Datawhale dried food
selected from :AnalyticsVidhya, Ed translate : Almost Human
In recent days, ,Analyticsvidhya A paper entitled 《Introduction to Genetic Algorithm & their application in data science》 The article , author Shubham Jain make a personal example as an effective means of convincing others , This paper gives a comprehensive and concise overview of genetic algorithm in easy to understand language , Its practical applications in many fields are listed , The data science application of genetic algorithm is emphasized . The heart of the machine compiles this article .
A few days ago , I set about solving a practical problem —— Sales problems in large supermarkets . After using several simple models to do some feature Engineering , I'm number one on the list 219 name .
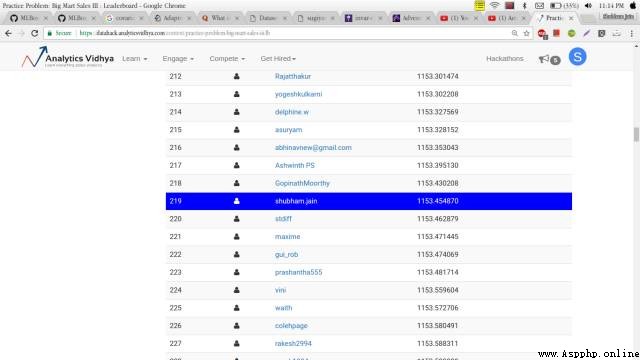
Although the result is good , But I still want to do better . therefore , I began to study optimization methods that can improve scores . As a result, I found one , It is called genetic algorithm . After applying it to the supermarket sales problem , In the end, my score leaped to the top of the list .
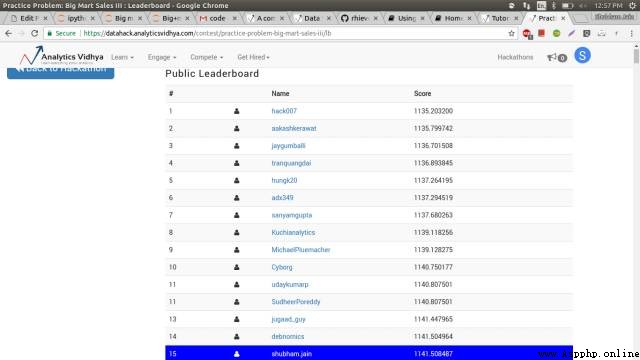
you 're right , Genetic algorithm alone, I will start from 219 Name jumps directly to 15 name , Terrible! ! I believe that after reading this article , You can also use genetic algorithms freely , And will find out , When it comes to the problem you are dealing with , The effect will also be greatly improved .
1、 The origin of genetic algorithm theory
2、 Inspired by Biology
3、 Genetic algorithm defines
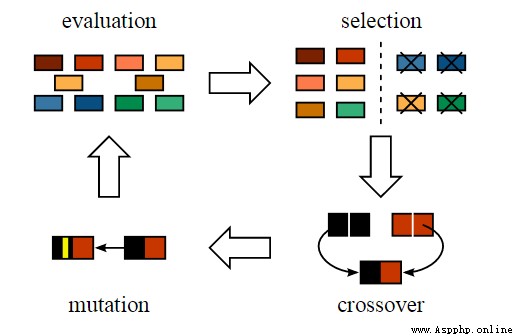
4、 Specific steps of genetic algorithm
initialization
Fitness function
choice
cross
variation
5、 Application of genetic algorithm
Feature selection
Use TPOT Library implementation
6、 The practical application
7、 Conclusion
Let's start with Charles · Darwin's famous saying begins :
It is often not the most powerful species that can survive , Not the smartest species , But the most adaptable species .
You may be thinking : What does this sentence have to do with genetic algorithm ? In fact, the whole concept of genetic algorithm is based on this sentence .
Let's use a basic example to explain :
Let's start with a scenario , Now you are the king of a country , To save your country from disaster , You implemented a set of laws :
You choose all the good people , Ask them to expand the number of people through childbirth .
This process has been going on for generations .
You will find , You already have a whole bunch of good people .
This example is unlikely , But I use it to help you understand the concept . in other words , We changed the input value ( such as : Population ), You can get better output value ( such as : A better country ). Now? , I assume you have a general understanding of the concept , The meaning of genetic algorithm should be related to biology . So let's quickly look at some small concepts , In this way, it can be connected to understand .
I believe you still remember this sentence :「 Cells are the cornerstone of all living things .」 Thus we can see that , In any cell of an organism , All have the same set of chromosomes . So called chromosomes , Means by DNA Composed of Polymers .
