To use bs4, First, install the corresponding package
pip install beautifulsoup4
The essence is through html The label in 、 Or the attribute in the tag is located in the content . This process can be repeated many times , For example, you can find a wide range of unique tags , And then locate the desired content . therefore , It is much easier to use than regular expressions , You just need to find the corresponding label .
- find( label , attribute = value ) Stop when you find the first one that matches , return bs object
- find_all( label , attribute = value ) Find all that match , Returns a list of
- because find The return is bs object , So you can continue to call find Until we find it . and find_all Back to the list , Usually only the last layer will use it , Then get the data through the list .
Several ways to write attributes :
because html The keywords of some tag attributes are followed by python The key words are the same ( for example class), Writing these attribute names directly will report python Grammar mistakes , therefore bs4 There are two ways to avoid this problem .
Earlier, we got all the information about a novel through regular expressions url, What we have to do here is Read and cycle through these url, And then use bs4 Match the content of the novel text .
Open any chapter , View source code , See which tag the text content is in I was a divine beast in Xianzong [ Wear books ] Network novel - The first 142 Chapter A great beauty 142 - Guide reading network
Fortunately here div id="articlecon" This property is unique , So we can easily get this content . But notice that it's not all text , There are still a lot of it <p></p> Labels need to be handled ( Later I found out here p Labels are unique , But this example is too special , We still use div Label learning for bs4 usage ).
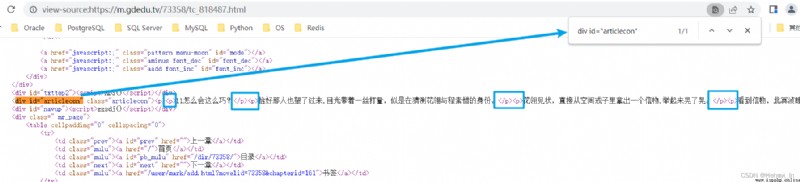
Take a link first , Try to match div id="articlecon" Part content
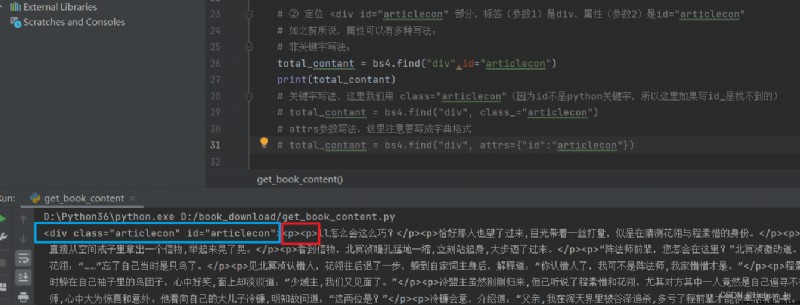
What follows is all about p In the label , So use find_all Match them all . Notice here that it has two layers p label , So first find once p label .
