相關的代碼和圖片材料:材料下載
在本實驗中,要求分別使用基礎搜索算法和 Deep QLearning 算法,完成機器人自動走迷宮。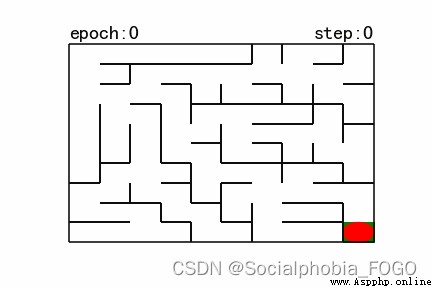
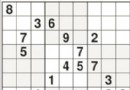
圖1 地圖(size10)
如上圖所示,左上角的紅色橢圓既是起點也是機器人的初始位置,右下角的綠色方塊是出口。
游戲規則為:從起點開始,通過錯綜復雜的迷宮,到達目標點(出口)。
在任一位置可執行動作包括:向上走 ‘u’、向右走 ‘r’、向下走 ‘d’、向左走 ‘l’。
執行不同的動作後,根據不同的情況會獲得不同的獎勵,具體而言,有以下幾種情況。
撞牆
走到出口
其余情況
需要您分別實現基於基礎搜索算法和 Deep QLearning 算法的機器人,使機器人自動走到迷宮的出口。
使用 Python 語言。
使用基礎搜索算法完成機器人走迷宮。
使用 Deep QLearning 算法完成機器人走迷宮。
算法部分需要自己實現,不能使用現成的包、工具或者接口。
import os
import random
import numpy as np
import torch
使用 Maze(maze_size=size) 來隨機生成一個 size * size 大小的迷宮。
使用 print() 函數可以輸出迷宮的 size 以及畫出迷宮圖
紅色的圓是機器人初始位置
綠色的方塊是迷宮的出口位置
圖2 gif地圖(size10)
Maze 類中重要的成員方法如下:
sense_robot() :獲取機器人在迷宮中目前的位置。
return:機器人在迷宮中目前的位置。
move_robot(direction) :根據輸入方向移動默認機器人,若方向不合法則返回錯誤信息。
direction:移動方向, 如:“u”, 合法值為: [‘u’, ‘r’, ‘d’, ‘l’]
return:執行動作的獎勵值
can_move_actions(position):獲取當前機器人可以移動的方向
position:迷宮中任一處的坐標點
return:該點可執行的動作,如:[‘u’,‘r’,‘d’]
is_hit_wall(self, location, direction):判斷該移動方向是否撞牆
location, direction:當前位置和要移動的方向,如(0,0) , “u”
return:True(撞牆) / False(不撞牆)
draw_maze():畫出當前的迷宮
算法具體步驟:
選取圖中某一頂點 V i V_i Vi為出發點,訪問並標記該頂點;
以Vi為當前頂點,依次搜索 V i V_i Vi的每個鄰接點 V j V_j Vj,若 V j V_j Vj未被訪問過,則訪問和標記鄰接點 V j V_j Vj,若 V j V_j Vj已被訪問過,則搜索 V i V_i Vi的下一個鄰接點;
以 V j V_j Vj為當前頂點,重復上一步驟),直到圖中和 V i V_i Vi有路徑相通的頂點都被訪問為止;
若圖中尚有頂點未被訪問過(非連通的情況下),則可任取圖中的一個未被訪問的頂點作為出發點,重復上述過程,直至圖中所有頂點都被訪問。
時間復雜度:
查找每個頂點的鄰接點所需時間為 O ( n 2 ) O(n^2) O(n2),n為頂點數,算法的時間復雜度為 O ( n 2 ) O(n^2) O(n2)
Q-Learning 是一個值迭代(Value Iteration)算法。與策略迭代(Policy Iteration)算法不同,值迭代算法會計算每個”狀態“或是”狀態-動作“的值(Value)或是效用(Utility),然後在執行動作的時候,會設法最大化這個值。 因此,對每個狀態值的准確估計,是值迭代算法的核心。通常會考慮最大化動作的長期獎勵,即不僅考慮當前動作帶來的獎勵,還會考慮動作長遠的獎勵。
3.2.1 Q值計算與迭代
Q-learning 算法將狀態(state)和動作(action)構建成一張 Q_table 表來存儲 Q 值,Q 表的行代表狀態(state),列代表動作(action): 在 Q-Learning 算法中,將這個長期獎勵記為 Q 值,其中會考慮每個 ”狀態-動作“ 的 Q 值,具體而言,它的計算公式為: Q ( s t , a ) = R t + 1 + γ × max a Q ( a , s t + 1 ) Q(s_{t},a) = R_{t+1} + \gamma \times\max_a Q(a,s_{t+1}) Q(st,a)=Rt+1+γ×amaxQ(a,st+1)
