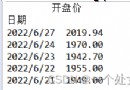
python in requests After sending the request , There is no way to carry out the javascript Code , So there is a lot of information that can't be crawled . Here is a tool for automated testing selenium, It can simulate the process of opening web pages . Use pip install You can install .
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
options = webdriver.ChromeOptions()
options.add_argument("--headless")
options.add_argument("start-maximized")
# Download it from the official website chromedriver
driver = webdriver.Chrome(executable_path =..., options = options)
# Wait for 5 Second , Let the page load
driver.implicitly_wait(5)
driver.get("https://www.jst-purple.com.cn/purple/index.php#searchProduct")
for page in range(1,247):
# Click the next button
next_page = WebDriverWait(driver, 15).until(EC.presence_of_element_located((By.LINK_TEXT, ' The next page ')))
next_page.click()
element = driver.find_element_by_id('div_content_sub')
for i in element.text.split('\n'):
......