process : Running programs ,QQ 360 ......
Threads : Is the execution path of an execution program in the process , A program has at least one execution path .(360 Antivirus in Computer physical examination Computer cleaning To run at the same time, you need to open multiple paths )
Each thread has its own content to run , These contents can be called tasks to be executed by threads .
Multithreading is enabled to run multiple parts of code at the same time .
benefits : It solves the problem that multiple parts need to run at the same time
disadvantages : If there are too many threads , Can lead to low efficiency ( Because the execution of the program is CPU Doing random Fast switching to complete )
The difference between thread and process
Threads share memory , Process independent memory thread start speed block , The process starts slowly , There is no comparability of runtime speed. Threads of the same process can communicate directly , Two processes want to communicate , The creation of a new thread must be achieved through an intermediary agent. It is very simple , Creating a new process requires cloning its parent process at a time. One thread can control and operate other threads in the same thread , But a process can only operate a child processthreading modular
Multithreading is used in one way : Use it directly
# -*- coding:utf-8 -*-# Threads are used in one way import threadingimport time# Functions that require multithreading def fun(args): print(" I am a thread %s" % args) time.sleep(2) print(" Threads %s End of run " % args)# Create thread t1 = threading.Thread(target=fun, args=(1,))t2 = threading.Thread(target=fun, args=(2,))start_time = time.time()t1.start()t2.start()end_time = time.time()print(" The total running time of the two threads is :", end_time-start_time)print(" End of main thread ")""" Running results : I am a thread 1 I am a thread 2 The total running time of the two threads is : 0.0010077953338623047 The main thread ends the thread 1 Run end thread 2 End of run """The second way to use threads : Call by inheritance
# Call by inheritance import threadingimport timeclass MyThreading(threading.Thread): def __init__(self, name): super(MyThreading, self).__init__() self.name = name # The code the thread wants to run def run(self): print(" I am a thread %s" % self.name) time.sleep(2) print(" Threads %s End of run " % self.name)t1 = MyThreading(1)t2 = MyThreading(2)start_time = time.time()t1.start()t2.start()end_time = time.time()print(" The total running time of the two threads is :", end_time-start_time)print(" End of main thread ")""" Running results : I am a thread 1 I am a thread 2 The total running time of the two threads is : 0.0010724067687988281 The main thread ends the thread 2 Run end thread 1 End of run """ Daemon thread and join Method stay Python In multithreaded programming ,join Method .
The guardian thread , It exists to protect others , When it is set as a daemon thread , After the guarded mainline does not exist , The daemon thread does not exist .
The first one is :python Multithreading defaults
Python Multithreading defaults ( Set thread setDaemon(False)), After the main thread finishes executing its own tasks , Dropped out , At this point, the sub thread will continue to perform its own tasks , Until the subthread task ends, the code demonstrates :threading The two examples of creating multiline formation in are .The second kind : Turn on the daemons
Open thread setDaemon(True)), Set the child thread as the guardian thread , Realize the end of the main program , The subroutine immediately ends the function code demonstration :# The guardian thread import threadingimport timeclass MyThreading(threading.Thread): def __init__(self, name): super(MyThreading, self).__init__() self.name = name # The code the thread wants to run def run(self): print(" I am a thread %s" % self.name) time.sleep(2) print(" Threads %s End of run " % self.name)t1 = MyThreading(1)t2 = MyThreading(2)start_time = time.time()t1.setDaemon(True)t1.start()t2.setDaemon(True)t2.start()end_time = time.time()print(" The total running time of the two threads is :", end_time-start_time)print(" End of main thread ")Be careful : If you want to set it as a daemon thread , Be sure to start the thread before , Set this thread as a guardian thread
Conclusion : After the main thread ends , No matter sub thread 1,2 Whether the operation is completed , End the thread , No further downward movement
The third kind of : Join in join Method to set synchronization
When a daemon is not set for a program , The main program will wait for the subroutine to complete before ending the code demonstration :# join: Thread synchronization import threadingimport timeclass MyThreading(threading.Thread): def __init__(self, name): super(MyThreading, self).__init__() self.name = name # The code the thread wants to run def run(self): print(" I am a thread %s" % self.name) time.sleep(3) print(" Threads %s End of run " % self.name)threading_list = []start_time = time.time()for x in range(50): t = MyThreading(x) t.start() threading_list.append(t)for x in threading_list: x.join() # Turn on Synchronization for threads end_time = time.time()print("50 The total running time of threads is :", end_time-start_time)print(" End of main thread ")Conclusion : Main thread waiting 50 The sub thread will not end until all execution is completed .
