Related code and picture materials : Material download
In this experiment , The basic search algorithm and Deep QLearning Algorithm , Complete the automatic maze walking of the robot .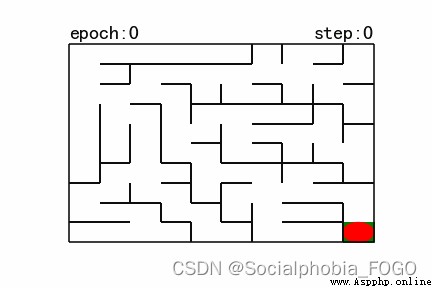
chart 1 Map (size10)
As shown in the figure above , The red ellipse in the upper left corner is both the starting point and the initial position of the robot , The green square in the lower right corner is the exit .
The rules of the game are : From the beginning , Through an intricate maze , Reach the target point ( exit ).
Actions that can be performed in any position include : Go up ‘u’、 turn right ‘r’、 Go down ‘d’、 turn left ‘l’.
After performing different actions , Different rewards will be given according to different situations , To be specific , There are several situations .
Against the wall
Go to the exit
Other cases
You need to implement the basic search algorithm and Deep QLearning Algorithmic robot , Make the robot automatically go to the exit of the maze .
Use Python Language .
The basic search algorithm is used to complete the maze walking of the robot .
Use Deep QLearning The algorithm completes the maze of the robot .
The algorithm part needs to be implemented by itself , You can't use off the shelf packages 、 Tools or interfaces .
import os
import random
import numpy as np
import torch
Use Maze(maze_size=size) To randomly generate a size * size The maze of size .
Use print() Function can output the of the maze size And draw a maze
The red circle is the initial position of the robot
The green square is the exit position of the maze
chart 2 gif Map (size10)
Maze The important member methods in the class are as follows :
sense_robot() : Get the current position of the robot in the maze .
return: The current position of the robot in the maze .
move_robot(direction) : Move the default robot according to the input direction , If the direction is irregular, an error message is returned .
direction: Direction of movement , Such as :“u”, The legal value is : [‘u’, ‘r’, ‘d’, ‘l’]
return: The reward value for performing the action
can_move_actions(position): Get the direction that the current robot can move
position: Coordinate points anywhere in the maze
return: The actions that can be performed at this point , Such as :[‘u’,‘r’,‘d’]
is_hit_wall(self, location, direction): Judge whether the moving direction hits the wall
location, direction: Current position and direction to move , Such as (0,0) , “u”
return:True( Against the wall ) / False( Don't hit the wall )
draw_maze(): Draw the current maze
Algorithm specific steps :
Select a vertex in the graph V i V_i Vi As a starting point , Access and mark the vertex ;
With Vi For the current vertex , Search for V i V_i Vi Every adjacent point of V j V_j Vj, if V j V_j Vj Not visited , Then access and mark adjacency points V j V_j Vj, if V j V_j Vj Has been interviewed , Search for V i V_i Vi Next adjacent point of ;
With V j V_j Vj For the current vertex , Repeat the previous step ), Until the middle of the picture V i V_i Vi Vertices with paths are accessed until ;
If there are still vertices in the graph that have not been visited ( In the case of non connectivity ), Then you can take an unreachable vertex in the graph as the starting point , Repeat the process , Until all vertices in the graph are accessed .
Time complexity :
The time required to find the adjacent points of each vertex is O ( n 2 ) O(n^2) O(n2),n For the top points , The time complexity of the algorithm is O ( n 2 ) O(n^2) O(n2)
Q-Learning It's a value iteration (Value Iteration) Algorithm . Iteration with strategy (Policy Iteration) Different algorithms , The value iteration algorithm computes each ” state “ or ” state - action “ Value (Value) Or utility (Utility), And then in the execution of the action , Will try to maximize this value . therefore , An accurate estimate of each state value , Is the core of value iteration algorithm . It is often considered to maximize the long-term rewards of the action , That is, not only consider the rewards of the current action , And think about long-term rewards .
3.2.1 Q Value calculation and iteration
Q-learning The algorithm will state (state) And the action (action) Build a Q_table Table to store Q value ,Q The rows of the table represent the status (state), Columns represent actions (action): stay Q-Learning In the algorithm, , Record this long-term reward as Q value , Each... Will be considered ” state - action “ Of Q value , To be specific , Its formula is : Q ( s t , a ) = R t + 1 + γ × max a Q ( a , s t + 1 ) Q(s_{t},a) = R_{t+1} + \gamma \times\max_a Q(a,s_{t+1}) Q(st,a)=Rt+1+γ×amaxQ(a,st+1)
stay Q-Learning In the algorithm, , Record this long-term reward as Q value , Each... Will be considered ” state - action “ Of Q value , To be specific , Its formula is : Q ( s t , a ) = R t + 1 + γ × max a Q ( a , s t + 1 ) Q(s_{t},a) = R_{t+1} + \gamma \times\max_a Q(a,s_{t+1}) Q(st,a)=Rt+1+γ×amaxQ(a,st+1)
That is to say, for the present “ state - action ” ( s t , a ) (s_{t},a) (st,a), Consider performing actions a a a Post environmental rewards R t + 1 R_{t+1} Rt+1, And performing actions a a a arrive s t + 1 s_{t+1} st+1 after , The greatest... That can be achieved by performing any action Q value max a Q ( a , s t + 1 ) \max_a Q(a,s_{t+1}) maxaQ(a,st+1), γ \gamma γ Is the discount factor .
