在100以上的用戶數有298個。
當一個變量中單個值所占比例過高(90%以上),說明該變量方差比較小,攜帶的信息較少,導致區分能力較差,對於這些變量也做刪除處理。
城市特征清洗:
# 計算4個城市特征的非重復項計數,觀察是否有數據異常
for col in ['UserInfo_2','UserInfo_4','UserInfo_8','UserInfo_20']:
print('{}:{}'.format(col,data1[col].nunique()))
print('\t')

UserInfo_8相對其他特征nunique較大,發現有些城市有"市",有些沒有,需要做一下格式轉換,去掉字符串後綴"市".
print(data1.UserInfo_8.unique()[:50])

# UserInfo_8清洗處理,處理後非重復項計數減小到400
data1['UserInfo_8']=[s[:-1] if s.find('市')>0 else s[:] for s in data1.UserInfo_8]
UserupdateInfo1特征大小寫轉換:
'UserupdateInfo1’包含了大小寫,如"qQ"和"QQ",屬於同一種意思,所以需要對其英文字符統一轉換大小寫。
# 將UserupdateInfo1裡的字符改為小寫形式
df2['UserupdateInfo1'] = df2.UserupdateInfo1.map(lambda x:x.lower())
對Master中的類別型特征(省份,城市,運營商,微博)做特征轉換,對數值型變量做排序特征,periods特征的衍生。
類別型特征:
原數據有兩個省份字段,推測一個為用戶的戶籍地址,另一個為用戶居住地址所在省份,由此可衍生的字段為:
省份二值化,通過違約率將單個省份衍生為二值化特征,分為戶籍省份和居住地省份
戶籍省份和居住地省份是否一致,推測不一致的用戶大部分為外來打工群體,相對違約率會高一點。
計算違約率時要考慮該省份的借款人數,如果人數太少,參考價值不大
省份二值化

兩種省份特征選擇出違約率排名前五的省份,並做二值化衍生。
戶籍省份和居住地省份不一致衍生
原數據中有4個城市信息,推測為用戶常登錄的IP地址城市,衍生的邏輯為:
通過xgboost挑選比較重要的城市變量,進行二值化衍生
由4個城市特征的非重復項計數可衍生成 登錄IP地址的變更次數
城市二值化衍生
# 根據xgboost變量重要性的輸出對城市作二值化衍生

將特征重要性排名前三的城市做二值化衍生:
IP地址變更次數衍生
因運營商的種類少,直接做亞編碼處理即可。
先對微博特征做一下缺失值填充,再做亞編碼處理。
數值型特征:
對數值型特征按數值從小到大進行排序,衍生成排序特征,排序特征異常值有更強的魯棒性,可以增強模型的穩定性,降低過擬合風險。
# 生成只包含periods的臨時表
periods_col = [i for i in num_col2 if i.find('Period')>0]
periods_col2 = periods_col+['target']
periods_data = data1.loc[:,periods_col2]
觀察包含period1所有字段的數據,發現字段之間量級差異比較大,可能代表不同的含義,不適合做衍生。
periods1_col = [col for col in periods_col if col.find('Period1')>0]
periods_data.loc[:,periods1_col].head()
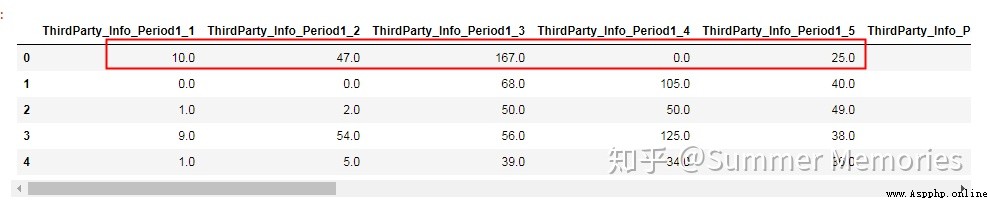
觀察後綴都為1的字段,發現字段數據的量級基本一致,可以對其做min,max,avg等統計值的衍生。
period_1_col=[]
for i in range(0,102,17):
col = periods_col[i]
period_1_col.append(col)
periods_data.loc[:,period_1_col].head()

