在先前,博主完成了GPU環境的配置,那麼今天博主來實驗一下使用GPU來運行我們的項目
使用cmd 輸入nvidia-smi查看GPU使用情況,下面是Linux裡面的一個顯示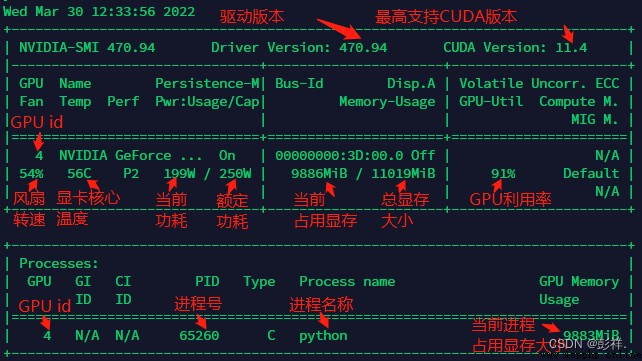
下面是我的運行狀態:
PS:在運行前需要安裝tensflow-gpu與CUDA,cuDNN對應好,這裡折磨了博主好久
https://tensorflow.google.cn/install/source_windows
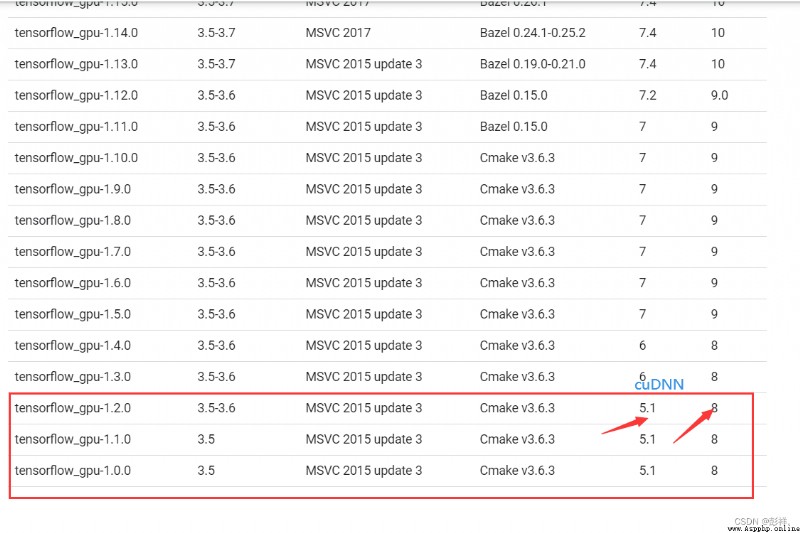
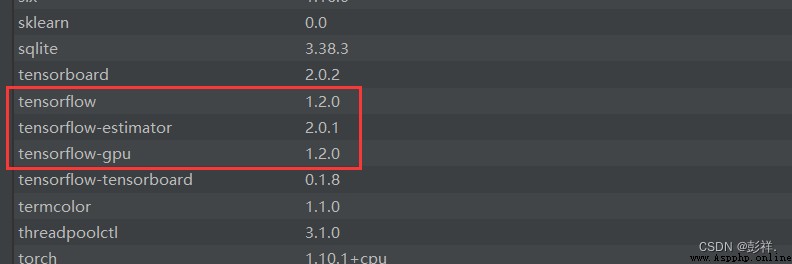
安裝對應的tensorflow-gpu
pip install tensorflow_gpu==1.2.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
import tensorflow as tf
tensorflow_version = tf.__version__
gpu_available = tf.test.is_gpu_available()
print('tensorflow version:',tensorflow_version, '\tGPU available:', gpu_available)
a = tf.constant([1.0, 2.0], name='a')
b = tf.constant([1.0, 2.0], name='b')
result = tf.add(a,b, name='add')
print(result)
import os
from tensorflow.python.client import device_lib
os.environ["TF_CPP_MIN_LOG_LEVEL"] = "99"
if __name__ == "__main__":
print(device_lib.list_local_devices())

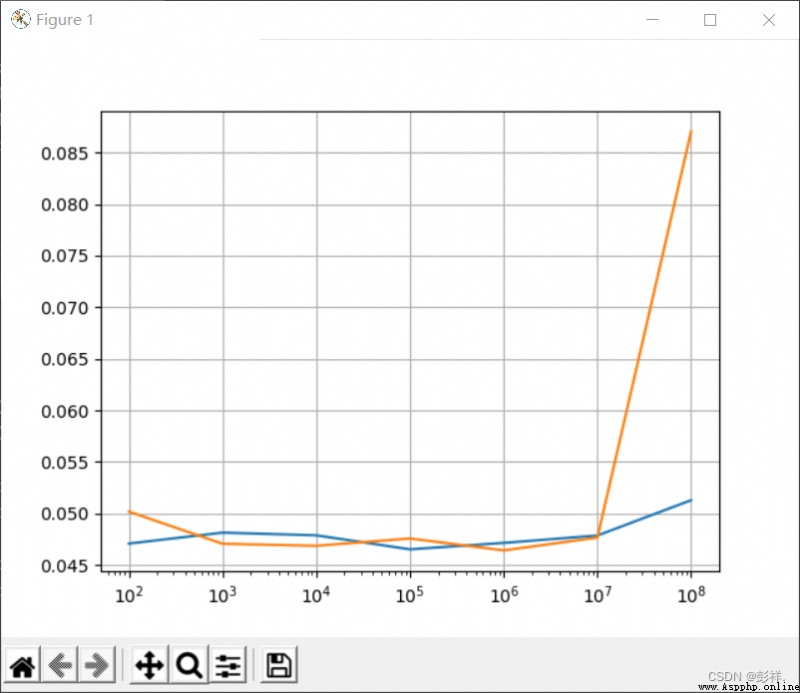
接下來,我們跑個程序來比較一下CPU和GPU性能上的差距:
import tensorflow as tf
import timeit
import numpy as np
import matplotlib.pyplot as plt
def cpu_run(num):
with tf.device('/cpu:0'):
cpu_a=tf.random_normal([1,num])
cpu_b=tf.random_normal([num,1])
c=tf.matmul(cpu_a,cpu_b)
return c
def gpu_run(num):
with tf.device('/gpu:0'):
gpu_a=tf.random_normal([1,num])
gpu_b=tf.random_normal([num,1])
c=tf.matmul(gpu_a,gpu_b)
return c
k=10
m=7
cpu_result=np.arange(m,dtype=np.float32)
gpu_result=np.arange(m,dtype=np.float32)
x_time=np.arange(m)
for i in range(m):
k=k*10
x_time[i]=k
cpu_str='cpu_run('+str(k)+')'
gpu_str='gpu_run('+str(k)+')'
#print(cpu_str)
cpu_time=timeit.timeit(cpu_str,'from __main__ import cpu_run',number=10)
gpu_time=timeit.timeit(gpu_str,'from __main__ import gpu_run',number=10)
# 正式計算10次,取平均時間
cpu_time=timeit.timeit(cpu_str,'from __main__ import cpu_run',number=10)
gpu_time=timeit.timeit(gpu_str,'from __main__ import gpu_run',number=10)
cpu_result[i]=cpu_time
gpu_result[i]=gpu_time
print(cpu_result)
print(gpu_result)
fig, ax = plt.subplots()