The new Q The value of , More conservative updates are generally used Q The method of table , That is to introduce relaxation variable a l p h a alpha alpha , Update as follows , bring Q The iteration of the table changes more smoothly . Q ( s t , a ) = ( 1 − α ) × Q ( s t , a ) + α × ( R t + 1 + γ × max a Q ( a , s t + 1 ) ) Q(s_{t},a) = (1-\alpha) \times Q(s_{t},a) + \alpha \times(R_{t+1} + \gamma \times\max_a Q(a,s_{t+1})) Q(st,a)=(1−α)×Q(st,a)+α×(Rt+1+γ×amaxQ(a,st+1))
3.2.2 Choice of robot action
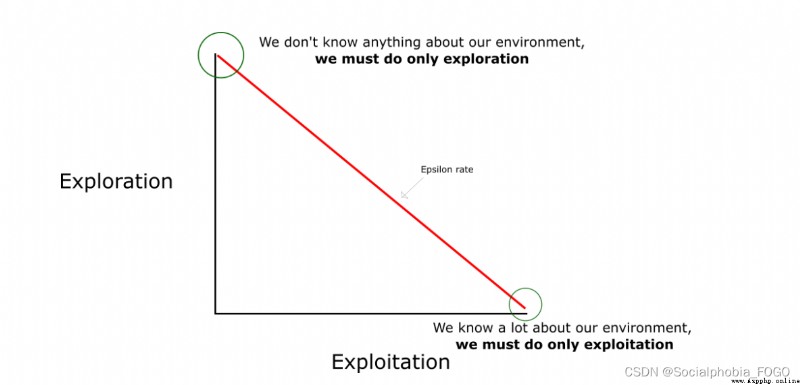
In reinforcement learning , Explore - utilize The problem is very important . say concretely , According to the definition above , Will try to make the robot choose the best decision every time , To maximize long-term rewards . But it has the following disadvantages :
In the preliminary study ,Q The value is not accurate , If at this time in accordance with Q Value to select , That would make a mistake .
After a period of study , The robot's path will be relatively fixed , So robots can't explore the environment effectively .
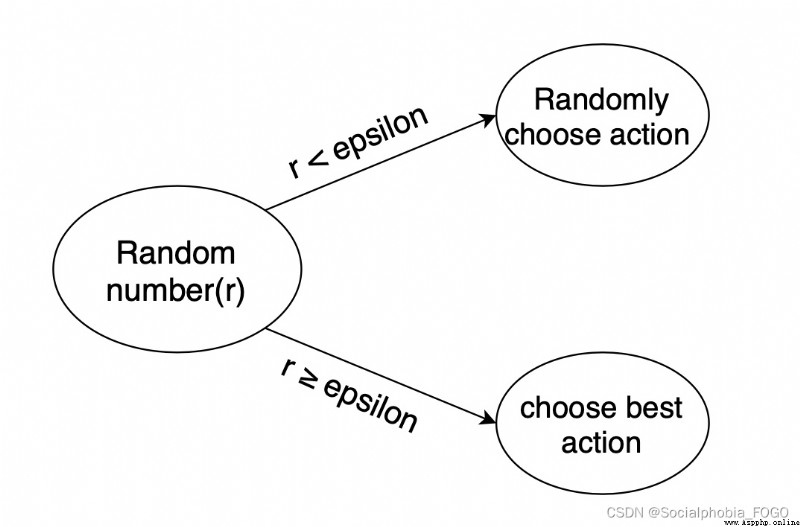
So a way is needed , To solve the above problems , Increase robot exploration . You usually use epsilon-greedy Algorithm :
When the robot chooses action , Choose actions randomly with a part of the probability , With a partial probability according to the optimal Q It's worth choosing actions .
meanwhile , The probability of choosing random action should decrease gradually with the training process .
3.2.3 Q-Learning Algorithm learning process 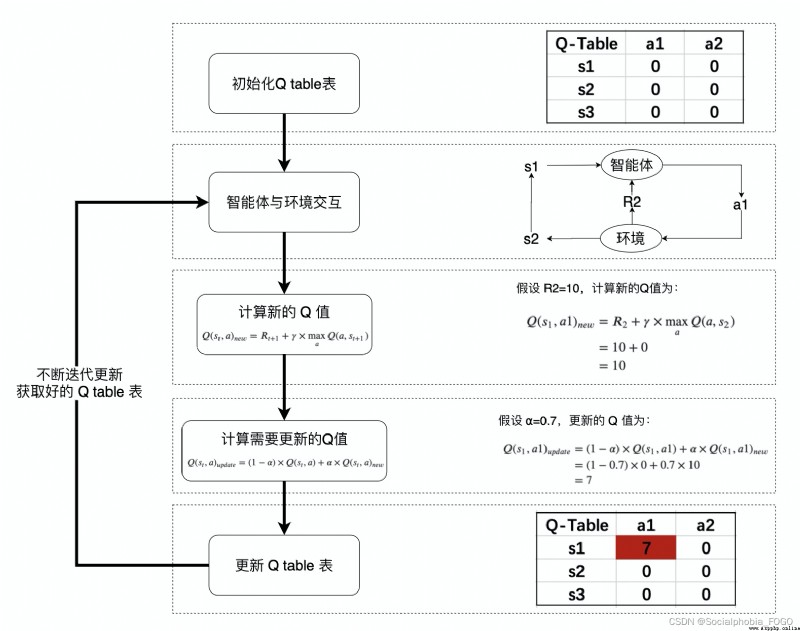
3.2.4 Robot class
Provided in this assignment QRobot class , In which Q Table iteration and robot action selection strategy , It can be done by from QRobot import QRobot Import and use .