Traditionally , These chromosomes can be represented by numbers 0 and 1 Composed of string expression .
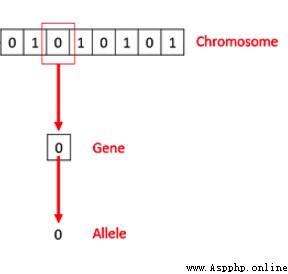
A chromosome is made up of genes , These genes actually make up DNA Basic structure ,DNA Each gene in the genome encodes a unique trait , such as , Hair or eye color . I hope you will recall the biological concepts mentioned here before you continue reading . This concludes this section , Now let's look at what genetic algorithm actually means ?
First, let's go back to the example we discussed earlier , And sum up what we have done .
First , We have set the initial population size of the people .
then , We define a function , Use it to distinguish good people from bad people .
Again , We choose good people , And let them breed their own offspring .
Last , These descendants have replaced some of the bad guys from the original citizens , And repeat the process .
This is how genetic algorithms actually work , in other words , It basically tries to simulate the process of evolution to some extent .
therefore , To formally define a genetic algorithm , We can think of it as an optimization method , It can try to find some input , With these inputs, we can get the best output value or result . The way genetic algorithms work also comes from biology , See the figure below for the specific process :
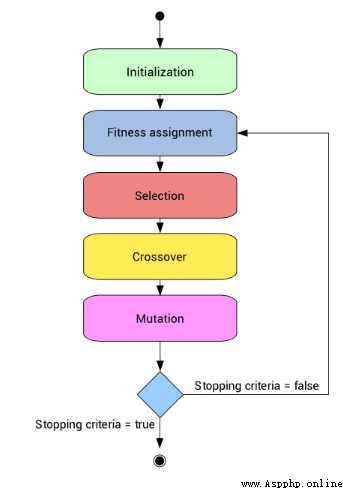
Now let's understand the whole process step by step .
In order to make the explanation easier , Let's first understand the famous combinatorial optimization problem 「 knapsack problem 」. If you don't understand , Here is a version of my explanation .
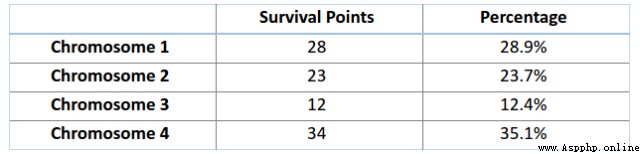
such as , You are going on a picnic 1 Months , But you can only carry one weight limit 30 Kilogram backpack . Now you have different necessities , Each of them has its own 「 Survival points 」( Details are given in the table below ). therefore , Your goal is to have a limited backpack weight , Maximize your 「 Survival points 」.
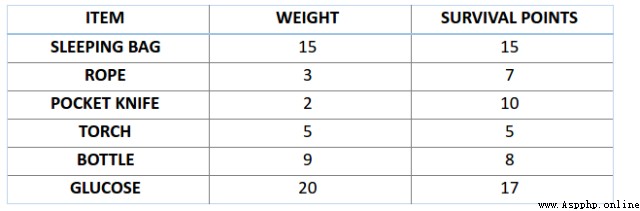
Here we use genetic algorithm to solve this knapsack problem . The first step is to define our overall . The population includes individuals , Each individual has its own set of chromosomes .
We know , Chromosomes can be expressed as binary strings , In this case ,1 Genes representing the next position exist ,0 It means losing .( translator's note : The author borrows chromosomes here 、 Genes to solve the knapsack problem in front , So the gene at a specific location represents the item in the knapsack problem table above , For example, the first position is Sleeping Bag, At this time, it is reflected in the chromosome 『 gene 』 The position is the first of the chromosome 『 gene 』.)
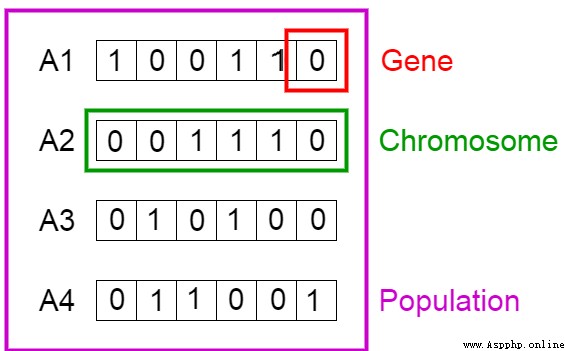
Now? , Let's take the 4 Chromosomes are considered as our overall initial value .