在 Q-Learning 算法中,將這個長期獎勵記為 Q 值,其中會考慮每個 ”狀態-動作“ 的 Q 值,具體而言,它的計算公式為: Q ( s t , a ) = R t + 1 + γ × max a Q ( a , s t + 1 ) Q(s_{t},a) = R_{t+1} + \gamma \times\max_a Q(a,s_{t+1}) Q(st,a)=Rt+1+γ×amaxQ(a,st+1)
也就是對於當前的“狀態-動作” ( s t , a ) (s_{t},a) (st,a),考慮執行動作 a a a 後環境獎勵 R t + 1 R_{t+1} Rt+1,以及執行動作 a a a 到達 s t + 1 s_{t+1} st+1後,執行任意動作能夠獲得的最大的Q值 max a Q ( a , s t + 1 ) \max_a Q(a,s_{t+1}) maxaQ(a,st+1), γ \gamma γ 為折扣因子。
計算得到新的 Q 值之後,一般會使用更為保守地更新 Q 表的方法,即引入松弛變量 a l p h a alpha alpha ,按如下的公式進行更新,使得 Q 表的迭代變化更為平緩。 Q ( s t , a ) = ( 1 − α ) × Q ( s t , a ) + α × ( R t + 1 + γ × max a Q ( a , s t + 1 ) ) Q(s_{t},a) = (1-\alpha) \times Q(s_{t},a) + \alpha \times(R_{t+1} + \gamma \times\max_a Q(a,s_{t+1})) Q(st,a)=(1−α)×Q(st,a)+α×(Rt+1+γ×amaxQ(a,st+1))
3.2.2 機器人動作的選擇
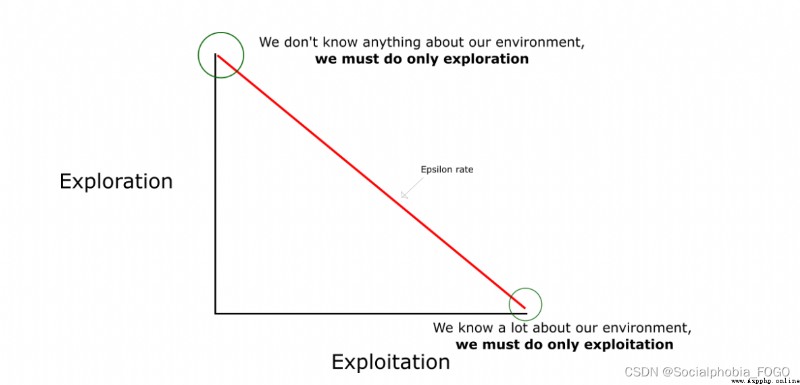
在強化學習中,探索-利用 問題是非常重要的問題。 具體來說,根據上面的定義,會盡可能地讓機器人在每次選擇最優的決策,來最大化長期獎勵。但是這樣做有如下的弊端:
在初步的學習中,Q 值是不准確的,如果在這個時候都按照 Q 值來選擇,那麼會造成錯誤。
學習一段時間後,機器人的路線會相對固定,則機器人無法對環境進行有效的探索。
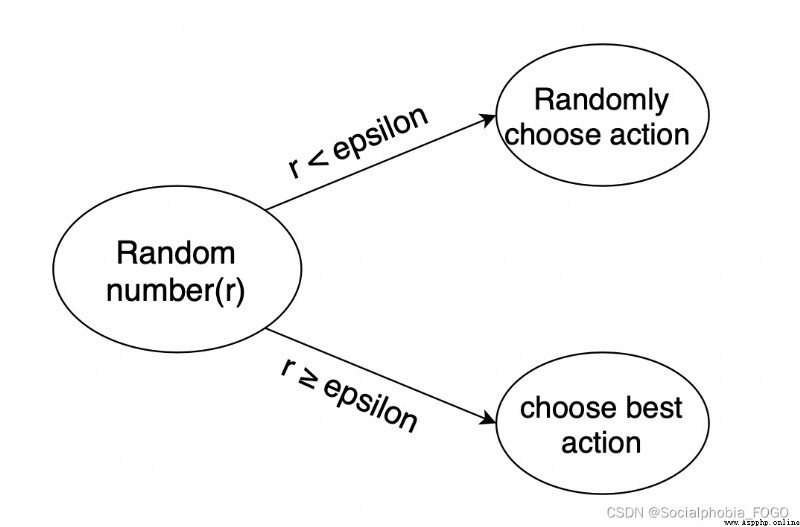
因此需要一種辦法,來解決如上的問題,增加機器人的探索。通常會使用 epsilon-greedy 算法:
在機器人選擇動作的時候,以一部分的概率隨機選擇動作,以一部分的概率按照最優的 Q 值選擇動作。
同時,這個選擇隨機動作的概率應當隨著訓練的過程逐步減小。
3.2.3 Q-Learning 算法的學習過程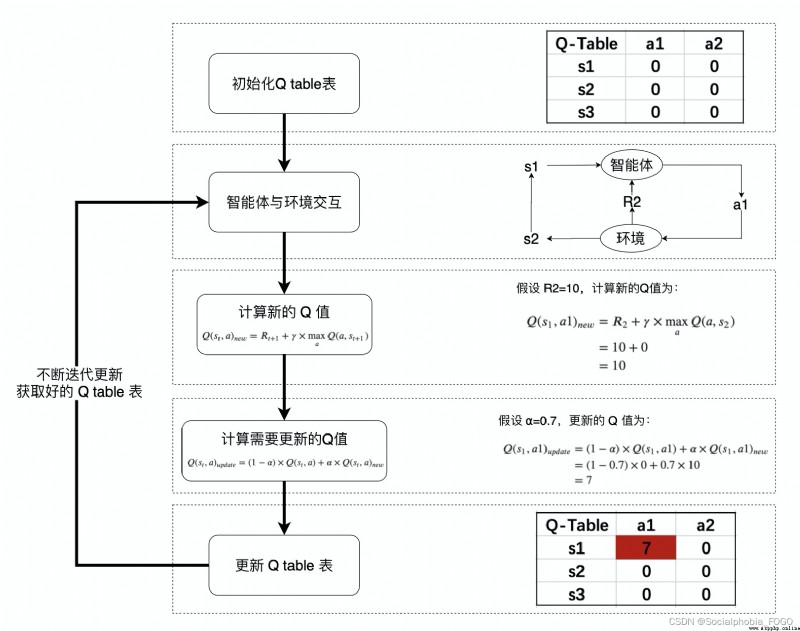
3.2.4 Robot 類
在本作業中提供了 QRobot 類,其中實現了 Q 表迭代和機器人動作的選擇策略,可通過 from QRobot import QRobot 導入使用。
QRobot 類的核心成員方法
sense_state():獲取當前機器人所處位置
return:機器人所處的位置坐標,如: (0, 0)
current_state_valid_actions():獲取當前機器人可以合法移動的動作
return:由當前合法動作組成的列表,如: [‘u’,‘r’]
train_update():以訓練狀態,根據 QLearning 算法策略執行動作
return:當前選擇的動作,以及執行當前動作獲得的回報, 如: ‘u’, -1
test_update():以測試狀態,根據 QLearning 算法策略執行動作
return:當前選擇的動作,以及執行當前動作獲得的回報, 如:‘u’, -1
reset()
return:重置機器人在迷宮中的位置
3.2.5 Runner 類
QRobot 類實現了 QLearning 算法的 Q 值迭代和動作選擇策略。在機器人自動走迷宮的訓練過程中,需要不斷的使用 QLearning 算法來迭代更新 Q 值表,以達到一個“最優”的狀態,因此封裝好了一個類 Runner 用於機器人的訓練和可視化。可通過 from Runner import Runner 導入使用。
Runner 類的核心成員方法:
run_training(training_epoch, training_per_epoch=150): 訓練機器人,不斷更新 Q 表,並講訓練結果保存在成員變量 train_robot_record 中
training_epoch, training_per_epoch: 總共的訓練次數、每次訓練機器人最多移動的步數
run_testing():測試機器人能否走出迷宮
generate_gif(filename):將訓練結果輸出到指定的 gif 圖片中
filename:合法的文件路徑,文件名需以 .gif 為後綴
plot_results():以圖表展示訓練過程中的指標:Success Times、Accumulated Rewards、Runing Times per Epoch
DQN 算法使用神經網絡來近似值函數,算法框圖如下。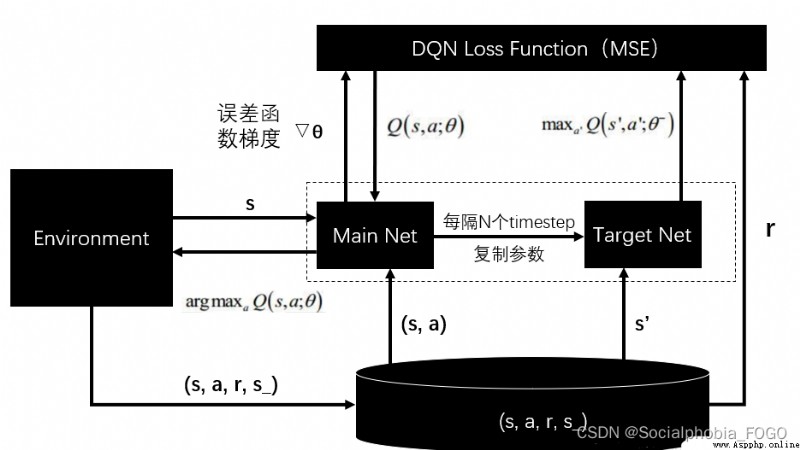
在本次實驗中,使用提供的神經網絡來預計四個動作的評估分數,同時輸出評估分數。
ReplayDataSet 類的核心成員方法
add(self, state, action_index, reward, next_state, is_terminal) 添加一條訓練數據
state: 當前機器人位置
action_index: 選擇執行動作的索引
reward: 執行動作獲得的回報
next_state:執行動作後機器人的位置
is_terminal:機器人是否到達了終止節點(到達終點或者撞牆)
random_sample(self, batch_size):從數據集中隨機抽取固定batch_size的數據
batch_size: 整數,不允許超過數據集中數據的個數
build_full_view(self, maze):開啟金手指,獲取全圖視野
maze: 以 Maze 類實例化的對象
編寫深度優先搜索算法,並進行測試,通過使用堆棧的方式,來進行一層一層的迭代,最終搜索出路徑。主要過程為,入口節點作為根節點,之後查看此節點是否被探索過且是否存在子節點,若滿足條件則拓展該節點,將該節點的子節點按照先後順序入棧。若探索到一個節點時,此節點不是終點且沒有可以拓展的子節點,則將此點出棧操作,循環操作直到找到終點。
測試結果如下:
若maze_size=5,運行基礎搜索算法,最終成果如下:
搜索出的路徑: ['r', 'd', 'r', 'd', 'd', 'r', 'r', 'd']
恭喜你,到達了目標點
Maze of size (5, 5)
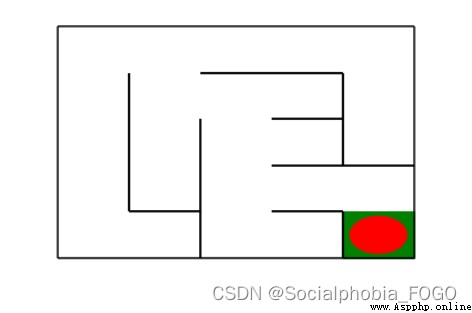
圖3 基礎搜索地圖(size5)
若maze_size=10,運行基礎搜索算法,最終成果如下:
搜索出的路徑: ['r', 'r', 'r', 'r', 'r', 'r', 'r', 'd', 'r', 'd', 'd', 'd', 'r', 'd', 'd', 'd', 'l', 'd', 'd', 'r']
恭喜你,到達了目標點
Maze of size (10, 10)

圖4 基礎搜索地圖(size10)
若maze_size=20,運行基礎搜索算法,最終成果如下:
搜索出的路徑: ['d', 'r', 'u', 'r', 'r', 'r', 'r', 'd', 'r', 'd', 'r', 'r', 'r', 'r', 'd', 'd', 'r', 'd', 'd', 'd', 'd', 'r', 'r', 'r', 'r', 'r', 'd', 'r', 'r', 'd', 'r', 'd', 'd', 'l', 'l', 'd', 'd', 'd', 'd', 'd', 'r', 'd', 'd', 'r']
恭喜你,到達了目標點
Maze of size (20, 20)

圖5 基礎搜索地圖(size20)
部分代碼如下:
def myDFS(maze):
""" 對迷宮進行深度優先搜索 :param maze: 待搜索的maze對象 """
start = maze.sense_robot()
root = SearchTree(loc=start)
queue = [root] # 節點堆棧,用於層次遍歷
h, w, _ = maze.maze_data.shape
is_visit_m = np.zeros((h, w), dtype=np.int) # 標記迷宮的各個位置是否被訪問過
path = [] # 記錄路徑
peek = 0
while True:
current_node = queue[peek] # 棧頂元素作為當前節點
#is_visit_m[current_node.loc] = 1 # 標記當前節點位置已訪問
if current_node.loc == maze.destination: # 到達目標點
path = back_propagation(current_node)
break
if current_node.is_leaf() and is_visit_m[current_node.loc] == 0: # 如果該點存在葉子節點且未拓展
is_visit_m[current_node.loc] = 1 # 標記該點已拓展
child_number = expand(maze, is_visit_m, current_node)
peek+=child_number # 開展一些列入棧操作
for child in current_node.children:
queue.append(child) # 葉子節點入棧
else:
queue.pop(peek) # 如果無路可走則出棧
peek-=1
return path
在算法訓練過程中,首先讀取機器人當前位置,之後將當前狀態加入Q值表中,如果表中已經存在當前狀態則不需重復添加。之後,生成機器人的需要執行動作,並返回地圖獎勵值、查找機器人現階段位置。接著再次檢查並更新Q值表,衰減隨機選取動作的可能性。
QLearning算法實現過程中,主要是對Q值表的計算更新進行了修改和調整,調整後的Q值表在運行時性能優秀,計算速度快且准確性、穩定性高。之後調節了隨機選擇動作可能性的衰減率。因為在測試過程中發現,如果衰減太慢的話會導致隨機性太強,間接的減弱了獎勵的作用,故最終通過調整,發現衰減率取0.5是一個較為優秀的且穩定的值。
部分代碼如下:
def train_update(self):
""" 以訓練狀態選擇動作,並更新相關參數 :return :action, reward 如:"u", -1 """
self.state = self.maze.sense_robot() # 獲取機器人當初所處迷宮位置
# 檢索Q表,如果當前狀態不存在則添加進入Q表
if self.state not in self.q_table:
self.q_table[self.state] = {
a: 0.0 for a in self.valid_action}
action = random.choice(self.valid_action) if random.random() < self.epsilon else max(self.q_table[self.state], key=self.q_table[self.state].get) # action為機器人選擇的動作
reward = self.maze.move_robot(action) # 以給定的方向移動機器人,reward為迷宮返回的獎勵值
next_state = self.maze.sense_robot() # 獲取機器人執行指令後所處的位置
# 檢索Q表,如果當前的next_state不存在則添加進入Q表
if next_state not in self.q_table:
self.q_table[next_state] = {
a: 0.0 for a in self.valid_action}
# 更新 Q 值表
current_r = self.q_table[self.state][action]
update_r = reward + self.gamma * float(max(self.q_table[next_state].values()))
self.q_table[self.state][action] = self.alpha * self.q_table[self.state][action] +(1 - self.alpha) * (update_r - current_r)
self.epsilon *= 0.5 # 衰減隨機選擇動作的可能性
return action, reward
測試結果如下:
若maze_size=3,運行強化學習搜索算法,最終成果如下: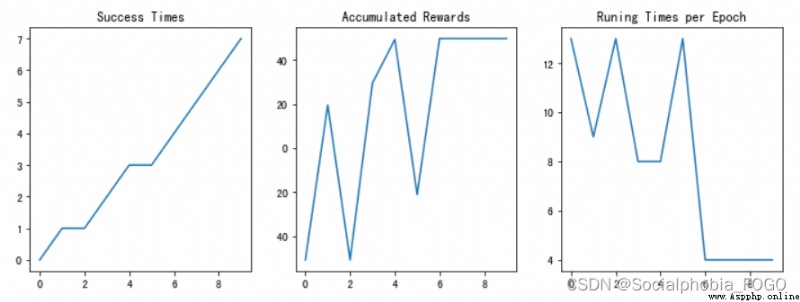
圖6 強化學習搜索gif地圖(size3)
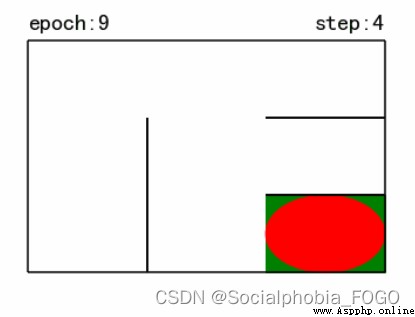 圖7 訓練結果
