進程:正在運行的程序,QQ 360 ......
線程:就是進程中一條執行程序的執行路徑,一個程序至少有一條執行路徑。(360中的殺毒 電腦體檢 電腦清理 同時運行的話就需要開啟多條路徑)
每個線程都有自己需要運行的內容,而這些內容可以稱為線程要執行的任務。
開啟多線程是為了同時運行多部分代碼。
好處:解決了多部分需要同時運行的問題
弊端:如果線程過多,會導致效率很低(因為程序的執行都是CPU做著隨機 快速切換來完成的)
線程與進程的區別
線程共享內存,進程獨立內存線程啟動速度塊,進程啟動速度慢,運行時速度沒有可比性同一個進程的線程間可以直接交流,兩個進程想通信,必須通過一個中間代理來實現創建新線程很簡單,創建新進程需要對其父進程進行一次克隆一個線程可以控制和操作同一線程裡的其他線程,但是進程只能操作子進程threading模塊
多線程的使用方式一:直接使用
# -*- coding:utf-8 -*-# 線程使用的方式一import threadingimport time# 需要多線程運行的函數def fun(args): print("我是線程%s" % args) time.sleep(2) print("線程%s運行結束" % args)# 創建線程t1 = threading.Thread(target=fun, args=(1,))t2 = threading.Thread(target=fun, args=(2,))start_time = time.time()t1.start()t2.start()end_time = time.time()print("兩個線程一共的運行時間為:", end_time-start_time)print("主線程結束")"""運行結果:我是線程1我是線程2兩個線程一共的運行時間為: 0.0010077953338623047主線程結束線程1運行結束線程2運行結束"""線程的第二種使用方式:繼承式調用
# 繼承式調用import threadingimport timeclass MyThreading(threading.Thread): def __init__(self, name): super(MyThreading, self).__init__() self.name = name # 線程要運行的代碼 def run(self): print("我是線程%s" % self.name) time.sleep(2) print("線程%s運行結束" % self.name)t1 = MyThreading(1)t2 = MyThreading(2)start_time = time.time()t1.start()t2.start()end_time = time.time()print("兩個線程一共的運行時間為:", end_time-start_time)print("主線程結束")"""運行結果:我是線程1我是線程2兩個線程一共的運行時間為: 0.0010724067687988281主線程結束線程2運行結束線程1運行結束"""守護線程與join方法在Python多線程編程中,join方法的作用式線程同步。
守護線程,是為守護別人而存在的,當設置為守護線程後,被守護的主線程不存在後,守護線程也自然不存在。
第一種:python多線程默認情況
Python多線程默認情況(設置線程setDaemon(False)),主線程執行完自己的任務後,就退出了,此時子線程會繼續執行自己的任務,直到子線程任務結束代碼演示:threading中的兩個創建多線成的例子都是。第二種:開啟守護線程
開啟線程的setDaemon(True)),設置子線程為守護線程,實現主程序結束,子程序立馬全部結束功能代碼演示:# 守護線程import threadingimport timeclass MyThreading(threading.Thread): def __init__(self, name): super(MyThreading, self).__init__() self.name = name # 線程要運行的代碼 def run(self): print("我是線程%s" % self.name) time.sleep(2) print("線程%s運行結束" % self.name)t1 = MyThreading(1)t2 = MyThreading(2)start_time = time.time()t1.setDaemon(True)t1.start()t2.setDaemon(True)t2.start()end_time = time.time()print("兩個線程一共的運行時間為:", end_time-start_time)print("主線程結束")注意:如果要設置為守護線程,一定要在開啟線程之前,將該線程設置為守護線程
結論:主線程結束後,無論子線程1,2是否運行完成,都結束線程,不在繼續向下運行
第三種:加入join方法設置同步
當不給程序設置守護進程時,主程序將一直等待子程序全部運行完成才結束代碼演示:# join:線程同步import threadingimport timeclass MyThreading(threading.Thread): def __init__(self, name): super(MyThreading, self).__init__() self.name = name # 線程要運行的代碼 def run(self): print("我是線程%s" % self.name) time.sleep(3) print("線程%s運行結束" % self.name)threading_list = []start_time = time.time()for x in range(50): t = MyThreading(x) t.start() threading_list.append(t)for x in threading_list: x.join() # 為線程開啟同步end_time = time.time()print("50個線程一共的運行時間為:", end_time-start_time)print("主線程結束")結論:主線程等待50個子線程全部執行完成才結束。
線程鎖(互斥鎖Mutex)一個進程下可以啟用多個線程,多個線程共享父進程的內存空間,也就意味著每個線程可以訪問同一份數據,此時如果多個線程同時要修改一份數據,會出現什麼狀況?