Thread lock ( The mutex Mutex)Multiple threads can be enabled under one process , Multiple threads share the memory space of the parent process , This means that each thread can access the same data , At this point, if multiple threads want to modify a copy of data at the same time , What will happen ?
Code demonstration :# -*- coding:utf8 -*-import threadingimport timenum = 100threading_list = []def fun(): global num print("get num:", num) num += 1 time.sleep(1)for x in range(200): t = threading.Thread(target=fun) t.start() threading_list.append(t)for x in threading_list: x.join()print("nun:", num)Conclusion : The running result may appear num<300 The situation of
Normally speaking , This num The result should be 300, But in python 2.7 Run it a few more times , Will find , The last print out num The results are not always 300, Why does the result of each run differ ? Ha , It's simple , Suppose you have A,B Two threads , At this time Right num add 1 operation , because 2 Threads are running concurrently , therefore 2 It's very likely that two threads took away at the same time num=100 This initial variable is given to the cpu Go to the operation , When A The result of the end of the thread is 101, But this time B The result of thread operation is also 101, Two threads at the same time CPU The result of the operation is assigned to num After the variable , It turns out to be 101. Then what shall I do? ? It's simple , When each thread wants to modify the common data , In order to avoid others to modify this data when they haven't finished , You can put a lock on this data , In this way, when other threads want to modify this data, they must wait for you to modify it and release the lock before accessing this data .
* notes : Not in 3.x Up operation , I don't know why ,3.x The result is always right on the Internet , Maybe it's locked automatically
Locked version :
import randomimport threadingimport timenum = 100threading_list = []def fun(): global num time.sleep(random.random()) lock.acquire() # Lock print("get num:", num, threading.current_thread()) num += 1 lock.release() # Release the lock # Instantiate the lock object lock = threading.Lock()for x in range(200): t = threading.Thread(target=fun) t.start() threading_list.append(t)for x in threading_list: x.join()print("num:", num)
GIL VS Lock
Witty students may ask this question , That is, since you said ,Python There is already one GIL To ensure that only one thread can execute at a time , Why do we need lock? Attention! , there lock It's user level lock, With that one GIL No problem , Let's take a look at the following figure + Cooperate with me to tell you , Will understand the .
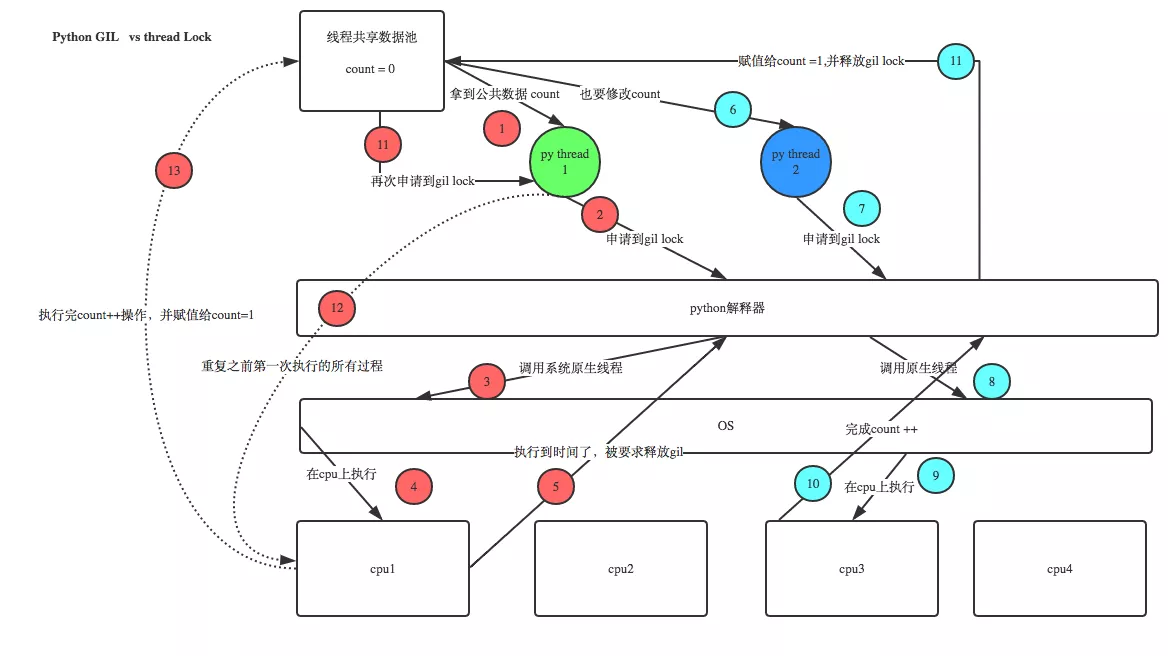
Then you asked again , Now that the user program has its own lock , What then? C python It also needs to be GIL Well ? Join in GIL The main reason is to reduce the complexity of program development , For example, now you write python Don't worry about memory recovery , because Python The interpreter helps you automatically and regularly recycle memory , You can understand it as python There is a separate thread in the interpreter , Every time it starts wake up Do a global poll to see what memory data can be emptied , Now your own program The thread and py The interpreter's own threads run concurrently , Suppose your thread deletes a variable ,py The garbage collection thread of the interpreter is in the process of clearing this variable clearing moment , Maybe another thread just reassigns the memory space that hasn't been cleared yet , As a result, it is possible that the newly assigned data has been deleted , To solve similar problems ,python The interpreter is simply and roughly locked , When a thread is running , No one else can move , This solves the above problems , This is sort of Python The legacy of earlier versions .