圖7 訓練結果
若maze_size=5,運行強化學習搜索算法,最終成果如下:
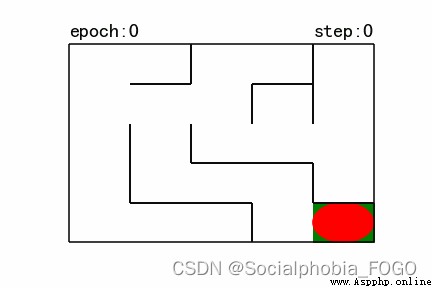
圖8 強化學習搜索gif地圖(size5)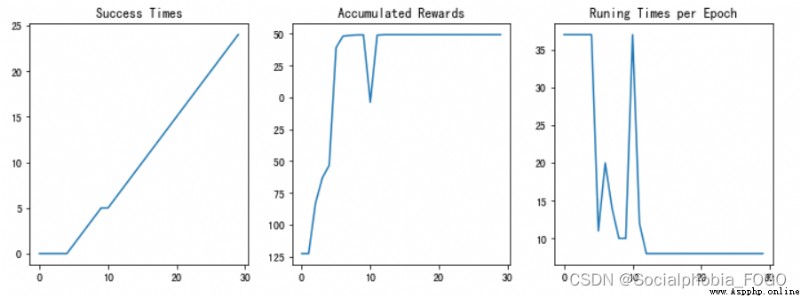 圖9 訓練結果
圖9 訓練結果
若maze_size=10,運行強化學習搜索算法,最終成果如下:
圖10 強化學習搜索gif地圖(size10)
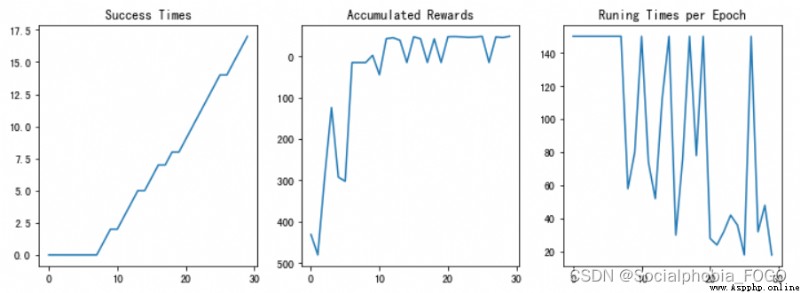
圖11 訓練結果
若maze_size=11,運行強化學習搜索算法,最終成果如下: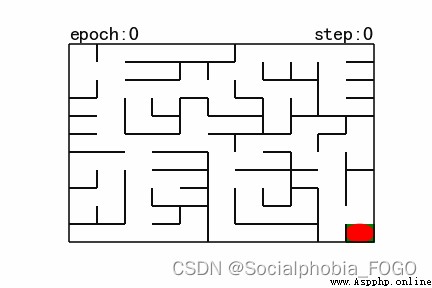
圖12 強化學習搜索gif地圖(size11)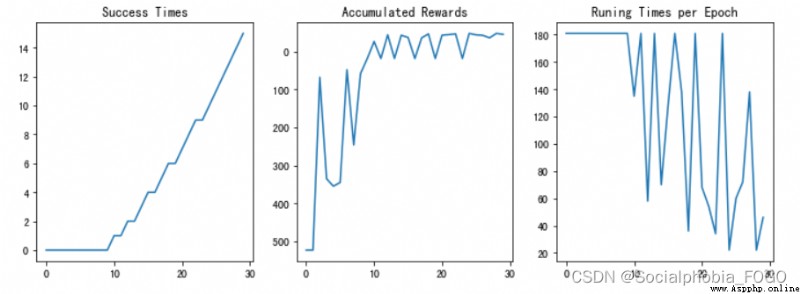
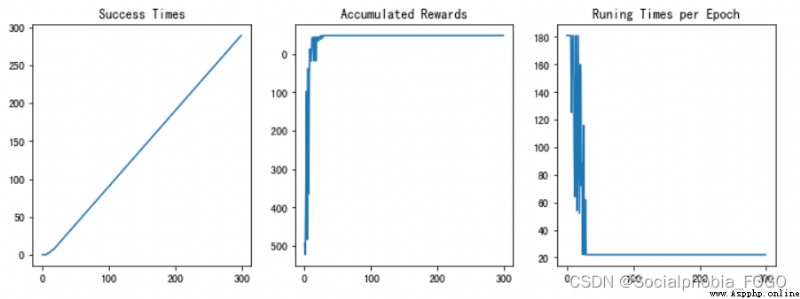
圖13 訓練結果
經過測試,強化學習搜索算法可以快速給出走出迷宮的路徑並且隨著訓練輪次增加,成功率也逐漸上升。當訓練輪次足夠時,最終後期准確率可以達到100%。
在Q-Learning 的基礎上,使用神經網絡來估計評估分數,用於決策之後的動作。只需在Q-Learning相應部分替換為神經網絡的輸出即可。
測試結果如下:
若maze_size=3,運行DQN算法,最終成果如下: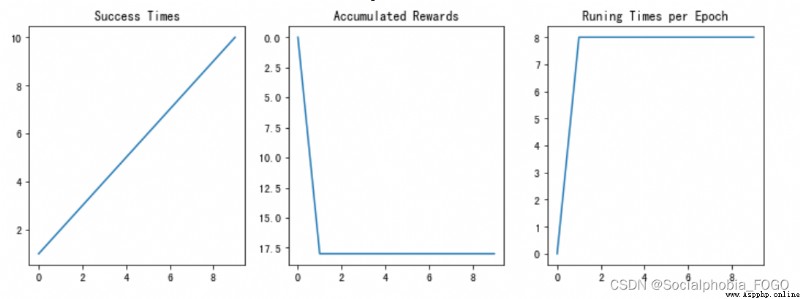
圖14 訓練結果
若maze_size=5,運行DQN算法,最終成果如下:
圖15 訓練結果
若maze_size=10,運行DQN算法,最終成果如下:
圖16 訓練結果
4.4.1 基礎搜索算法測試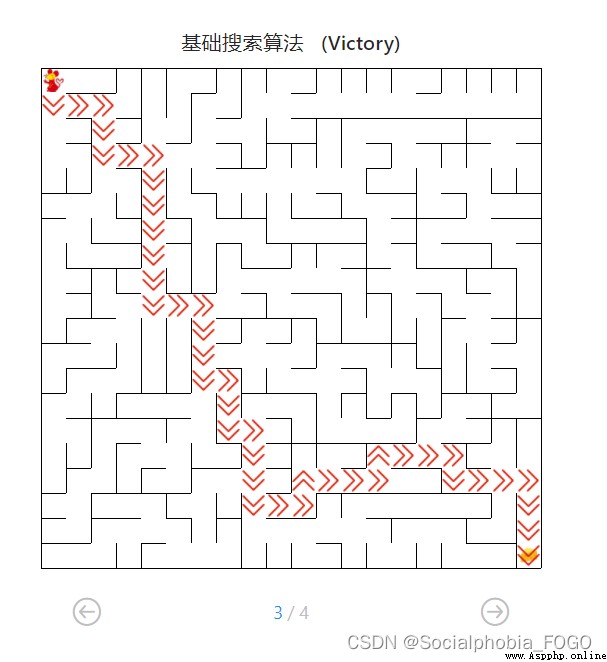
圖17 基礎搜索算法路徑
用時0秒
4.4.2 強化學習算法(初級)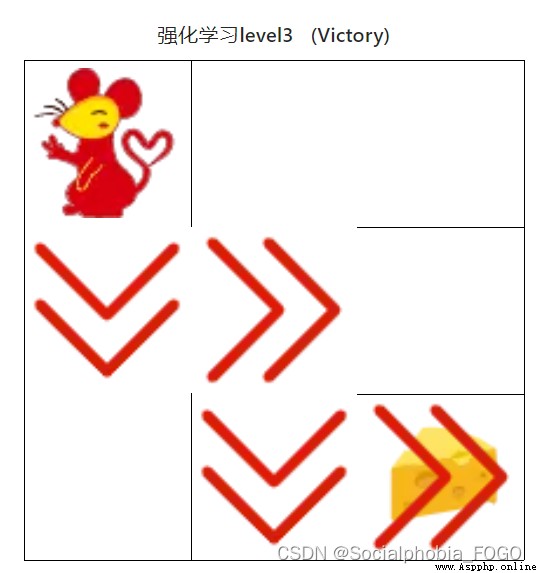
圖18 強化學習算法(初級)
用時0秒
4.4.3 強化學習算法(中級)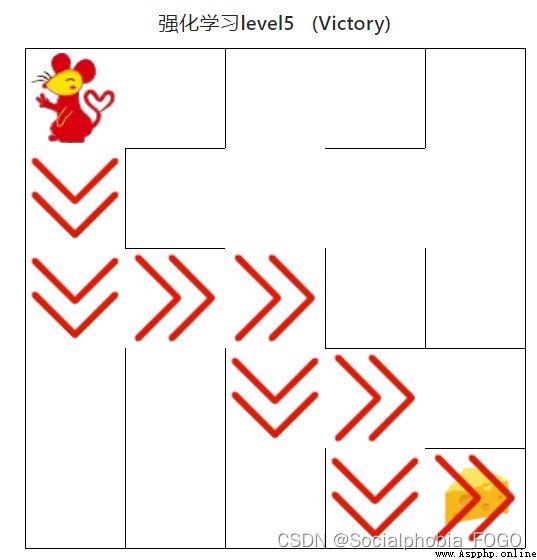
圖19 強化學習算法(中級)
用時0秒
4.4.4 強化學習算法(高級)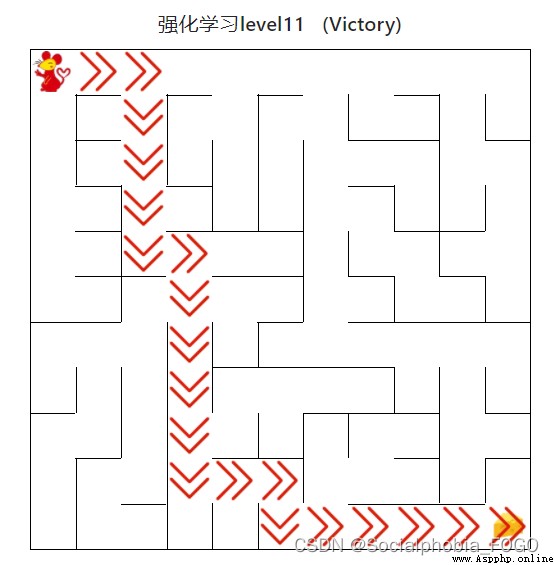
圖20 強化學習算法(高級)
用時0秒
4.4.5 DQN算法(初級)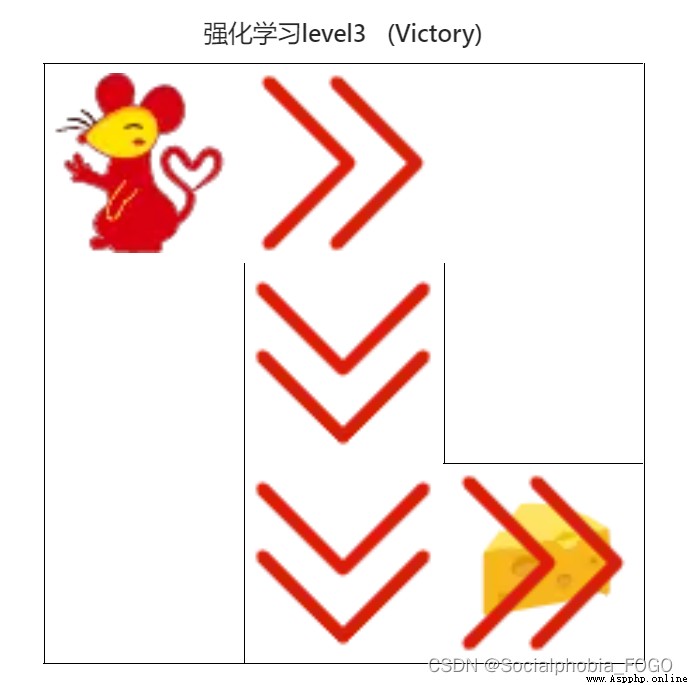
圖21 DQN算法(初級)
用時2秒
4.4.6 DQN算法(中級)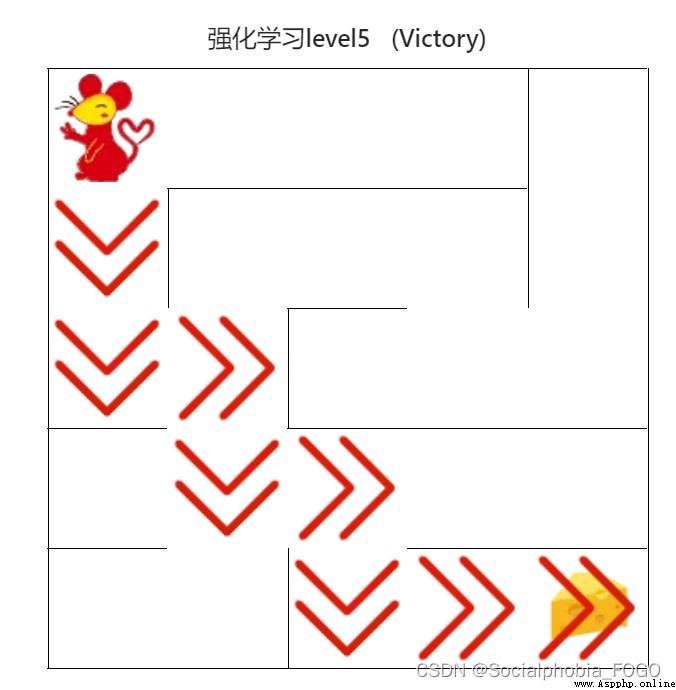
圖22 DQN算法(中級)
用時3秒
4.4.7 DQN算法(高級)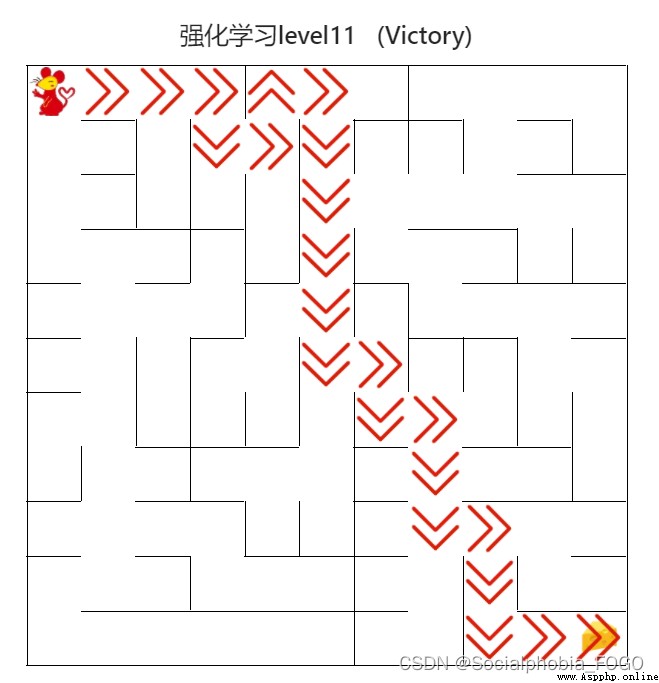
圖23 DQN算法(高級)
用時105秒
比較基礎搜索算法、強化學習搜索算法和DQN算法可以發現,在訓練輪次提升到較大數字的時候,三算法速度均很快且有較高的准確率。DQN算法耗費時間長,但是性能穩定。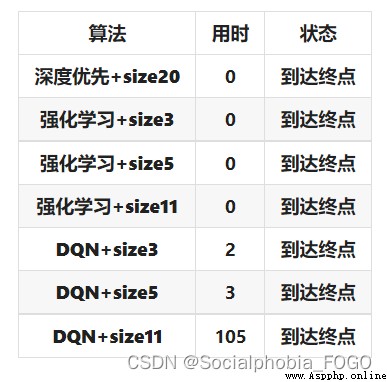
通過本次實驗,學習到了多種基礎搜索算法的具體工作方式,並且在實踐中實現了這些基礎搜索算法;同時學習了強化學習搜索算法的工作原理和應用方式,讓我對這些方法有了更加深刻的認識,也對各個環節有了更加深層次的理解,受益匪淺。
程序清單:
# 導入相關包
import os
import random
import numpy as np
import torch
from QRobot import QRobot
from ReplayDataSet import ReplayDataSet
from torch_py.MinDQNRobot import MinDQNRobot as TorchRobot # PyTorch版本
import matplotlib.pyplot as plt
# ------基礎搜索算法-------
def my_search(maze):
# 機器人移動方向
move_map = {
'u': (-1, 0), # up
'r': (0, +1), # right
'd': (+1, 0), # down
'l': (0, -1), # left