find_all Return a list , Each element is p The label and its contents , If you only want the content , Need to call again getText function . If you want the attributes in the tag , Then use list .get("href").
for example <a href=www.baidu.com> Baidu </a>
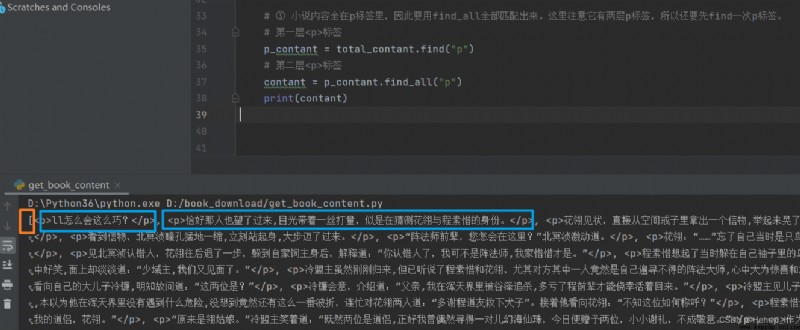
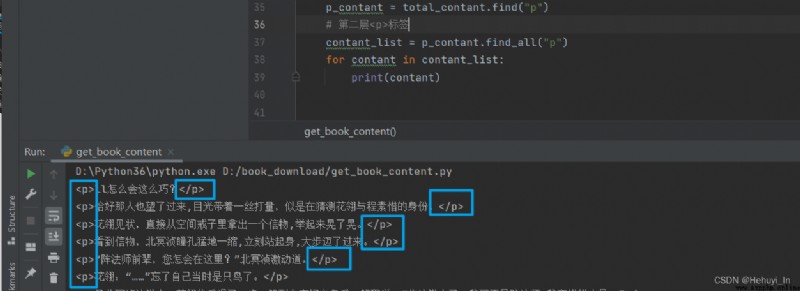
Loop out the contents , Let's see the difference
Direct output :
Use getText Method
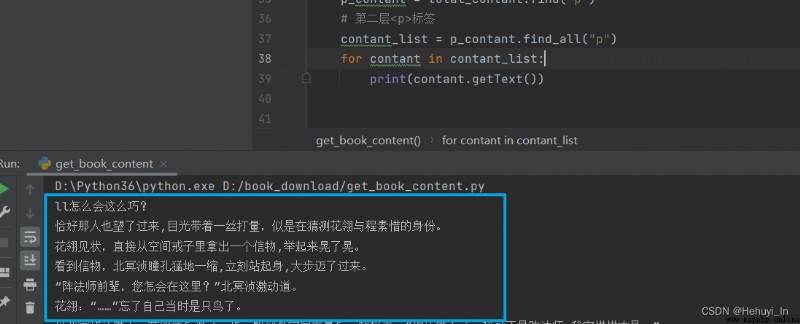
success ~~ Next, add the loop , You can output all the chapters
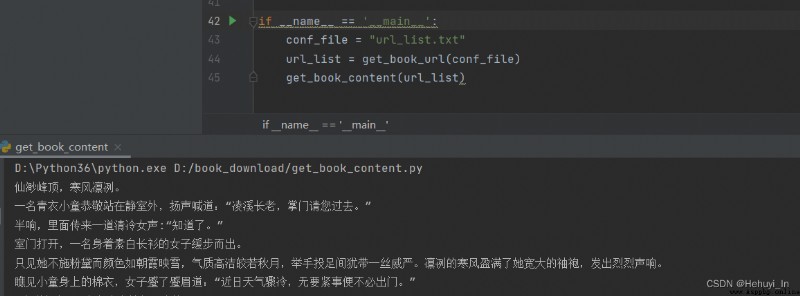
Then we save the output to txt In file , The novel download is complete ~
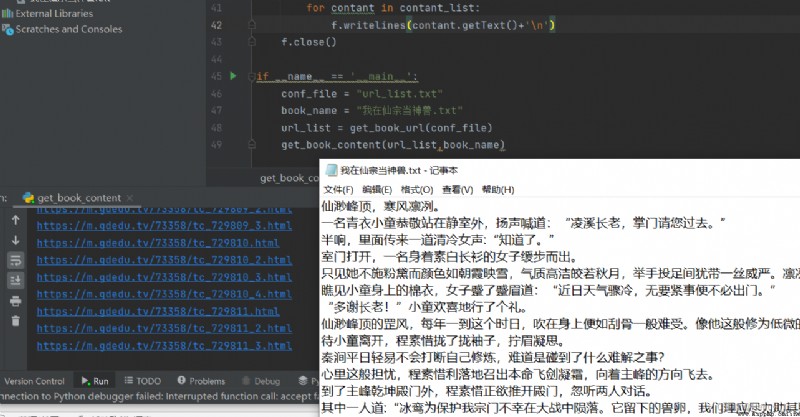
The code is as follows
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# @Time : 2022-06-13 22:26
# @Author: Hehuyi_In
# @File : get_book_content.py
import requests
from bs4 import BeautifulSoup
def get_book_url(conf_file):
f = open(conf_file)
url_list = f.read().splitlines()
f.close()
return url_list
def get_book_content(url_list,book_name):
f = open(book_name, 'a', encoding='utf-8')
for url in url_list:
print(url)
resp = requests.get(url)
# ① Source code of the page ( Parameters 1) hand bs4 Handle , obtain bs4 object ; Parameters 2 It indicates that what is passed in is html, Use html.parser analysis
bs4 = BeautifulSoup(resp.text,"html.parser")
# ② location <div id="articlecon" part , label ( Parameters 1) yes div, attribute ( Parameters 2) yes id="articlecon"
# As I said before , Attributes can be written in a variety of ways :
# Non keyword writing :
total_contant = bs4.find("div",id="articlecon")
# print(total_contant)
# Keyword writing , Here we use class="articlecon"( because id No python keyword , So if it says id_ I can't find it )
# total_contant = bs4.find("div", class_="articlecon")
# attrs Parameter writing , Note that it should be written in dictionary format
# total_contant = bs4.find("div", attrs={"id":"articlecon"})
# ③ The novel is all about p In the label , So use find_all Match them all . Notice here that it has two layers p label , So first find once p label .