RLock( Recursive lock )To put it bluntly, a large lock also contains child locks
import threading, timedef run1(): lock.acquire() print("grab the first part data") global num num += 1 lock.release() return numdef run2(): lock.acquire() print("grab the second part data") global num2 num2 += 1 lock.release() return num2def run3(): lock.acquire() res = run1() print('--------between run1 and run2-----') res2 = run2() lock.release() print(res, res2)if __name__ == '__main__': num, num2 = 0, 0 lock = threading.RLock() for i in range(3): t = threading.Thread(target=run3) t.start()while threading.active_count() != 1: print(threading.active_count())else: print('----all threads done---') print(num, num2)
In the process of development, it should be noted that some operations default to Thread safe ( The lock mechanism is integrated inside ), When we use, we don't need to reprocess through the lock , for example :
import threadingdata_list = []lock_object = threading.RLock()def task(): print(" Start ") for i in range(1000000): data_list.append(i) print(len(data_list))for i in range(2): t = threading.Thread(target=task) t.start()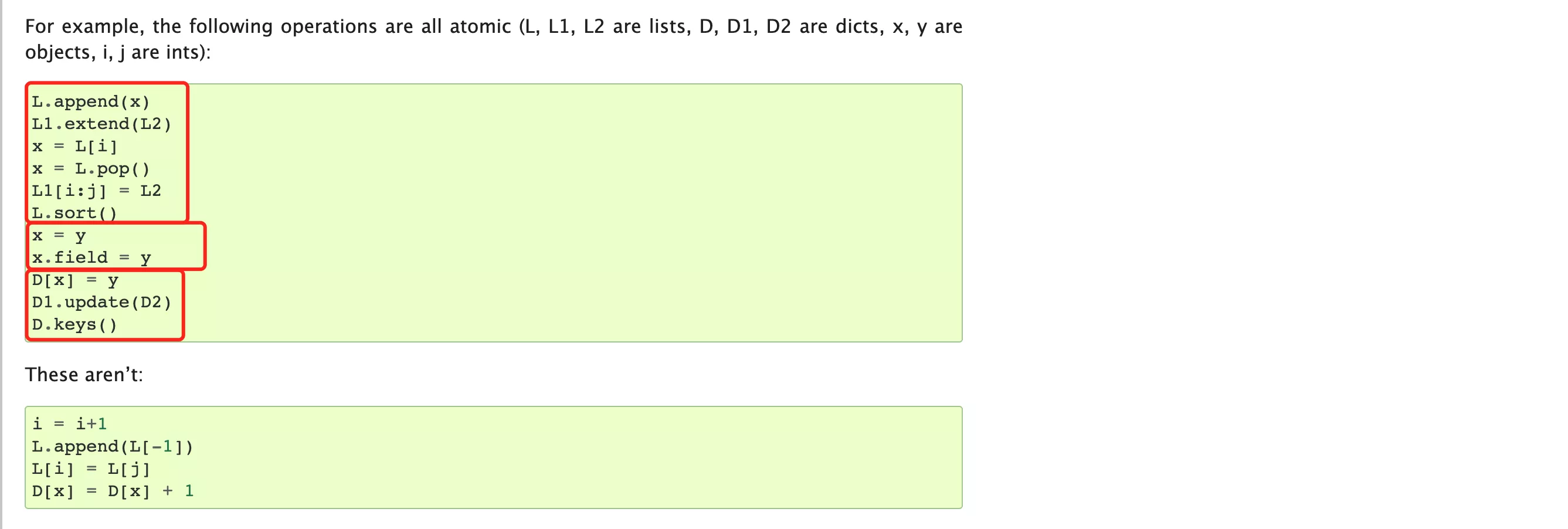
Semaphore( Semaphore )
Mutex allows only one thread to modify data at the same time , and Semaphore It allows a certain number of threads to modify data at the same time , For example, there are three pits in the toilet , Only three people are allowed to go to the bathroom at most , The people behind can only go in when the people in front come out .