Next , Let's calculate the fitness scores of the first two chromosomes . about A1 Chromosome [100110] for , Yes :
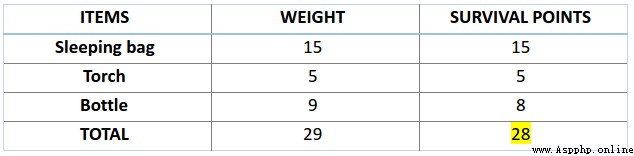
Similarly , about A2 Chromosome [001110] Come on , Yes :
For this question , We think , When chromosomes contain more survival scores , That means it is more adaptable .
therefore , It can be seen from the picture that , Chromosome 1 Adaptability is stronger than chromosome 2.
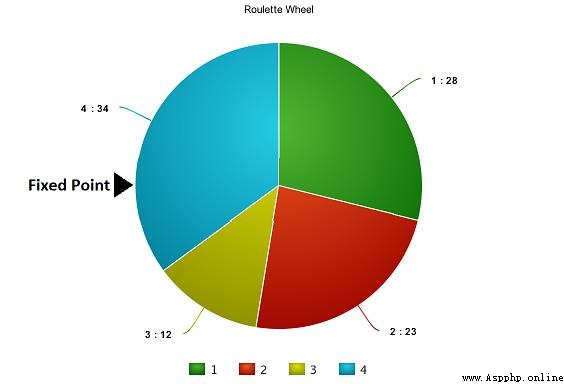
Now? , We can start selecting the right chromosome from the population , To make them mutual 『 mating 』, Have their own next generation . This is the general idea of the selection operation , However, this will lead to the reduction of chromosome differences after several generations , Lost diversity . therefore , We usually do 「 Roulette selection 」(Roulette Wheel Selection method).

Imagine having a roulette , Now let's split it into m Parts of , there m Represents the number of chromosomes in our population . The area occupied by each chromosome on the roulette will be expressed in proportion to the fitness score .
Based on the values in the above figure , We establish the following 「 Wheel disc 」.
Now? , This disc begins to rotate , We will be fixed by the pointer in the figure (fixed point) The area indicated was selected as the first parent . then , For the second parent , We do the same . Sometimes we mark two fixed pointers on the way , Here's the picture :
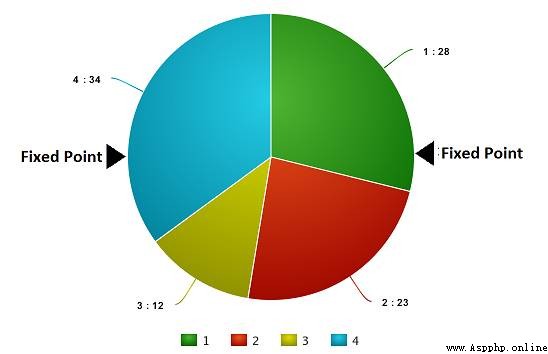
In this way , We can get two parents in one round . We call this method 「 Random universal selection 」(Stochastic Universal Selection method).
In the last step , We have selected the parent chromosomes that can produce offspring . So in biological terms , So-called 「 cross 」, Actually, it means reproduction . Now let's look at the chromosomes 1 and 4( Selected in the previous step ) Conduct 「 cross 」, See the picture below :
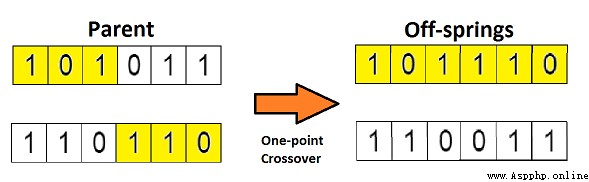
This is the most basic form of crossover , We call it 「 A single point of intersection 」. Here we randomly select an intersection , then , The chromosome parts before and after the crossing point are cross transferred between chromosomes , So there are new descendants .
If you set two intersections , Then this method is called 「 Multi-point crossover 」, See the picture below :
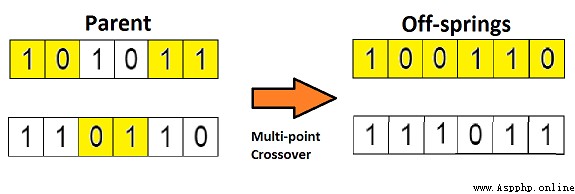
4.5 variation
If we now look at this problem from a biological point of view , So, please. : Does the offspring produced by the above process have the same traits as their parents ? Is the answer . During the growth of offspring , There will be some changes in their genes , Make them different from their parents . This process we call 「 variation 」, It can be defined as a random change on a chromosome , It is because of variation , There will be diversity in the population .