QRobot The core member method of the class
sense_state(): Get the current position of the robot
return: The position coordinates of the robot , Such as : (0, 0)
current_state_valid_actions(): Get the action that the current robot can legally move
return: A list of current legal actions , Such as : [‘u’,‘r’]
train_update(): In training status , according to QLearning Algorithm strategy execution action
return: The currently selected action , And the reward for performing the current action , Such as : ‘u’, -1
test_update(): In test state , according to QLearning Algorithm strategy execution action
return: The currently selected action , And the reward for performing the current action , Such as :‘u’, -1
reset()
return: Reset the position of the robot in the maze
3.2.5 Runner class
QRobot Class implements the QLearning Algorithm Q Value iteration and action selection strategy . In the training process of robot automatic maze walking , Need constant use QLearning Algorithm to iteratively update Q Value table , To achieve a “ The optimal ” The state of , Therefore, a class is encapsulated Runner For robot training and visualization . It can be done by from Runner import Runner Import and use .
Runner The core member method of the class :
run_training(training_epoch, training_per_epoch=150): Training robot , Constantly updated Q surface , And save the training results in the member variable train_robot_record in
training_epoch, training_per_epoch: Total training times 、 The maximum number of steps the robot can move per training
run_testing(): Test whether the robot can get out of the maze
generate_gif(filename): Output the training results to the specified gif In the picture
filename: Legal file path , The file name needs to be .gif For the suffix
plot_results(): Show the indicators in the training process with charts :Success Times、Accumulated Rewards、Runing Times per Epoch
DQN The algorithm uses neural network to approximate the value function , The algorithm block diagram is as follows .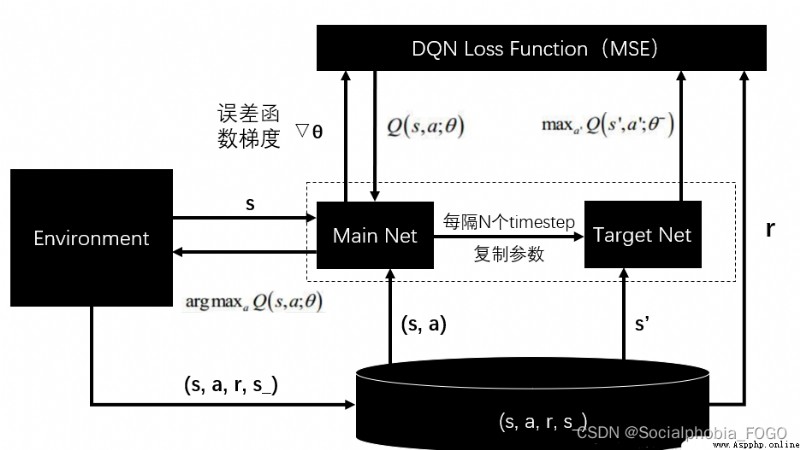
In this experiment , The provided neural network is used to predict the evaluation scores of four actions , At the same time, the evaluation score is output .
ReplayDataSet The core member method of the class
add(self, state, action_index, reward, next_state, is_terminal) Add a piece of training data
state: Current robot position
action_index: Select the index to perform the action
reward: The reward for performing the action
next_state: The position of the robot after performing the action
is_terminal: Whether the robot has reached the termination node ( Reach the end or hit the wall )
random_sample(self, batch_size): Extract fixed data at random from the data set batch_size The data of
batch_size: Integers , It is not allowed to exceed the number of data in the dataset
build_full_view(self, maze): Open the golden finger , Get full view
maze: With Maze An object instantiated by a class
Write a depth first search algorithm , And test , By using the stack , To iterate layer by layer , Finally search out the path . The main process is , The entry node acts as the root node , Then check whether this node has been explored and whether there are child nodes , If the conditions are met, expand the node , Put the child nodes of this node on the stack in order . If you explore a node , This node is not the end point and has no child nodes that can be expanded , Then this point will be out of the stack , Cycle until the end point is found .