Code demonstration :
# -*- coding:GBK -*-import threadingimport timesum_1 = 0def run(i): global sum_1 time.sleep(1) # lock.acquire() semaphore.acquire() sum_1 += 1 print(" Threads %s coming , And modify the sum_1 The value of is :%s" % (i, sum_1)) semaphore.release() # lock.release()# lock = threading.Lock()semaphore = threading.BoundedSemaphore(5)for x in range(10): t = threading.Thread(target=run, args=(x,)) t.start()while threading.active_count() != 1: passprint(" Program end ")Event( event )adopt Event To realize the interaction between two or more threads , Here is an example of a traffic light , That is to start a thread to do traffic lights , Generate several threads to make the vehicle , Stop at the red light , The rules of green light .
Four common methods
set() # Set the flag bit to True
clear() # Clear flag bit ( Change the flag bit to false)
is_set() # Detection flag bit , If the flag bit is set , return True, Otherwise return to False
wait() # Wait for the flag bit to be set True The program continues to run
Code demonstration :
# -*- coding:utf-8 -*-import threadingimport timedef light(): count = 1 event.set() # Set flag bit True while True: if count <= 10: print(" It's green now ") time.sleep(1) elif count <= 15: print(" It's a red light ") event.clear() # Clear flag bit ( Change the flag bit to false) time.sleep(1) else: count = 0 event.set() count += 1def car(name): while True: if event.is_set(): print("----------%s Taking off -------------" % name) time.sleep(1) else: print("---------%s Waiting for the red light ---------------" % name) event.wait() # Wait for the flag bit to be set True The program continues to run event = threading.Event()light_1 = threading.Thread(target=light)light_1.start()for x in range(5): car_1 = threading.Thread(target=car, args=(" Mazda "+str(x),)) car_1.start()
Traffic light cases
Queue( queue )
queue.Queue(maxsize=0)# queue : fifo maxsize: Set the size of the queue queue.LifoQueue(maxsize=0)##last in fisrt out maxsize: Set the size of the queue queue.PriorityQueue(maxsize=0)# Priority queues can be set when storing data , By priority ( Lowest first ) maxsize: Set the size of the queue exceptionqueue.Empty
Exception raised when non-blockingget()(orget_nowait()) is called on aQueueobject which is empty.
When calling nonblocking on an empty queue object get()( or get_nowait()) when , There will be exceptions .
exceptionqueue.Full
Exception raised when non-blockingput()(orput_nowait()) is called on aQueueobject which is full.
When non blocking put()( or put_nowait()) An exception that is thrown when a call is made to a full queue object .
import queue# Instantiate the queue object q = queue.Queue(3)print(q.qsize()) # Get the length of data in the queue print(q.empty()) # If the queue is empty , return True, Otherwise return to False( unreliable !)print(q.full()) # If the queue is full , return True, Otherwise return to False( unreliable !)."""Queue.put(item, block=True, timeout=None) It can be abbreviated :Queue.put(item, True, 5) Put the item in the queue . If optional args block by true( The default value is ), also timeout by None( The default value is ), Block if necessary , Until there is a free slot . If timeout It's a positive number , It blocks at most timeout second , If there is no free slot during this period , The cause Full abnormal . otherwise (block by false), If a free slot is available immediately , Just put an item on the queue , Otherwise, it will cause Full abnormal ( Ignore timeout in this case )."""q.put(1) # data “1” Enter the queue q.put("nihao") # data "nihao" Enter the queue q.put("456ni", block=True, timeout=5)''' Put an item in the queue , Do not block . Queue only if there is free space . Otherwise, it will cause Full abnormal .'''# q.put_nowait(123)'''Queue.get(block=True, timeout=None) It can be abbreviated :Queue.get(True, 3) Deletes and returns an item from the queue . If optional args'block' by True( Default ),'timeout' For nothing ( Default ). Will block if necessary , Until a project is available . If 'timeout' It is a non negative number , It blocks at most 'timeout' second , If no items are available during this period , The cause Empty abnormal . otherwise ('block' by False), If an item is immediately available , Returns an item . Otherwise trigger Empty abnormal ('timeout' Neglected in this case ).'''print(q.get())print(q.get())print(q.get())print(q.get(block=True, timeout=2))''' Remove and return an item from the queue , Without blocking . Only when an item is immediately available , To get a project . Otherwise trigger Empty abnormal .'''# print(q.get_nowait())Producer consumer model
Using producer and consumer patterns in concurrent programming can solve most concurrent problems . This mode improves the overall processing speed of the program by balancing the working capacity of the production thread and the consumption thread .