}
# 迷宮路徑搜索樹
class SearchTree(object):
def __init__(self, loc=(), action='', parent=None):
""" 初始化搜索樹節點對象 :param loc: 新節點的機器人所處位置 :param action: 新節點的對應的移動方向 :param parent: 新節點的父輩節點 """
self.loc = loc # 當前節點位置
self.to_this_action = action # 到達當前節點的動作
self.parent = parent # 當前節點的父節點
self.children = [] # 當前節點的子節點
def add_child(self, child):
""" 添加子節點 :param child:待添加的子節點 """
self.children.append(child)
def is_leaf(self):
""" 判斷當前節點是否是葉子節點 """
return len(self.children) == 0
def expand(maze, is_visit_m, node):
""" 拓展葉子節點,即為當前的葉子節點添加執行合法動作後到達的子節點 :param maze: 迷宮對象 :param is_visit_m: 記錄迷宮每個位置是否訪問的矩陣 :param node: 待拓展的葉子節點 """
child_number = 0 # 記錄葉子節點個數
can_move = maze.can_move_actions(node.loc)
for a in can_move:
new_loc = tuple(node.loc[i] + move_map[a][i] for i in range(2))
if not is_visit_m[new_loc]:
child = SearchTree(loc=new_loc, action=a, parent=node)
node.add_child(child)
child_number+=1
return child_number # 返回葉子節點個數
def back_propagation(node):
""" 回溯並記錄節點路徑 :param node: 待回溯節點 :return: 回溯路徑 """
path = []
while node.parent is not None:
path.insert(0, node.to_this_action)
node = node.parent
return path
def myDFS(maze):
""" 對迷宮進行深度 :param maze: 待搜索的maze對象 """
start = maze.sense_robot()
root = SearchTree(loc=start)
queue = [root] # 節點堆棧,用於層次遍歷
h, w, _ = maze.maze_data.shape
is_visit_m = np.zeros((h, w), dtype=np.int) # 標記迷宮的各個位置是否被訪問過
path = [] # 記錄路徑
peek = 0
while True:
current_node = queue[peek] # 棧頂元素作為當前節點
#is_visit_m[current_node.loc] = 1 # 標記當前節點位置已訪問
if current_node.loc == maze.destination: # 到達目標點
path = back_propagation(current_node)
break
if current_node.is_leaf() and is_visit_m[current_node.loc] == 0: # 如果該點存在葉子節點且未拓展
is_visit_m[current_node.loc] = 1 # 標記該點已拓展
child_number = expand(maze, is_visit_m, current_node)
peek+=child_number # 開展一些列入棧操作
for child in current_node.children:
queue.append(child) # 葉子節點入棧
else:
queue.pop(peek) # 如果無路可走則出棧
peek-=1
# 出隊
#queue.pop(0)