The test results are as follows :
if maze_size=5, Run the basic search algorithm , The final results are as follows :
The path searched : ['r', 'd', 'r', 'd', 'd', 'r', 'r', 'd']
congratulations , Reached the target point
Maze of size (5, 5)

chart 3 Basic search map (size5)
if maze_size=10, Run the basic search algorithm , The final results are as follows :
The path searched : ['r', 'r', 'r', 'r', 'r', 'r', 'r', 'd', 'r', 'd', 'd', 'd', 'r', 'd', 'd', 'd', 'l', 'd', 'd', 'r']
congratulations , Reached the target point
Maze of size (10, 10)
chart 4 Basic search map (size10)
if maze_size=20, Run the basic search algorithm , The final results are as follows :
The path searched : ['d', 'r', 'u', 'r', 'r', 'r', 'r', 'd', 'r', 'd', 'r', 'r', 'r', 'r', 'd', 'd', 'r', 'd', 'd', 'd', 'd', 'r', 'r', 'r', 'r', 'r', 'd', 'r', 'r', 'd', 'r', 'd', 'd', 'l', 'l', 'd', 'd', 'd', 'd', 'd', 'r', 'd', 'd', 'r']
congratulations , Reached the target point
Maze of size (20, 20)
chart 5 Basic search map (size20)
Part of the code is as follows :
def myDFS(maze):
""" Perform a depth first search on the maze :param maze: To search maze object """
start = maze.sense_robot()
root = SearchTree(loc=start)
queue = [root] # Node stack , Used for hierarchical traversal
h, w, _ = maze.maze_data.shape
is_visit_m = np.zeros((h, w), dtype=np.int) # Mark whether each position of the maze has been visited
path = [] # Record path
peek = 0
while True:
current_node = queue[peek] # The top element of the stack is the current node
#is_visit_m[current_node.loc] = 1 # Mark that the current node location has been accessed
if current_node.loc == maze.destination: # Reach the target point
path = back_propagation(current_node)
break
if current_node.is_leaf() and is_visit_m[current_node.loc] == 0: # If the point has a leaf node and is not expanded
is_visit_m[current_node.loc] = 1 # Mark that the point has been expanded
child_number = expand(maze, is_visit_m, current_node)
peek+=child_number # Carry out some stack operations
for child in current_node.children:
queue.append(child) # Leaf node stack
else:
queue.pop(peek) # If there is no way to go, get out of the stack
peek-=1
return path
In the process of algorithm training , First read the current position of the robot , Then add the current state to Q In the value table , If the current status already exists in the table, you do not need to add it repeatedly . after , The actions needed to generate the robot , And return the map reward value 、 Find the current position of the robot . Then check again and update Q Value table , Attenuate the possibility of randomly selected actions .
QLearning In the process of algorithm implementation , It's mainly about Q The calculation update of the value table has been modified and adjusted , Adjusted Q The value table performs well at run time , The calculation is fast and accurate 、 High stability . Then the decay rate of the possibility of randomly selected actions is adjusted . Because during the test, it was found that , If the attenuation is too slow, it will lead to too strong randomness , Indirectly weaken the role of reward , So finally through the adjustment , It is found that the attenuation rate is taken as 0.5 It is an excellent and stable value .
Part of the code is as follows :
def train_update(self):
""" Select the action in the training state , And update relevant parameters :return :action, reward Such as :"u", -1 """
self.state = self.maze.sense_robot() # Get the original maze position of the robot
# retrieval Q surface , If the current state does not exist, add and enter Q surface
if self.state not in self.q_table:
self.q_table[self.state] = {
a: 0.0 for a in self.valid_action}
action = random.choice(self.valid_action) if random.random() < self.epsilon else max(self.q_table[self.state], key=self.q_table[self.state].get) # action The action selected for the robot
reward = self.maze.move_robot(action) # Move the robot in a given direction ,reward Reward value returned for maze
next_state = self.maze.sense_robot() # Get the position of the robot after executing the command