代碼演示:# -*- coding:utf8 -*-import threadingimport timenum = 100threading_list = []def fun(): global num print("get num:", num) num += 1 time.sleep(1)for x in range(200): t = threading.Thread(target=fun) t.start() threading_list.append(t)for x in threading_list: x.join()print("nun:", num)結論:運行結果可能會出現num<300的情況
正常來講,這個num結果應該是300, 但在python 2.7上多運行幾次,會發現,最後打印出來的num結果不總是300,為什麼每次運行的結果不一樣呢? 哈,很簡單,假設你有A,B兩個線程,此時都 要對num 進行加1操作, 由於2個線程是並發同時運行的,所以2個線程很有可能同時拿走了num=100這個初始變量交給cpu去運算,當A線程去處完的結果是101,但此時B線程運算完的結果也是101,兩個線程同時CPU運算的結果再賦值給num變量後,結果就都是101。那怎麼辦呢? 很簡單,每個線程在要修改公共數據時,為了避免自己在還沒改完的時候別人也來修改此數據,可以給這個數據加一把鎖, 這樣其它線程想修改此數據時就必須等待你修改完畢並把鎖釋放掉後才能再訪問此數據。
*注:不要在3.x上運行,不知為什麼,3.x上的結果總是正確的,可能是自動加了鎖
加鎖版本:
import randomimport threadingimport timenum = 100threading_list = []def fun(): global num time.sleep(random.random()) lock.acquire() # 加鎖 print("get num:", num, threading.current_thread()) num += 1 lock.release() # 釋放鎖# 實例化鎖對象lock = threading.Lock()for x in range(200): t = threading.Thread(target=fun) t.start() threading_list.append(t)for x in threading_list: x.join()print("num:", num)
GIL VS Lock
機智的同學可能會問到這個問題,就是既然你之前說過了,Python已經有一個GIL來保證同一時間只能有一個線程來執行了,為什麼這裡還需要lock? 注意啦,這裡的lock是用戶級的lock,跟那個GIL沒關系 ,具體我們通過下圖來看一下+配合我現場講給大家,就明白了。
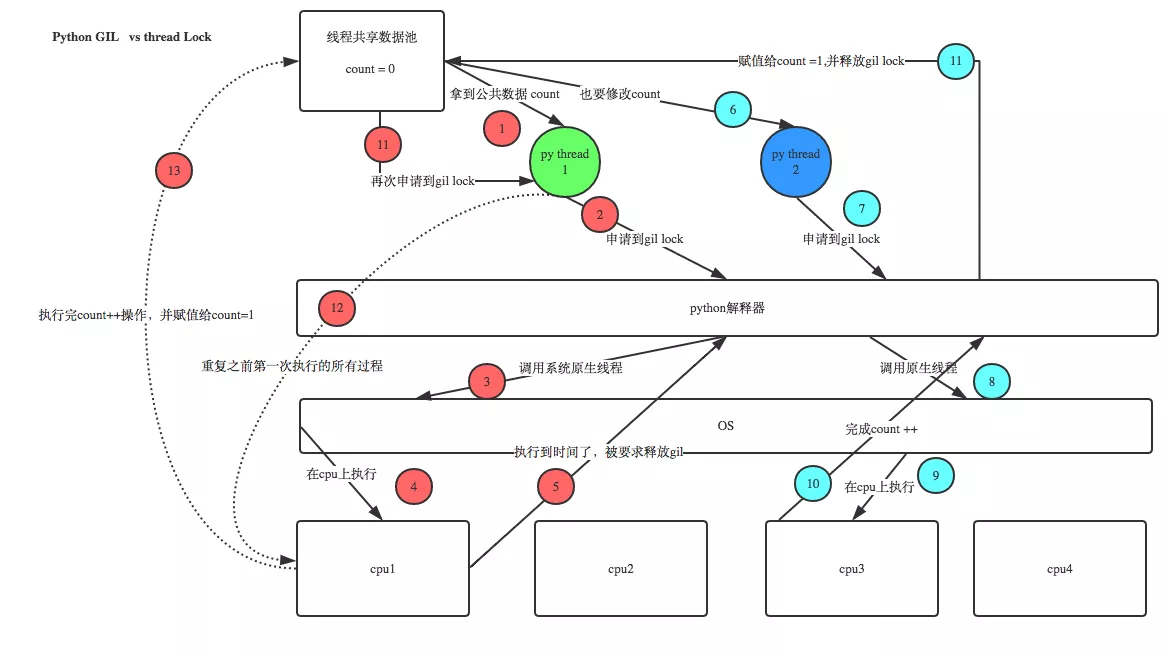
那你又問了, 既然用戶程序已經自己有鎖了,那為什麼C python還需要GIL呢?加入GIL主要的原因是為了降低程序的開發的復雜度,比如現在的你寫python不需要關心內存回收的問題,因為Python解釋器幫你自動定期進行內存回收,你可以理解為python解釋器裡有一個獨立的線程,每過一段時間它起wake up做一次全局輪詢看看哪些內存數據是可以被清空的,此時你自己的程序 裡的線程和 py解釋器自己的線程是並發運行的,假設你的線程刪除了一個變量,py解釋器的垃圾回收線程在清空這個變量的過程中的clearing時刻,可能一個其它線程正好又重新給這個還沒來及得清空的內存空間賦值了,結果就有可能新賦值的數據被刪除了,為了解決類似的問題,python解釋器簡單粗暴的加了鎖,即當一個線程運行時,其它人都不能動,這樣就解決了上述的問題, 這可以說是Python早期版本的遺留問題。
RLock(遞歸鎖)說白了就是在一個大鎖中還要再包含子鎖
import threading, timedef run1(): lock.acquire() print("grab the first part data") global num num += 1 lock.release() return numdef run2(): lock.acquire() print("grab the second part data") global num2 num2 += 1 lock.release() return num2def run3(): lock.acquire() res = run1() print('--------between run1 and run2-----') res2 = run2() lock.release() print(res, res2)if __name__ == '__main__': num, num2 = 0, 0 lock = threading.RLock() for i in range(3): t = threading.Thread(target=run3) t.start()while threading.active_count() != 1: print(threading.active_count())else: print('----all threads done---') print(num, num2)