# first floor <p> label
p_contant = total_contant.find("p")
# The second floor <p> label
contant_list = p_contant.find_all("p")
for contant in contant_list:
f.writelines(contant.getText()+'\n')
f.close()
if __name__ == '__main__':
conf_file = "url_list.txt"
book_name = " I was a divine beast in Xianzong .txt"
url_list = get_book_url(conf_file)
get_book_content(url_list,book_name)Fill in the screenshots in the two videos , These two examples have not been tested yet . A grab table data , A grab picture .
note - Grab table data
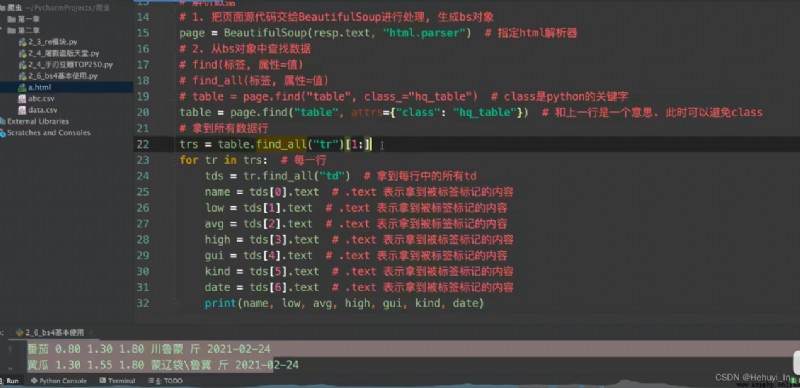
Picture capture : Go to the home page , Grab sub page HD pictures
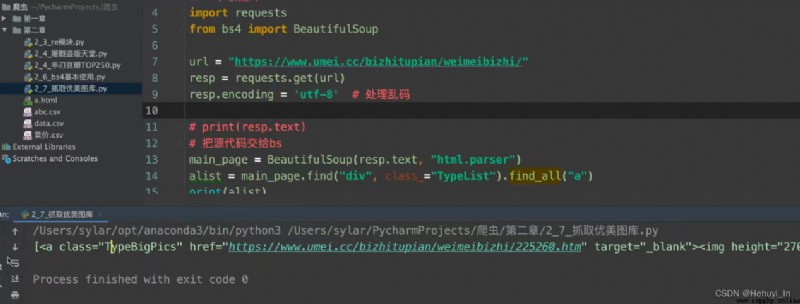
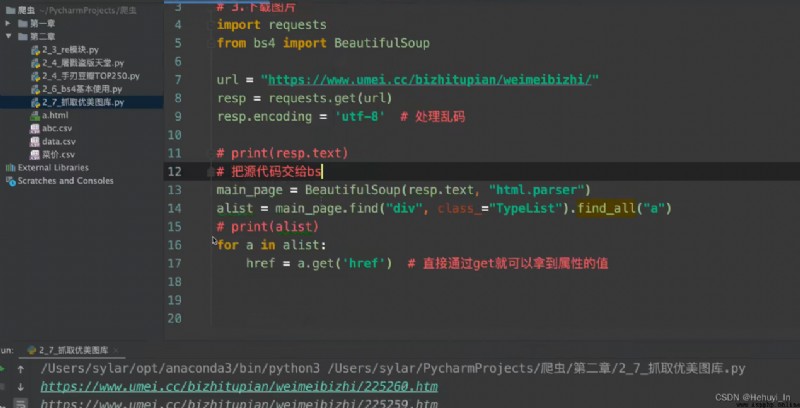
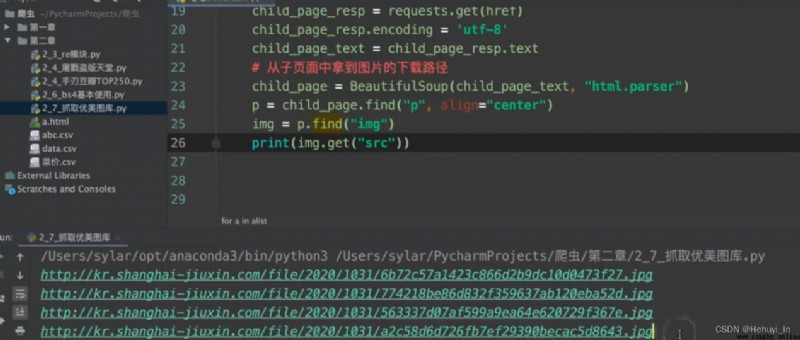
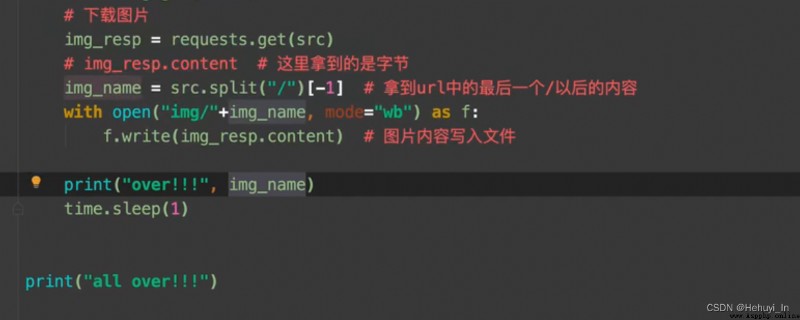
Reference resources :B Stop video P28-P32
2021 New year Python Reptile tutorial + Practical project cases ( Latest recording )_ Bili, Bili _bilibili