# retrieval Q surface , If the current next_state If it doesn't exist, add it into Q surface
if next_state not in self.q_table:
self.q_table[next_state] = {
a: 0.0 for a in self.valid_action}
# to update Q Value table
current_r = self.q_table[self.state][action]
update_r = reward + self.gamma * float(max(self.q_table[next_state].values()))
self.q_table[self.state][action] = self.alpha * self.q_table[self.state][action] +(1 - self.alpha) * (update_r - current_r)
self.epsilon *= 0.5 # Attenuate the possibility of randomly selecting actions
return action, reward
The test results are as follows :
if maze_size=3, Run reinforcement learning search algorithm , The final results are as follows :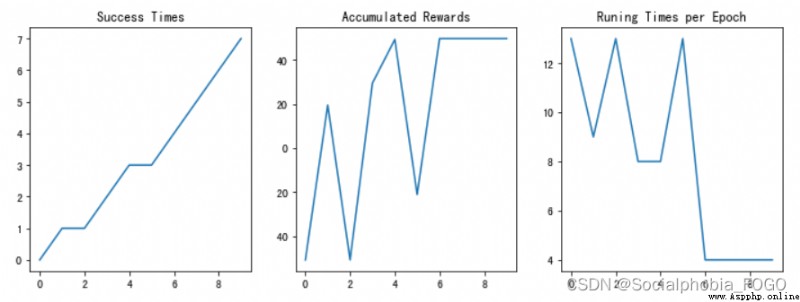
chart 6 Reinforcement learning search gif Map (size3)
 chart 7 Training results
chart 7 Training results
if maze_size=5, Run reinforcement learning search algorithm , The final results are as follows :
chart 8 Reinforcement learning search gif Map (size5)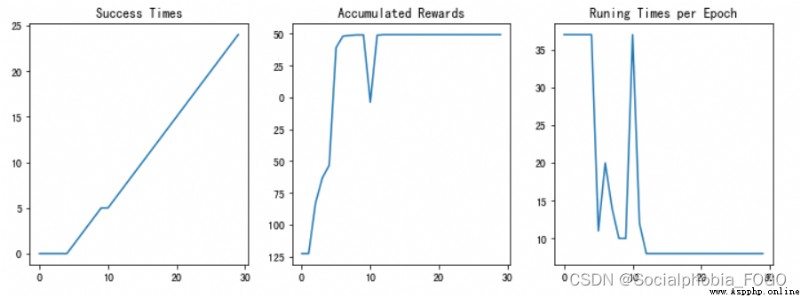 chart 9 Training results
chart 9 Training results
if maze_size=10, Run reinforcement learning search algorithm , The final results are as follows :
chart 10 Reinforcement learning search gif Map (size10)
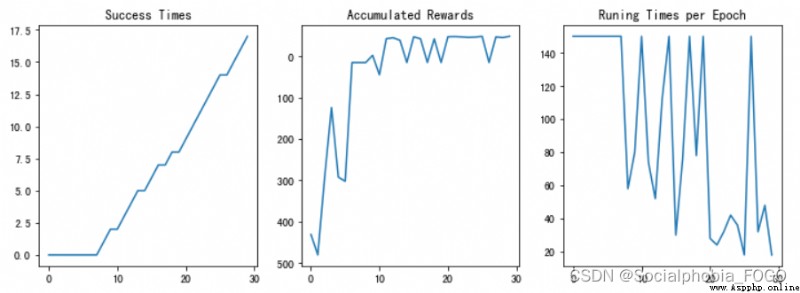
chart 11 Training results
if maze_size=11, Run reinforcement learning search algorithm , The final results are as follows :
chart 12 Reinforcement learning search gif Map (size11)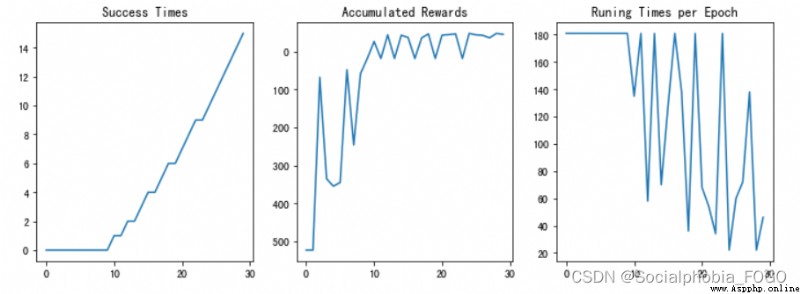
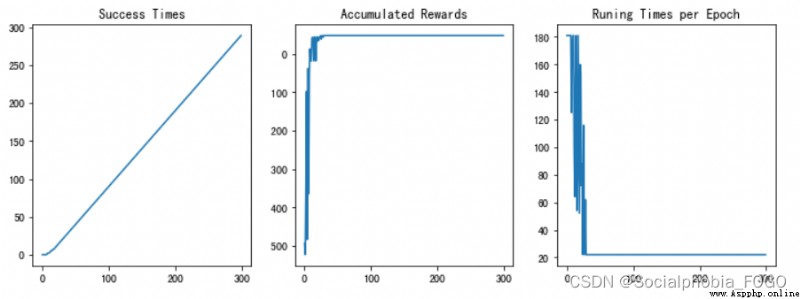
chart 13 Training results
After testing , Reinforcement learning search algorithm can quickly give the path out of the maze, and with the increase of training rounds , The success rate is also rising . When the training rounds are enough , Finally, the later accuracy can reach 100%.
stay Q-Learning On the basis of , Use neural networks to estimate evaluation scores , Used for actions after a decision . Just in Q-Learning The corresponding part can be replaced by the output of neural network .
The test results are as follows :