ax.set_xscale("log")
ax.set_adjustable("datalim")
ax.plot(x_time,cpu_result)
ax.plot(x_time,gpu_result)
ax.grid()
plt.draw()
plt.show()
在不同CUDA版本下的安裝,由於博主的顯卡太拉跨導致CUDA版本太低不支持,只能安裝CPU版本的了
pip install torch1.10.1+cpu torchvision0.11.2+cpu torchaudio==0.10.1 -f https://download.pytorch.org/whl/torch_stable.html
其他命令:
# CUDA 11.1
pip install torch==1.10.1+cu111 torchvision==0.11.2+cu111 torchaudio==0.10.1 -f https://download.pytorch.org/whl/torch_stable.html
# CUDA 10.2
pip install torch==1.10.1+cu102 torchvision==0.11.2+cu102 torchaudio==0.10.1 -f https://download.pytorch.org/whl/torch_stable.html
# CPU only
pip install torch==1.10.1+cpu torchvision==0.11.2+cpu torchaudio==0.10.1 -f https://download.pytorch.org/whl/torch_stable.html
數據集下載地址:
http://yann.lecun.com/exdb/mnist/

手寫數字識別是一個比較簡單的任務,數字只可能是0-9中的一個,這是個10分類的問題。
MNIST手寫數字識別項目因為數據量小,識別任務簡單而成為圖像識別入門的第一課,MNIST手寫數字識別項目有如下特點:
(1) 識別難度低,即使把圖片展開為一維數據,且只使用全連接層也能獲得超過98%的識別准確度。
(2)計算量小,不需要GPU加速也可以快速訓練完成。
(3)數據容易得到,教程容易得到。
# coding=utf-8
import os
import torch
from torch import nn, optim
import torch.nn.functional as F
# from torch.autograd import Variable
from torchvision import datasets, transforms
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
trainset = datasets.MNIST('data', train=True, download=True, transform=transform)#下載,加載數據
testset = datasets.MNIST('data', train=False, download=True, transform=transform)
class LeNet(nn.Module):
# 定義Net的初始化函數,本函數定義了神經網絡的基本結構
def __init__(self):
# 繼承父類的初始化方法,即先運行nn.Module的初始化函數
super(LeNet, self).__init__()
# C1卷積層:輸入1張灰度圖片,輸出6張特征圖,卷積核5x5
self.c1 = nn.Conv2d(1, 6, (5, 5))
# C3卷積層:輸入6張特征圖,輸出16張特征圖,卷積核5x5
self.c3 = nn.Conv2d(6, 16, 5)
# 全連接層S4->C5:從S4到C5是全連接,S4層中16*4*4個節點全連接到C5層的120個節點上
self.fc1 = nn.Linear(16 * 4 * 4, 120)
# 全連接層C5->F6:C5層的120個節點全連接到F6的84個節點上
self.fc2 = nn.Linear(120, 84)
# 全連接層F6->OUTPUT:F6層的84個節點全連接到OUTPUT層的10個節點上,10個節點的輸出代表著0到9的不同分值。
self.fc3 = nn.Linear(84, 10)
# 定義向前傳播函數
def forward(self, x):