The following figure is a simple example of variation :

After mutation , We get new individuals , Evolution is complete , The whole process is shown below :
After a round 「 Genetic variation 」 after , We use fitness function to verify these new offspring , If the function determines that they have sufficient Fitness , Then they will be used to replace those chromosomes with insufficient fitness from the population . Here's the problem , What criteria should we use to judge whether the offspring have reached the best fitness level ?
Generally speaking , There are several termination conditions :
It's going on X After iterations , The overall situation has not changed much .
We have defined the number of evolutions for the algorithm in advance .
When our fitness function has reached the predefined value .
Okay , Now I assume that you have basically understood the essentials of genetic algorithm , Now let's use it in the scenario of data science .
5.1 Feature selection
Imagine every time you take part in a data science competition , What methods would you use to select those features that are important for the prediction of your target variables ? You often judge the importance of features in the model , Then manually set a threshold , Select the features whose importance is higher than this threshold .
that , Is there any better way to deal with this problem ? In fact, one of the most advanced algorithms for feature selection is genetic algorithm .
Our previous approach to the knapsack problem can be fully applied here . Now? , Let's start with the establishment of 「 Chromosome 」 Overall start , The chromosomes here are still binary strings ,「1」 The representation model contains this feature ,「0 The representation model excludes this feature 」.
however , There is one difference , That is, our fitness function needs to be changed . The fitness function here should be the standard of the accuracy of this competition . in other words , If the predicted value of chromosome is more accurate , Then it can be said that its adaptability is higher .
Now let me assume that you have some idea of this method . I will not explain the process of solving this problem immediately , But let's use it first TPOT Library to implement it .
5.2 use TPOT Library to implement
This part is believed to be the final goal you want to achieve when you first read this article . namely : Realization . So first let's take a quick look at TPOT library (Tree-based Pipeline Optimisation Technique, Tree transfer optimization technology ), The library is based on scikit-learn Library establishment . The following figure shows a basic transfer structure .
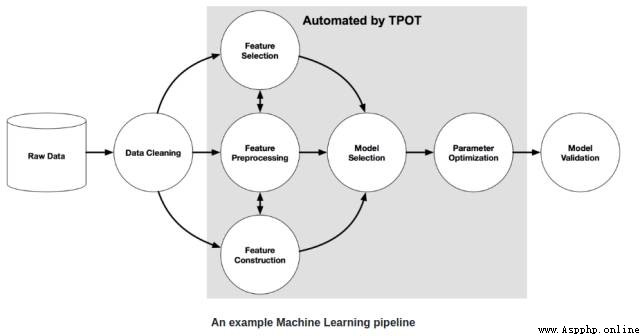
The gray areas in the figure are marked with TPOT The library implements automatic processing . Genetic algorithm is needed to realize the automatic processing of this part .
We won't go into details here , Instead, apply it directly . In order to be able to use TPOT library , You need to install some TPOT Based on it python library . Let's quickly install them :
# installing DEAP, update_checker and tqdm
pip install deap update_checker tqdm
# installling TPOT
pip install tpothere , I used it Big Mart Sales( Dataset address :https://datahack.analyticsvidhya.com/contest/practice-problem-big-mart-sales-iii/) Data sets , Prepare for implementation , Let's start by downloading training and test files quickly , Here are python Code :
# import basic libraries
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
from sklearn import preprocessing
from sklearn.metrics import mean_squared_error
## preprocessing
### mean imputations
train['Item_Weight'].fillna((train['Item_Weight'].mean()), inplace=True)
test['Item_Weight'].fillna((test['Item_Weight'].mean()), inplace=True)
### reducing fat content to only two categories
train['Item_Fat_Content'] = train['Item_Fat_Content'].replace(['low fat','LF'], ['Low Fat','Low Fat'])
train['Item_Fat_Content'] = train['Item_Fat_Content'].replace(['reg'], ['Regular'])
test['Item_Fat_Content'] = test['Item_Fat_Content'].replace(['low fat','LF'], ['Low Fat','Low Fat'])
test['Item_Fat_Content'] = test['Item_Fat_Content'].replace(['reg'], ['Regular'])
train['Outlet_Establishment_Year'] = 2013 - train['Outlet_Establishment_Year']
