The target site of this collection is aHVhbmd5ZTg4.com , The screenshot of the home page is as follows .
Find it on the official website 【 yellow x page 】 tab , Then we get the following interface , The information involved is as follows , Randomly find a public data .
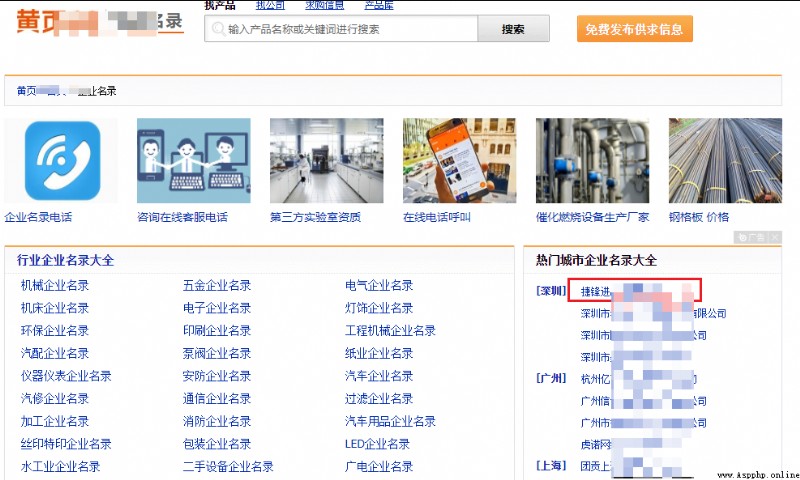
The contact person and contact number can be viewed on the company Yellow Page details page .

It is obvious that the mobile phone font is different from other fonts , After verification through the developer tool , Confirm that there is a font backcrawl .
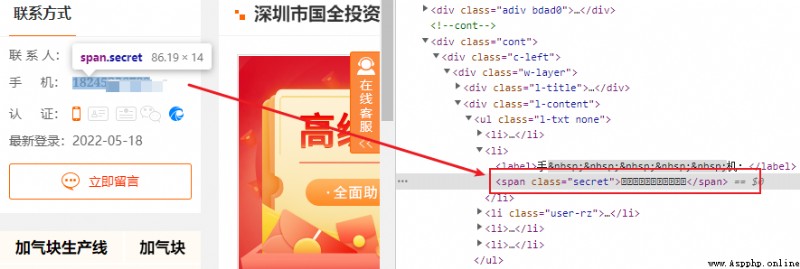
Save font file , Get the following font vector diagram .

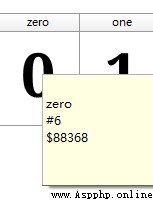
The result font code is fixed in English , Then the difficulty of reverse climbing of this font becomes extremely low .
You can find the font file in the web page source code through the developer tool , So let's write the relevant extraction code .
import re
import requests
import base64
from fontTools.ttLib import TTFont
url = 'https://b2b.huangye88.com/qiye1edkfp0964c7/'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.67 Safari/537.36'
}
res_text = requests.get(url=url, headers=headers).text
ba64 = re.findall('base64,(.*?)\"\)', res_text)[0]
# print(ba64)
data = base64.b64decode(ba64)
with open('./fonts/519.woff', 'wb') as f:
f.write(data)
font = TTFont('./fonts/519.woff')
font.saveXML('./fonts/519.xml')
After getting the font , The saved XML The documentation is as follows .

This case is over .
You are reading 【 Dream eraser 】 The blog of
Finished reading , You can praise it with a little hand
Find the error , Correct it in the direct comment area
The second part of the eraser 680 Original blog
From the date of order , Case study 5 Guaranteed renewal during the year
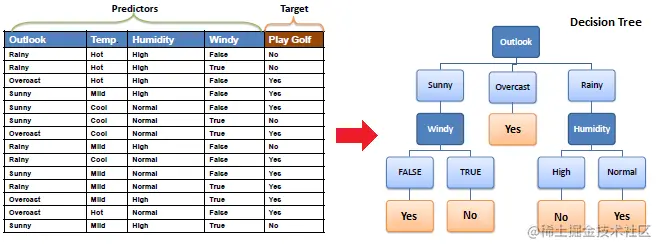 [fundamentals of machine learning] mathematical derivation + pure Python implementation of machine learning algorithm 4: ID3 algorithm of decision tree
[fundamentals of machine learning] mathematical derivation + pure Python implementation of machine learning algorithm 4: ID3 algorithm of decision tree
p{margin:10px 0}.markdown-body
 Python sorts dictionaries. After sorting, it is still a dictionary. Whats wrong
Python sorts dictionaries. After sorting, it is still a dictionary. Whats wrong
python Sort the dictionary , D