對後綴都為1的periods字段做相應的四則運算(最小,最大,平均),衍生成新的特征。
衍生的變量
累計登錄次數
登錄時間的平均間隔
最近一次的登錄時間距離成交時間差
衍生的變量
將衍生特征匯總成一張表:
update_info = pd.merge(time_span,cate_change_df,on='Idx',how='left')
update_info = pd.merge(update_info,update_cnt,on='Idx',how='left')
update_info.head()
1.單模型lightgbm(single_lightgbm_model代碼模塊)
sklearn接口版本
[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-PwC1RKaq-1655693041517)(https://www.writebug.com/myres/static/uploads/2022/6/18/b8b514598c8d1312831c6c39cc33ea46.writebug)]
原生版本的lightgbm
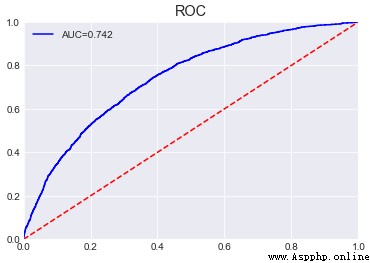
調參
# 確定最大迭代次數,學習率設為0.1
base_parmas={'boosting_type':'gbdt',
'learning_rate':0.1,
'num_leaves':40,
'max_depth':-1,
'bagging_fraction':0.8,
'feature_fraction':0.8,
'lambda_l1':0,
'lambda_l2':0,
'min_data_in_leaf':20,
'min_sum_hessian_inleaf':0.001,
'metric':'auc'}
cv_result = lgb.cv(train_set=lgb_train,
num_boost_round=200,
early_stopping_rounds=5,
nfold=5,
stratified=True,
shuffle=True,
params=base_parmas,
metrics='auc',
seed=0)
print('最大的迭代次數: {}'.format(len(cv_result['auc-mean'])))
print('交叉驗證的AUC: {}'.format(max(cv_result['auc-mean'])))
確定subsample為0.5,colsample_bytree為0.6
[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-6K6spI9z-1655693041520)(https://www.writebug.com/myres/static/uploads/2022/6/18/981a2f24600efae4e882a964a55f7894.writebug)]
確定reg_lambda為0.03,reg_alpha為0.3

確定最終的迭代次數為889次
lgb_single_model = lgb.LGBMClassifier(n_estimators=900,
learning_rate=0.005,
min_child_weight=0.001,
min_child_samples = 20,
subsample=0.5,
colsample_bytree=0.6,
num_leaves=30,
max_depth=-1,
reg_lambda=0.03,
reg_alpha=0.3,
random_state=0)
lgb_single_model.fit(x_train,y_train)
pre = lgb_single_model.predict_proba(x_test)[:,1]
print('lightgbm單模型的AUC:{}'.format(metrics.roc_auc_score(y_test,pre)))
sc.plot_roc(y_test,pre)
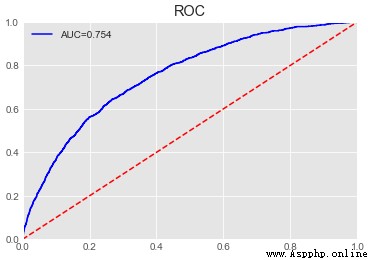
調參之後測試集的AUC提升了0.015。
主要借鑒了隨機森林對於選取樣本的隨機性和對於特征的隨機性的思想。
樣本隨機性的實現方法:random_seed,bagging_fraction,feature_fraction的參數擾動
特征隨機性的實現方法:在使用所有原生特征基礎上,隨機抽取一定的排序特征和periods特征至模型中。
資源下載地址:https://download.csdn.net/download/sheziqiong/85705488
資源下載地址:https://download.csdn.net/download/sheziqiong/85705488
 Django 01: first acquaintance with Django (attached case: user management)
Django 01: first acquaintance with Django (attached case: user management)
List of articles One 、 instal
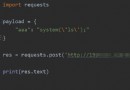 Subsequent analysis of Python connecting PHP Trojan horse (Book continued)
Subsequent analysis of Python connecting PHP Trojan horse (Book continued)
It was written before :Python