return path
path = myDFS(maze)
return path
# --------強化學習算法---------
# 導入相關包
import random
from Maze import Maze
from Runner import Runner
from QRobot import QRobot
class Robot(QRobot):
valid_action = ['u', 'r', 'd', 'l']
def __init__(self, maze, alpha=0.5, gamma=0.9, epsilon=0.5):
""" 初始化 Robot 類 :param maze:迷宮對象 """
self.maze = maze
self.state = None
self.action = None
self.alpha = alpha
self.gamma = gamma
self.epsilon = epsilon # 動作隨機選擇概率
self.q_table = {
}
self.maze.reset_robot() # 重置機器人狀態
self.state = self.maze.sense_robot() # state為機器人當前狀態
if self.state not in self.q_table: # 如果當前狀態不存在,則為 Q 表添加新列
self.q_table[self.state] = {
a: 0.0 for a in self.valid_action}
def train_update(self):
""" 以訓練狀態選擇動作,並更新相關參數 :return :action, reward 如:"u", -1 """
self.state = self.maze.sense_robot() # 獲取機器人當初所處迷宮位置
# 檢索Q表,如果當前狀態不存在則添加進入Q表
if self.state not in self.q_table:
self.q_table[self.state] = {
a: 0.0 for a in self.valid_action}
action = random.choice(self.valid_action) if random.random() < self.epsilon else max(self.q_table[self.state], key=self.q_table[self.state].get) # action為機器人選擇的動作
reward = self.maze.move_robot(action) # 以給定的方向移動機器人,reward為迷宮返回的獎勵值
next_state = self.maze.sense_robot() # 獲取機器人執行指令後所處的位置
# 檢索Q表,如果當前的next_state不存在則添加進入Q表
if next_state not in self.q_table:
self.q_table[next_state] = {
a: 0.0 for a in self.valid_action}
# 更新 Q 值表
current_r = self.q_table[self.state][action]
update_r = reward + self.gamma * float(max(self.q_table[next_state].values()))
self.q_table[self.state][action] = self.alpha * self.q_table[self.state][action] +(1 - self.alpha) * (update_r - current_r)
self.epsilon *= 0.5 # 衰減隨機選擇動作的可能性
return action, reward
def test_update(self):
""" 以測試狀態選擇動作,並更新相關參數 :return :action, reward 如:"u", -1 """
self.state = self.maze.sense_robot() # 獲取機器人現在所處迷宮位置
# 檢索Q表,如果當前狀態不存在則添加進入Q表
if self.state not in self.q_table:
self.q_table[self.state] = {
a: 0.0 for a in self.valid_action}
