Use F12 open chrome Developer interface for , Then execute the page again , We can see that :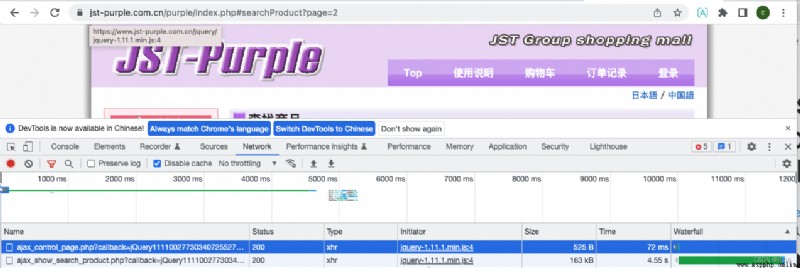
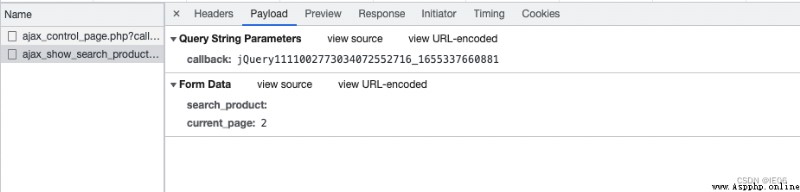
Click the one with the longest execution time ajax request , We can see the real request (headers in ) And parameters (payload in ) 了 :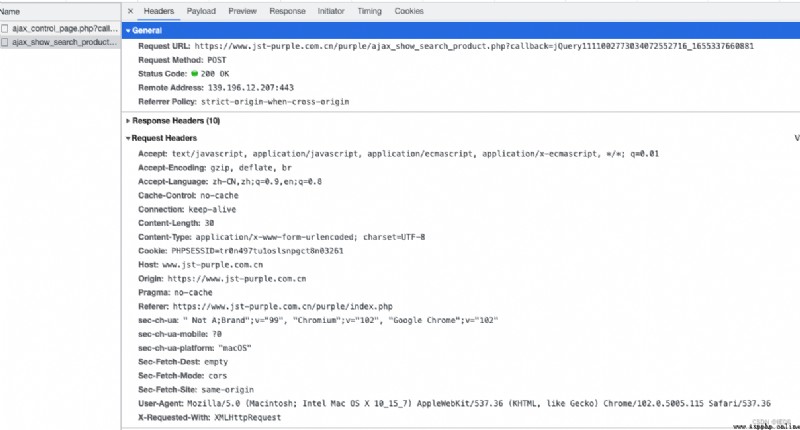
url:Header Medium request url
headers:Header Medium request headers
params:Payload Medium Query String Parameters
data:Payload Medium From Data
Compare the two pictures above , The code for crawling page information is as follows :
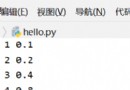
import requests
from tqdm import tqdm
headers={'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.5005.115 Safari/537.36',
'Referer': 'https://www.jst-purple.com.cn/purple/index.php',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Cookie':'PHPSESSID=tr0n497tu1oslsnpgct8n03261'}
url = "https://www.jst-purple.com.cn/purple/ajax_show_search_product.php"
params = {'callback':'jQuery1111007706371456432315_1655294131309'}
# Here we usually use multithreading to crawl web pages
for i in tqdm(range(1,248)):
rep=requests.post(url=url,params=params,data={"current_page":i},headers=headers)
html = rep.text...