if maze_size=3, function DQN Algorithm , The final results are as follows :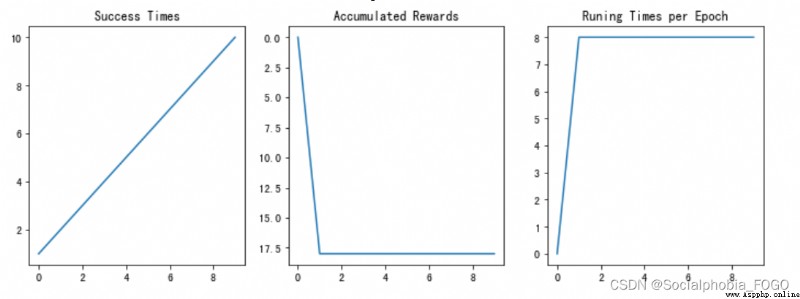
chart 14 Training results
if maze_size=5, function DQN Algorithm , The final results are as follows :
chart 15 Training results
if maze_size=10, function DQN Algorithm , The final results are as follows :
chart 16 Training results
4.4.1 Test the basic search algorithm 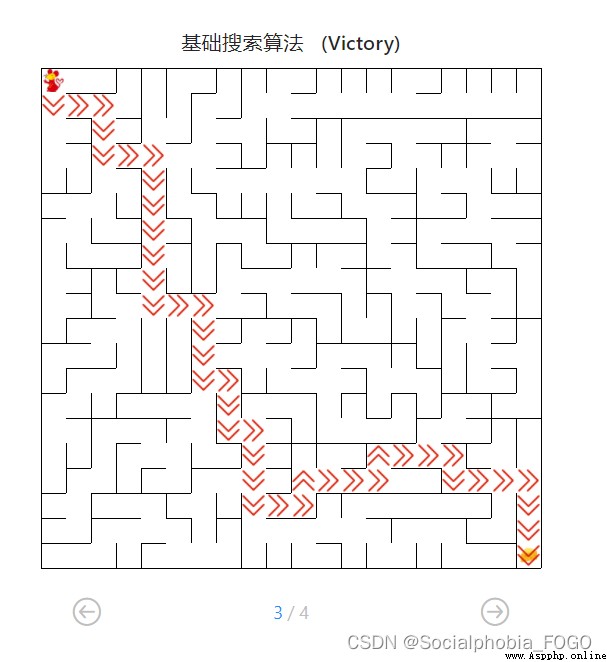
chart 17 Basic search algorithm path
when 0 second
4.4.2 Reinforcement learning algorithm ( primary )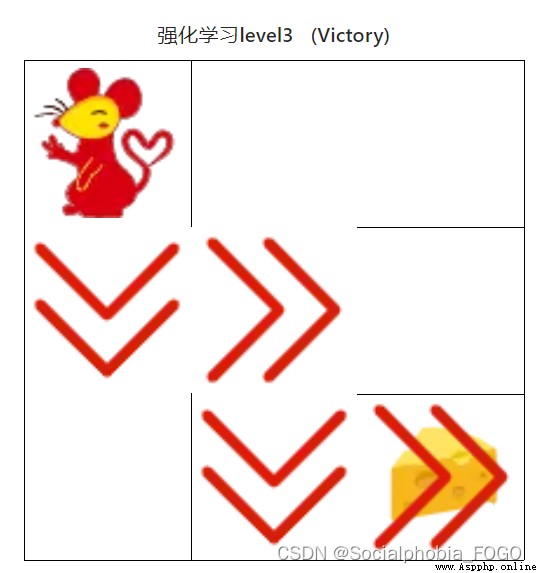
chart 18 Reinforcement learning algorithm ( primary )
when 0 second
4.4.3 Reinforcement learning algorithm ( intermediate )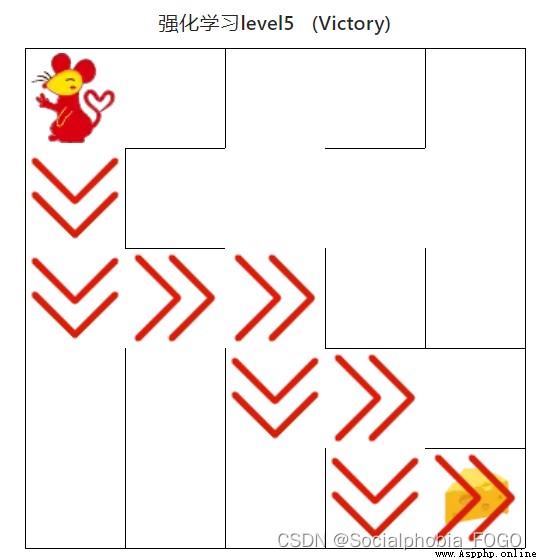
chart 19 Reinforcement learning algorithm ( intermediate )
when 0 second
4.4.4 Reinforcement learning algorithm ( senior )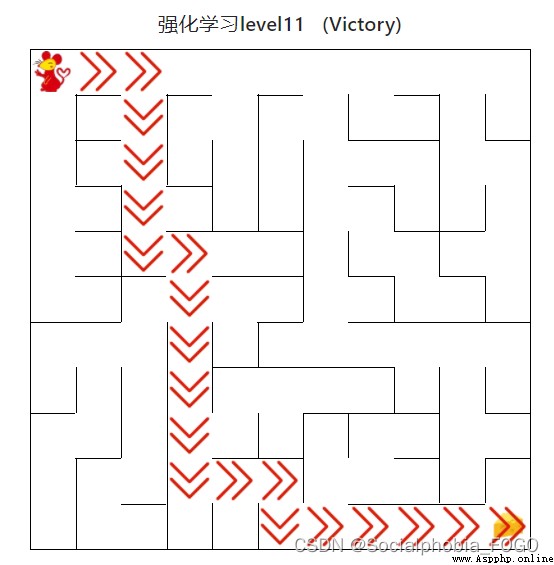
chart 20 Reinforcement learning algorithm ( senior )
when 0 second
4.4.5 DQN Algorithm ( primary )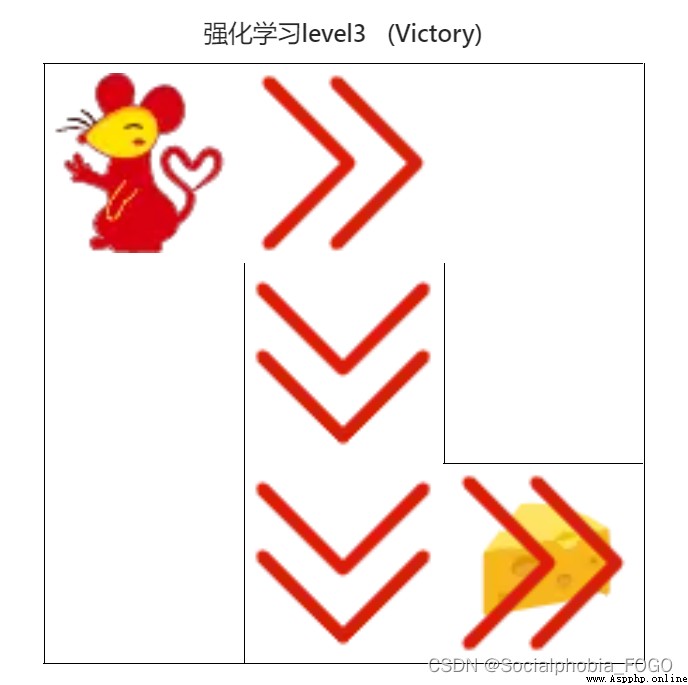
chart 21 DQN Algorithm ( primary )
when 2 second
4.4.6 DQN Algorithm ( intermediate )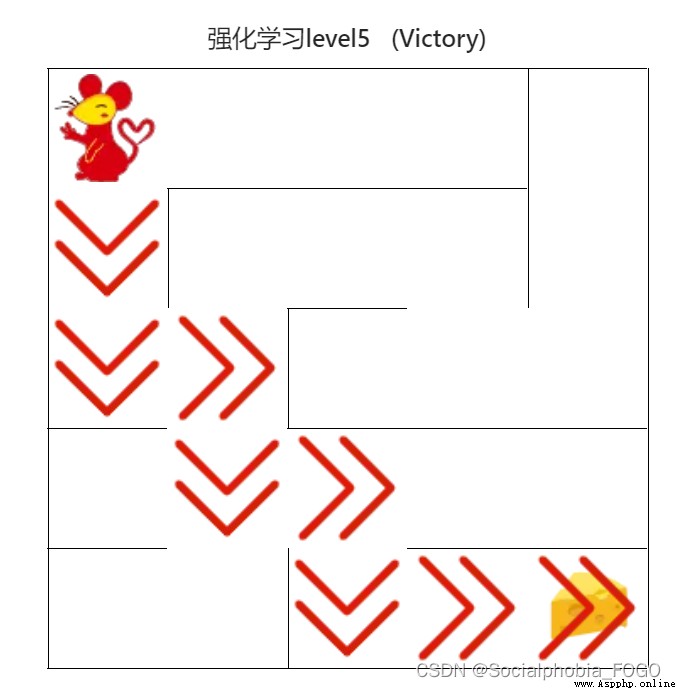
chart 22 DQN Algorithm ( intermediate )
when 3 second
4.4.7 DQN Algorithm ( senior )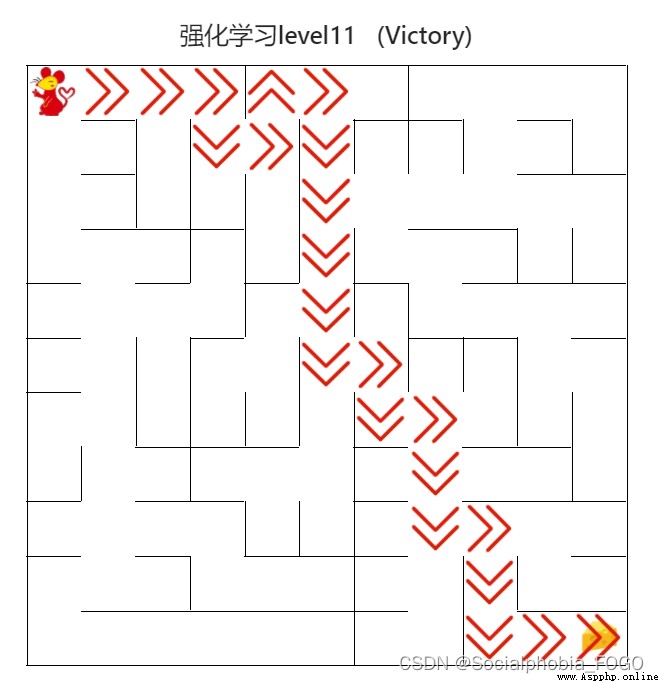
chart 23 DQN Algorithm ( senior )
when 105 second
Compare basic search algorithms 、 Reinforcement learning search algorithm and DQN The algorithm can find , When the training rounds are increased to a large number , The three algorithms are fast and have high accuracy .DQN The algorithm takes a long time , But the performance is stable .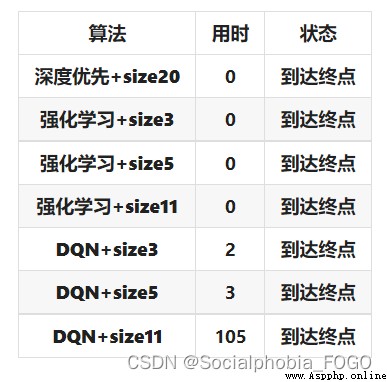
Through this experiment , Learned the specific working methods of a variety of basic search algorithms , And these basic search algorithms are implemented in practice ; At the same time, I learned the working principle and application mode of reinforcement learning search algorithm , Let me have a deeper understanding of these methods , Also have a deeper understanding of each link , Benefited greatly .