Why use the producer and consumer model
In the world of threads , The producer is the thread that produces the data , The consumer is the thread that consumes the data . In multi-threaded development , If the producer processes it quickly , Consumers are slow to process , Then the producer must wait for the consumer to finish processing , To continue to produce data . Same thing , If the consumer has more processing power than the producer , Then the consumer must wait for the producer . To solve this problem producer and consumer patterns were introduced .
What is the producer consumer model
The producer-consumer pattern solves the problem of strong coupling between producer and consumer through a container . Producers and consumers do not communicate directly with each other , Instead, it communicates by blocking the queue , So producers don't have to wait for consumers to process their data , Throw it directly into the blocking queue , Consumers don't ask producers for data , I'm going to take it directly from the blocking queue , Blocking a queue is like a buffer , Balancing the processing power of producers and consumers .
# producer / consumer import threadingimport queueimport time# producer def producer(name): count = 1 while True: p.put("{} The bone {}".format(name, count)) print(" The bone {} By {} production ".format(count, name).center(60, "*")) count += 1 time.sleep(0.1)# consumer def consumer(name): while True: print("{} By {} Ate ".format(p.get(), name))# Instantiate the queue object p = queue.Queue(10)# Create a producer thread producer_threading1 = threading.Thread(target=producer, args=(" Fly sb ",))producer_threading2 = threading.Thread(target=producer, args=("Alex",))# Create consumer thread consumer_threading1 = threading.Thread(target=consumer, args=(" Zhang San ",))consumer_threading2 = threading.Thread(target=consumer, args=(" Li Si ",))producer_threading1.start()producer_threading2.start()consumer_threading1.start()consumer_threading2.start() Thread pool Python3 The Chinese government officially provides thread pool .
The more threads, the better , Driving too much may lead to lower system performance , for example : The following code is not recommended to be written in project development .
import threadingdef task(video_url): passurl_list = ["www.xxxx-{}.com".format(i) for i in range(30000)]for url in url_list: t = threading.Thread(target=task, args=(url,)) t.start()# This method creates a thread to operate each time , Too many tasks created , There will be a lot of threads , Maybe the efficiency is reduced .Suggest : Use thread pool
import timefrom concurrent.futures import ThreadPoolExecutor # Parallel futures , Thread pool performer """pool = ThreadPoolExecutor(100)pool.submit( Function name , Parameters 1, Parameters 2, Parameters ...)"""def task(video_url, num): print(" Start the mission ", video_url, num) # Start the mission www.xxxx-299.com 3 time.sleep(1)# Creating a thread pool , Maintain up to 10 Threads threadpool = ThreadPoolExecutor(10)# Generate 300 website , And put it on the list url_list = ["www.xxxx-{}.com".format(i) for i in range(300)]for url in url_list: """ Submit a task in the thread pool , If there are idle threads in the thread pool , Then assign a thread to execute , After execution, return the thread to the thread pool , If there are no idle threads , Is waiting for . Pay attention to waiting , Independent of the main thread , The main thread is still executing . """ threadpool.submit(task, url, 3)print(" Waiting for the tasks in the thread pool to complete ······")threadpool.shutdown(True) # Wait until the tasks in the thread pool are executed , It's going on print("END")
After the task is completed , Do something else :
""" Thread pool callback """import timeimport randomfrom concurrent.futures import ThreadPoolExecutordef task(video_url): print(" Start the mission ", video_url) time.sleep(1) return random.randint(0, 10) # Encapsulate the results into a Futuer object , Return to the thread pool def done(response): # response Namely futuer object , That is to say task The return value of is divided into two parts Futuer object print(" After the mission is completed , Function of callback ", response.result()) # namely Futuer.result(): Take out task The return value of # Creating a thread pool threadpool = ThreadPoolExecutor(10)url_list = ["www.xxxx-{}.com".format(i) for i in range(5)]for url in url_list: futuer = threadpool.submit(task, url) # futuer By task Return one Future object , There's a record in it task The return value of futuer.add_done_callback(done) # Callback done function , The performer is still a child thread # advantage : Can do division of labor , for example :task Specially download ,done Specifically write the downloaded data to the local file .