目錄
一、代碼組織方式及執行順序 3
二、問題描述 3
三、特征提取 4
(一)dat_risk 4
(二)dat_symbol 4
(三)dat_app 6
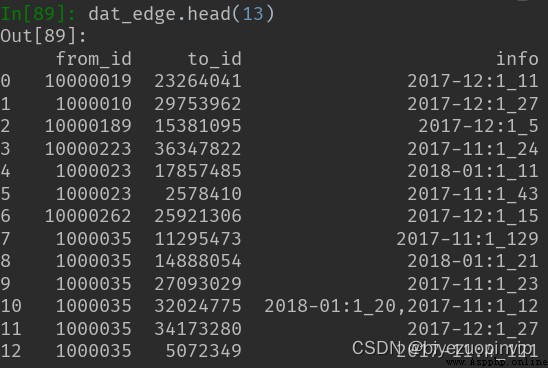
(四)dat_edge 7
四、用戶關聯圖的特征提取 13
(一)中心度類特征 13
(二)Louvain 社區聚類 13
五、標簽傳播 14
(一)一度聯系人 14
(二)二度聯系人 15
(三)一度路由 17
六、特征傳播 17
(一)特征概述 18
(二)數據描述 18
(三)特征提取 18
(四)特征評價 18
七、數據匯總及特征比較 18
八、特征排序與離散化 19
九、調參 19
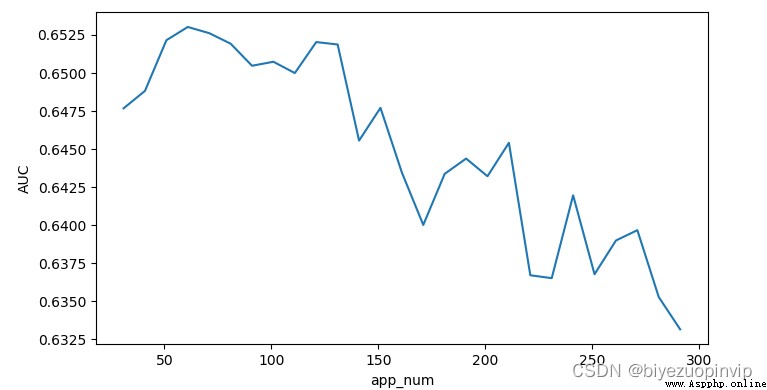
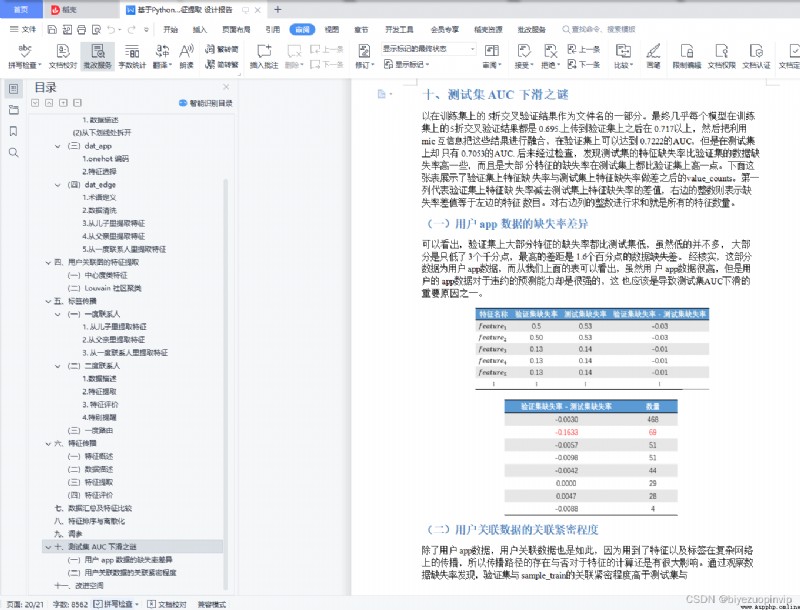
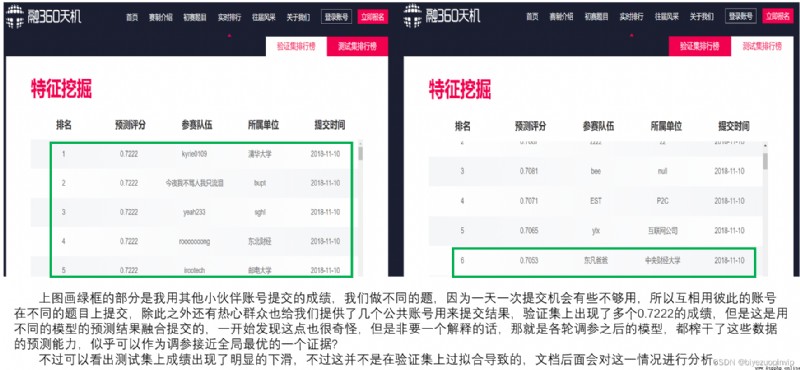
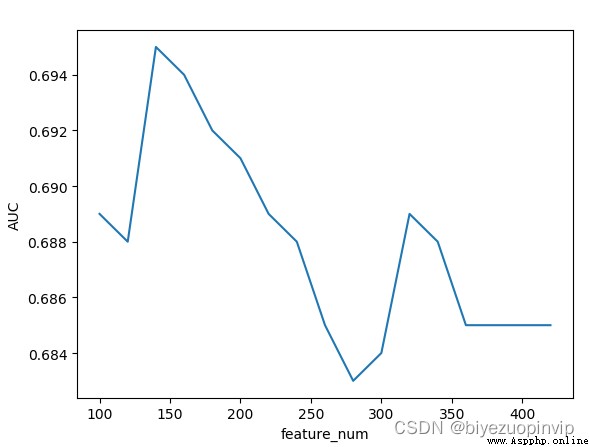
十、測試集 AUC 下滑之謎 21
(一)用戶 app 數據的缺失率差異 21
(二)用戶關聯數據的關聯緊密程度 21
十一、改進空間 22
一、代碼組織方式及執行順序
二、問題描述
在這裡說明是為了達成共識,同時也是為了統一符號表示,後面的講解都以此為基礎。 關於用戶特征的數據分為四部分(按照處理的難易程度排序,從易到難):
•(1)dat_risk
•(2)dat_symbol
•(3)dat_app