在開發的過程中要注意有些操作默認都是 線程安全的(內部集成了鎖的機制),我們在使用的時無需再通過鎖再處理,例如:
import threadingdata_list = []lock_object = threading.RLock()def task(): print("開始") for i in range(1000000): data_list.append(i) print(len(data_list))for i in range(2): t = threading.Thread(target=task) t.start()
Semaphore(信號量)
互斥鎖同時只允許一個線程修改數據,而Semaphore是同時允許一定數量的線程修改數據,比如廁所有三個坑,那最多只允許三個人上廁所,後面的人只能等前面的人出來才能進去。
代碼演示:
# -*- coding:GBK -*-import threadingimport timesum_1 = 0def run(i): global sum_1 time.sleep(1) # lock.acquire() semaphore.acquire() sum_1 += 1 print("線程%s來了,並修改了sum_1的值為:%s" % (i, sum_1)) semaphore.release() # lock.release()# lock = threading.Lock()semaphore = threading.BoundedSemaphore(5)for x in range(10): t = threading.Thread(target=run, args=(x,)) t.start()while threading.active_count() != 1: passprint("程序結束")Event(事件)通過Event來實現兩個或多個線程間的交互,下面是一個紅綠燈的例子,即起動一個線程做交通指揮燈,生成幾個線程做車輛,車輛行駛按紅燈停,綠燈行的規則。
四個常用方法
set() # 設置標志位為 True
clear() # 清空標志位(將標志位改為false)
is_set() # 檢測標志位,如果標志位被設置,返回True,否則返回False
wait() # 等待標志位被設置位True程序才繼續往下運行
代碼演示:
# -*- coding:utf-8 -*-import threadingimport timedef light(): count = 1 event.set() # 設置標志位 True while True: if count <= 10: print("現在是綠燈") time.sleep(1) elif count <= 15: print("現在是紅燈") event.clear() # 清空標志位(將標志位改為false) time.sleep(1) else: count = 0 event.set() count += 1def car(name): while True: if event.is_set(): print("----------%s在起飛-------------" % name) time.sleep(1) else: print("---------%s在等紅燈---------------" % name) event.wait() # 等待標志位被設置位True程序才繼續往下運行event = threading.Event()light_1 = threading.Thread(target=light)light_1.start()for x in range(5): car_1 = threading.Thread(target=car, args=("馬自達"+str(x),)) car_1.start()
紅綠燈案例
Queue(隊列)
queue.Queue(maxsize=0)#隊列:先進先出 maxsize:設置隊列的大小queue.LifoQueue(maxsize=0)##last in fisrt out maxsize:設置隊列的大小queue.PriorityQueue(maxsize=0)#存儲數據時可設置優先級的隊列,按優先級順序(最低的先) maxsize:設置隊列的大小 exceptionqueue.Empty
Exception raised when non-blockingget()(orget_nowait()) is called on aQueueobject which is empty.