action = max(self.q_table[self.state],key=self.q_table[self.state].get) # 選擇動作
reward = self.maze.move_robot(action) # 以給定的方向移動機器人
return action, reward
import random
import numpy as np
import torch
from QRobot import QRobot
from ReplayDataSet import ReplayDataSet
from torch_py.MinDQNRobot import MinDQNRobot as TorchRobot # PyTorch版本
import matplotlib.pyplot as plt
from Maze import Maze
import time
from Runner import Runner
class Robot(TorchRobot):
def __init__(self, maze):
""" 初始化 Robot 類 :param maze:迷宮對象 """
super(Robot, self).__init__(maze)
maze.set_reward(reward={
"hit_wall": 5.0,
"destination": -maze.maze_size ** 2.0,
"default": 1.0,
})
self.maze = maze
self.epsilon = 0
"""開啟金手指,獲取全圖視野"""
self.memory.build_full_view(maze=maze)
self.loss_list = self.train()
def train(self):
loss_list = []
batch_size = len(self.memory)
while True:
loss = self._learn(batch=batch_size)
loss_list.append(loss)
success = False
self.reset()
for _ in range(self.maze.maze_size ** 2 - 1):
a, r = self.test_update()
if r == self.maze.reward["destination"]:
return loss_list
def train_update(self):
def state_train():
state=self.sense_state()
return state
def action_train(state):
action=self._choose_action(state)
return action
def reward_train(action):
reward=self.maze.move_robot(action)
return reward
state = state_train()
action = action_train(state)
reward = reward_train(action)
return action, reward
def test_update(self):
def state_test():
state = torch.from_numpy(np.array(self.sense_state(), dtype=np.int16)).float().to(self.device)
return state
state = state_test()
self.eval_model.eval()
with torch.no_grad():
q_value = self.eval_model(state).cpu().data.numpy()
def action_test(q_value):
action=self.valid_action[np.argmin(q_value).item()]
return action
def reward_test(action):
reward=self.maze.move_robot(action)
return reward
action = action_test(q_value)
reward = reward_test(action)
return action, reward