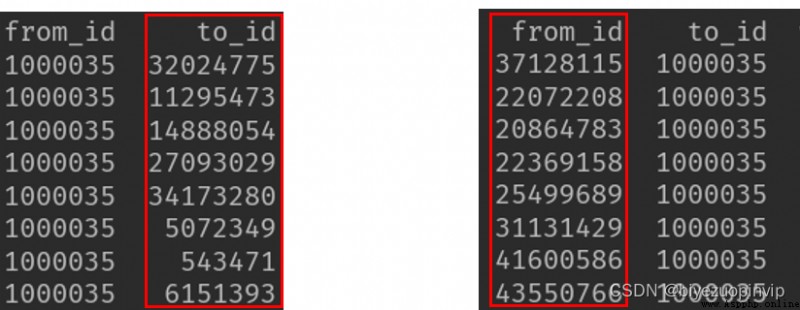
•(4)dat_edge
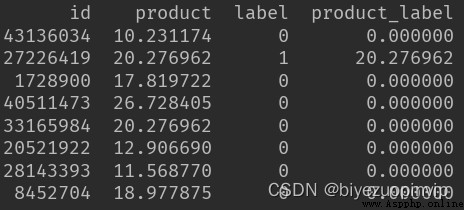
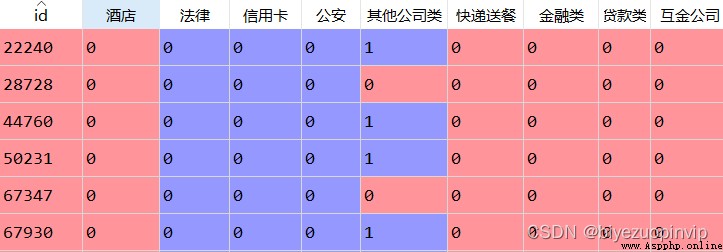
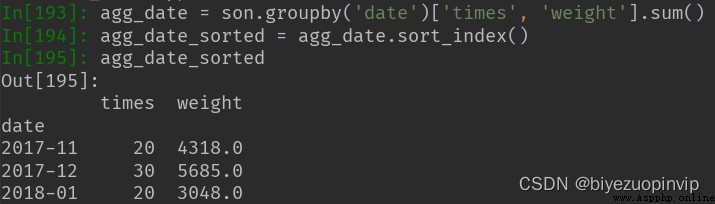
關於用戶標簽和訓練集、驗證集、測試集的數據: (1)sample_train(兩列: id、label) (2)valid_id(一列: id) (3)test_id(一列: id)
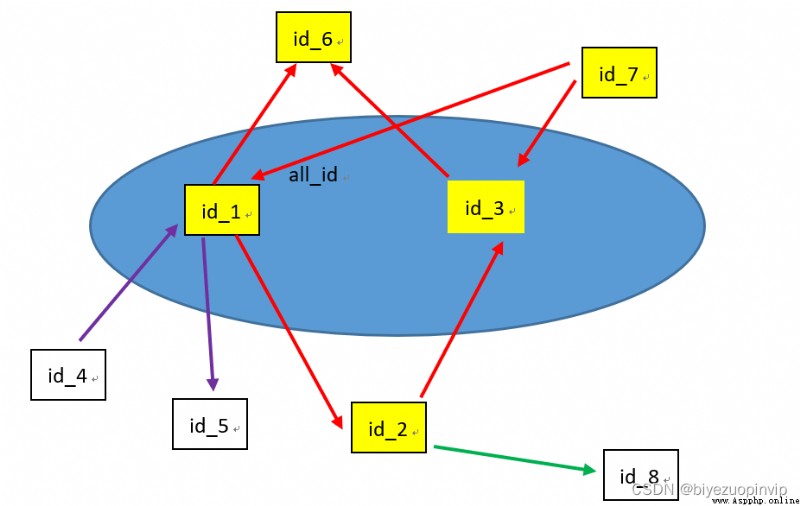
把 sample_train、valid_id、test_id 的 id 拼接起來,得到所有的 id,數據名稱記為 all_id, 數據格式為一個 28959*1 的 DataFrame.
三、特征提取
(一)dat_risk
輸出為 all_id_dat_risk
把 dat_risk 和 all_id 進行內連接:
all_id_dat_risk = pd.merge(all_id, dat_risk, on=‘id’, how=‘inner’)
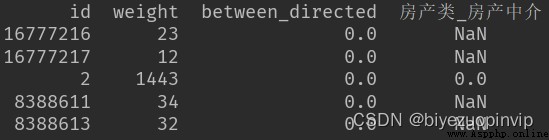
目的是找出 all_id 中每一個 id 的特征,當然有些 id 可能沒有這個特征,在最終的數據上表現為缺失值。
本文轉載自:http://www.biyezuopin.vip/onews.asp?id=16293