test['Outlet_Establishment_Year'] = 2013 - test['Outlet_Establishment_Year']
train['Outlet_Size'].fillna('Small',inplace=True)
test['Outlet_Size'].fillna('Small',inplace=True)
train['Item_Visibility'] = np.sqrt(train['Item_Visibility'])
test['Item_Visibility'] = np.sqrt(test['Item_Visibility'])
col = ['Outlet_Size','Outlet_Location_Type','Outlet_Type','Item_Fat_Content']
test['Item_Outlet_Sales'] = 0combi = train.append(test)for i in col:
combi[i] = number.fit_transform(combi[i].astype('str'))
combi[i] = combi[i].astype('object')
train = combi[:train.shape[0]]
test = combi[train.shape[0]:]
test.drop('Item_Outlet_Sales',axis=1,inplace=True)
## removing id variables
tpot_train = train.drop(['Outlet_Identifier','Item_Type','Item_Identifier'],axis=1)
tpot_test = test.drop(['Outlet_Identifier','Item_Type','Item_Identifier'],axis=1)
target = tpot_train['Item_Outlet_Sales']
tpot_train.drop('Item_Outlet_Sales',axis=1,inplace=True)
# finally building model using tpot library
from tpot import TPOTRegressor
X_train, X_test, y_train, y_test = train_test_split(tpot_train, target,
train_size=0.75, test_size=0.25)
tpot = TPOTRegressor(generations=5, population_size=50, verbosity=2)
tpot.fit(X_train, y_train)
print(tpot.score(X_test, y_test))
tpot.export('tpot_boston_pipeline.py')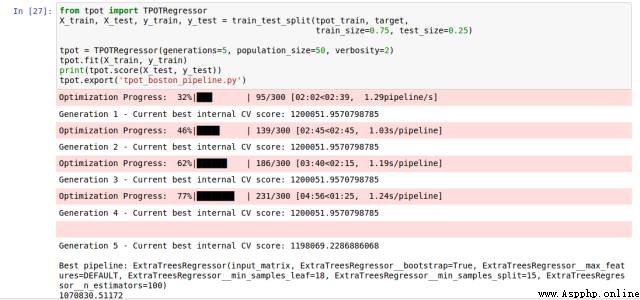
Once the code is running ,tpot_exported_pipeline.py Will be used for path optimization python Code . We can find out ,ExtraTreeRegressor Can best solve this problem .
## predicting using tpot optimised pipeline
tpot_pred = tpot.predict(tpot_test)
sub1 = pd.DataFrame(data=tpot_pred)
#sub1.index = np.arange(0, len(test)+1)
sub1 = sub1.rename(columns = {'0':'Item_Outlet_Sales'})
sub1['Item_Identifier'] = test['Item_Identifier']
sub1['Outlet_Identifier'] = test['Outlet_Identifier']
sub1.columns = ['Item_Outlet_Sales','Item_Identifier','Outlet_Identifier']
sub1 = sub1[['Item_Identifier','Outlet_Identifier','Item_Outlet_Sales']]
sub1.to_csv('tpot.csv',index=False)If you submit this csv, Then you will find that what I promised at the beginning has not been fully realized . Is it true that I am lying to you ? Of course not. . actually ,TPOT The library has a simple rule . If you don't run TPOT Too long , Then it won't find the most likely way to deliver your problem .
therefore , You have to add evolutionary Algebra , Take a coffee out for a walk , Others to TPOT Just go . Besides , You can also use this library to deal with classification problems . Refer to this document for further information :http://rhiever.github.io/tpot/. Except for the game , In life, we also have many application scenarios where genetic algorithms can be used .
Genetic algorithm has many applications in the real world . Here I have listed some interesting scenes , But due to space constraints , I won't go into details one by one .
Engineering design relies heavily on computer modeling and simulation , In this way, the design cycle process can be fast and economical . Genetic algorithm can be optimized here and give a good result .
Related resources :
The paper :Engineering design using genetic algorithms
Address :http://lib.dr.iastate.edu/cgi/viewcontent.cgi?article=16942&context=rtd
This is a very famous question , It has been used by many trading companies to make transportation more time-saving 、 economic . Genetic algorithm is also used to solve this problem .
6.3 robot
Genetic algorithm is widely used in robot field . actually , At present, people are using genetic algorithms to create autonomous learning robots that can act like humans , Its task can be cooking 、 Washing clothes, etc .
Related resources :
The paper :Genetic Algorithms for Auto-tuning Mobile Robot Motion Control
Address :https://pdfs.semanticscholar.org/7c8c/faa78795bcba8e72cd56f8b8e3b95c0df20c.pdf
I hope to introduce , You now have a good understanding of genetic algorithms , And I can also use TPOT Library to implement it . But if you don't do it yourself , The knowledge of this article is also very limited .
therefore , Please readers, be sure to try to realize it by yourself in the data science competition or life . 
Link to the original text :https://www.analyticsvidhya.com/blog/2017/07/introduction-to-genetic-algorithm/

Sorting is not easy to , spot Fabulous Three even ↓