# 輸入的灰度圖片x經過c1的卷積之後得到6張特征圖,然後使用relu函數,增強網絡的非線性擬合能力,接著使用2x2窗口的最大池化,然後更新到x
x = F.max_pool2d(F.relu(self.c1(x)), 2)
# 輸入x經過c3的卷積之後由原來的6張特征圖變成16張特征圖,經過relu函數,並使用最大池化後將結果更新到x
x = F.max_pool2d(F.relu(self.c3(x)), 2)
# 使用view函數將張量x(S4)變形成一維向量形式,總特征數不變,為全連接層做准備
x = x.view(-1, self.num_flat_features(x))
# 輸入S4經過全連接層fc1,再經過relu,更新到x
x = F.relu(self.fc1(x))
# 輸入C5經過全連接層fc2,再經過relu,更新到x
x = F.relu(self.fc2(x))
# 輸入F6經過全連接層fc3,更新到x
x = self.fc3(x)
return x
# 計算張量x的總特征量
def num_flat_features(self, x):
# 由於默認批量輸入,第零維度的batch剔除
size = x.size()[1:]
num_features = 1
for s in size:
num_features *= s
return num_features
CUDA = torch.cuda.is_available()
if CUDA:
lenet = LeNet().cuda()
else:
lenet = LeNet()
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(lenet.parameters(), lr=0.001, momentum=0.9)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=4, shuffle=True, num_workers=2)
testloader = torch.utils.data.DataLoader(testset, batch_size=4, shuffle=False, num_workers=2)
def train(model, criterion, optimizer, epochs=1):
for epoch in range(epochs):
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
inputs, labels = data
if CUDA:
inputs, labels = inputs.cuda(), labels.cuda()
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
if i % 1000 == 999:
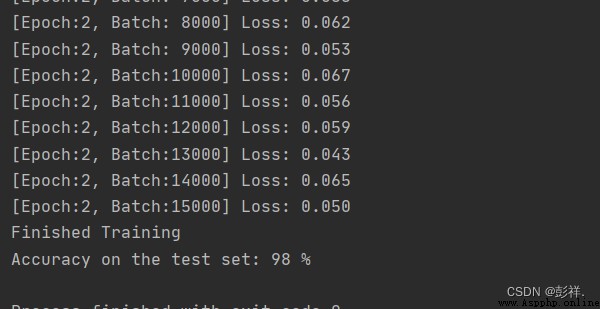
print('[Epoch:%d, Batch:%5d] Loss: %.3f' % (epoch + 1, i + 1, running_loss / 1000))
running_loss = 0.0
print('Finished Training')
def test(testloader, model):
correct = 0
total = 0
for data in testloader:
images, labels = data
if CUDA:
images = images.cuda()
labels = labels.cuda()
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum()
print('Accuracy on the test set: %d %%' % (100 * correct / total))
def load_param(model, path):
if os.path.exists(path):
model.load_state_dict(torch.load(path))
def save_param(model, path):
torch.save(model.state_dict(), path)
if __name__ =="__main__":
load_param(lenet, 'model.pkl')
train(lenet, criterion, optimizer, epochs=2)
save_param(lenet, 'model.pkl')
test(testloader, lenet)