當在一個空的隊列對象上調用非阻塞的get()(或get_nowait())時,會產生異常。
exceptionqueue.Full
Exception raised when non-blockingput()(orput_nowait()) is called on aQueueobject which is full.
當非阻塞的put()(或put_nowait())被調用到一個已滿的隊列對象上時引發的異常。
import queue# 實例化隊列對象q = queue.Queue(3)print(q.qsize()) # 獲取隊列內數據的長度print(q.empty()) # 如果隊列是空的,返回True,否則返回False(不可靠!)print(q.full()) # 如果隊列已滿,返回True,否則返回False(不可靠!)。"""Queue.put(item, block=True, timeout=None)可以簡寫:Queue.put(item, True, 5)將項目放入隊列。如果可選的args block為true(默認值),並且timeout為None(默認值),必要時進行阻塞,直到有空閒的槽。如果timeout是一個正數,它最多阻斷timeout秒,如果在這段時間內沒有空閒槽,則引發Full異常。否則(block為false),如果有空閒的槽立即可用,就在隊列上放一個項目,否則就引發Full異常(在這種情況下忽略超時)。"""q.put(1) # 數據“1”進入隊列q.put("nihao") # 數據"nihao"進入隊列q.put("456ni", block=True, timeout=5)'''將一個項目放入隊列中,不進行阻斷。只有在有空閒位置的情況下才排隊。否則會引發Full異常。'''# q.put_nowait(123)'''Queue.get(block=True, timeout=None)可以簡寫:Queue.get(True, 3)從隊列中刪除並返回一個項目。如果可選的args'block'為True(默認),'timeout'為無(默認)。 就會在必要時阻塞,直到有一個項目可用。 如果'timeout'是非負數,它最多阻斷'timeout'秒,如果在這段時間內沒有項目可用,則引發Empty異常。否則('block'為False),如果有一個項目立即可用,則返回一個項目。 否則引發Empty異常('timeout'被忽略了在這種情況下)。'''print(q.get())print(q.get())print(q.get())print(q.get(block=True, timeout=2))'''從隊列中移除並返回一個項目,而不阻塞。只有當一個項目立即可用時,才會得到一個項目。否則引發Empty異常。'''# print(q.get_nowait())生產者消費者模型
在並發編程中使用生產者和消費者模式能夠解決絕大多數並發問題。該模式通過平衡生產線程和消費線程的工作能力來提高程序的整體處理數據的速度。
為什麼要使用生產者和消費者模式
在線程世界裡,生產者就是生產數據的線程,消費者就是消費數據的線程。在多線程開發當中,如果生產者處理速度很快,而消費者處理速度很慢,那麼生產者就必須等待消費者處理完,才能繼續生產數據。同樣的道理,如果消費者的處理能力大於生產者,那麼消費者就必須等待生產者。為了解決這個問題於是引入了生產者和消費者模式。
什麼是生產者消費者模式
生產者消費者模式是通過一個容器來解決生產者和消費者的強耦合問題。生產者和消費者彼此之間不直接通訊,而通過阻塞隊列來進行通訊,所以生產者生產完數據之後不用等待消費者處理,直接扔給阻塞隊列,消費者不找生產者要數據,而是直接從阻塞隊列裡取,阻塞隊列就相當於一個緩沖區,平衡了生產者和消費者的處理能力。
# 生產者/消費者import threadingimport queueimport time# 生產者def producer(name): count = 1 while True: p.put("{}骨頭{}".format(name, count)) print("骨頭{}被{}生產".format(count, name).center(60, "*")) count += 1 time.sleep(0.1)# 消費者def consumer(name): while True: print("{}被{}吃掉了".format(p.get(), name))# 實例化隊列對象p = queue.Queue(10)# 創建生產者線程producer_threading1 = threading.Thread(target=producer, args=("飛某人",))producer_threading2 = threading.Thread(target=producer, args=("Alex",))# 創建消費者線程consumer_threading1 = threading.Thread(target=consumer, args=("張三",))consumer_threading2 = threading.Thread(target=consumer, args=("李四",))producer_threading1.start()producer_threading2.start()consumer_threading1.start()consumer_threading2.start()線程池Python3中官方才正式提供線程池。
線程不是開的越多越好,開的多了可能會導致系統的性能更低了,例如:如下的代碼是不推薦在項目開發中編寫。
import threadingdef task(video_url): passurl_list = ["www.xxxx-{}.com".format(i) for i in range(30000)]for url in url_list: t = threading.Thread(target=task, args=(url,)) t.start()# 這種每次都創建一個線程去操作,創建任務的太多,線程就會特別多,可能效率反倒降低了。建議:使用線程池
import timefrom concurrent.futures import ThreadPoolExecutor # 並行期貨,線程池執行者"""pool = ThreadPoolExecutor(100)pool.submit(函數名,參數1,參數2,參數...)"""def task(video_url, num): print("開始執行任務", video_url, num) # 開始執行任務 www.xxxx-299.com 3 time.sleep(1)# 創建線程池,最多維護10個線程threadpool = ThreadPoolExecutor(10)# 生成300網址,並放入列表url_list = ["www.xxxx-{}.com".format(i) for i in range(300)]for url in url_list: """ 在線程池中提交一個任務,線程池如果有空閒線程,則分配一個線程去執行,執行完畢後在將線程交還給線程池, 如果沒有空閒線程,則等待。注意在等待時,與主線程無關,主線程依然在繼續執行。 """ threadpool.submit(task, url, 3)print("等待線程池中的任務執行完畢中······")threadpool.shutdown(True) # 等待線程池中的任務執行完畢後,在繼續執行print("END")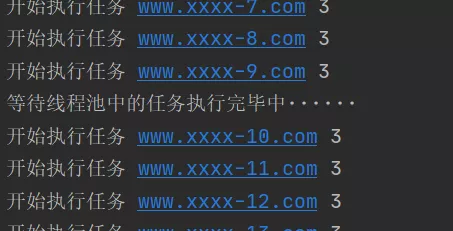
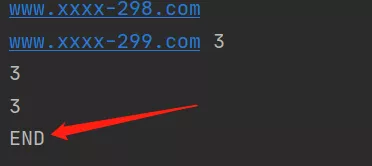
任務執行完任務,再干點其他事:
"""線程池的回調"""import timeimport randomfrom concurrent.futures import ThreadPoolExecutordef task(video_url): print("開始執行任務", video_url) time.sleep(1) return random.randint(0, 10) # 將結果封裝成一個Futuer對象,返回給線程池def done(response): # response就是futuer對象,也就是task的返回值分裝的一個Futuer對象 print("任務執行完後,回調的函數", response.result()) # 即Futuer.result():取出task的返回值# 創建線程池threadpool = ThreadPoolExecutor(10)url_list = ["www.xxxx-{}.com".format(i) for i in range(5)]for url in url_list: futuer = threadpool.submit(task, url) # futuer是由task返回的一個Future對象,裡面有記錄task的返回值 futuer.add_done_callback(done) # 回調done函數,執行者依然是子線程# 優點:可以做分工,例如:task專門下載,done專門將下載的數據寫入本地文件。