Program listing :
# Import related packages
import os
import random
import numpy as np
import torch
from QRobot import QRobot
from ReplayDataSet import ReplayDataSet
from torch_py.MinDQNRobot import MinDQNRobot as TorchRobot # PyTorch edition
import matplotlib.pyplot as plt
# ------ Basic search algorithm -------
def my_search(maze):
# The robot moves in the same direction
move_map = {
'u': (-1, 0), # up
'r': (0, +1), # right
'd': (+1, 0), # down
'l': (0, -1), # left
}
# Maze path search tree
class SearchTree(object):
def __init__(self, loc=(), action='', parent=None):
""" Initialize the search tree node object :param loc: The position of the robot of the new node :param action: The corresponding movement direction of the new node :param parent: The parent node of the new node """
self.loc = loc # Current node location
self.to_this_action = action # The action of reaching the current node
self.parent = parent # Parent of current node
self.children = [] # Children of the current node
def add_child(self, child):
""" Add child nodes :param child: Child nodes to be added """
self.children.append(child)
def is_leaf(self):
""" Judge whether the current node is a leaf node """
return len(self.children) == 0
def expand(maze, is_visit_m, node):
""" Expand leaf nodes , That is, add the child nodes that arrive after performing legal actions for the current leaf node :param maze: Maze object :param is_visit_m: A matrix that records whether each location in the maze is accessed :param node: Leaf nodes to be expanded """
child_number = 0 # Record the number of leaf nodes
can_move = maze.can_move_actions(node.loc)
for a in can_move:
new_loc = tuple(node.loc[i] + move_map[a][i] for i in range(2))
if not is_visit_m[new_loc]:
child = SearchTree(loc=new_loc, action=a, parent=node)
node.add_child(child)
child_number+=1
return child_number # Returns the number of leaf nodes
def back_propagation(node):
""" Trace back and record the node path :param node: Node to be backtracked :return: Back to the path """
path = []
while node.parent is not None:
path.insert(0, node.to_this_action)
node = node.parent
return path
def myDFS(maze):
""" The depth of the maze :param maze: To search maze object """
start = maze.sense_robot()
root = SearchTree(loc=start)
queue = [root] # Node stack , Used for hierarchical traversal
h, w, _ = maze.maze_data.shape
is_visit_m = np.zeros((h, w), dtype=np.int) # Mark whether each position of the maze has been visited
path = [] # Record path
peek = 0
while True:
current_node = queue[peek] # The top element of the stack is the current node
#is_visit_m[current_node.loc] = 1 # Mark that the current node location has been accessed
if current_node.loc == maze.destination: # Reach the target point
path = back_propagation(current_node)
break
if current_node.is_leaf() and is_visit_m[current_node.loc] == 0: # If the point has a leaf node and is not expanded
is_visit_m[current_node.loc] = 1 # Mark that the point has been expanded
child_number = expand(maze, is_visit_m, current_node)
peek+=child_number # Carry out some stack operations
for child in current_node.children:
queue.append(child) # Leaf node stack
else:
queue.pop(peek) # If there is no way to go, get out of the stack
peek-=1
# Out of the team
#queue.pop(0)
return path
path = myDFS(maze)
return path
# -------- Reinforcement learning algorithm ---------
# Import related packages
import random
from Maze import Maze
from Runner import Runner
from QRobot import QRobot
class Robot(QRobot):
valid_action = ['u', 'r', 'd', 'l']
def __init__(self, maze, alpha=0.5, gamma=0.9, epsilon=0.5):
""" initialization Robot class :param maze: Maze object """
self.maze = maze
self.state = None
self.action = None
self.alpha = alpha
self.gamma = gamma
self.epsilon = epsilon # Random selection probability of action
self.q_table = {
}
self.maze.reset_robot() # Reset robot status
self.state = self.maze.sense_robot() # state Is the current state of the robot
if self.state not in self.q_table: # If the current state does not exist , Then for Q Add a new column to the table
self.q_table[self.state] = {
a: 0.0 for a in self.valid_action}
def train_update(self):
""" Select the action in the training state , And update relevant parameters :return :action, reward Such as :"u", -1 """
self.state = self.maze.sense_robot() # Get the original maze position of the robot
# retrieval Q surface , If the current state does not exist, add and enter Q surface
if self.state not in self.q_table:
self.q_table[self.state] = {
a: 0.0 for a in self.valid_action}
action = random.choice(self.valid_action) if random.random() < self.epsilon else max(self.q_table[self.state], key=self.q_table[self.state].get) # action The action selected for the robot
reward = self.maze.move_robot(action) # Move the robot in a given direction ,reward Reward value returned for maze
next_state = self.maze.sense_robot() # Get the position of the robot after executing the command
# retrieval Q surface , If the current next_state If it doesn't exist, add it into Q surface
if next_state not in self.q_table:
self.q_table[next_state] = {
a: 0.0 for a in self.valid_action}
# to update Q Value table
current_r = self.q_table[self.state][action]
update_r = reward + self.gamma * float(max(self.q_table[next_state].values()))
self.q_table[self.state][action] = self.alpha * self.q_table[self.state][action] +(1 - self.alpha) * (update_r - current_r)
self.epsilon *= 0.5 # Attenuate the possibility of randomly selecting actions
return action, reward
def test_update(self):
""" Select the action in the test state , And update relevant parameters :return :action, reward Such as :"u", -1 """
self.state = self.maze.sense_robot() # Get the maze position where the robot is now
# retrieval Q surface , If the current state does not exist, add and enter Q surface
if self.state not in self.q_table:
self.q_table[self.state] = {
a: 0.0 for a in self.valid_action}
action = max(self.q_table[self.state],key=self.q_table[self.state].get) # Choose action
reward = self.maze.move_robot(action) # Move the robot in a given direction
return action, reward
import random
import numpy as np
import torch
from QRobot import QRobot
from ReplayDataSet import ReplayDataSet
from torch_py.MinDQNRobot import MinDQNRobot as TorchRobot # PyTorch edition
import matplotlib.pyplot as plt
from Maze import Maze
import time
from Runner import Runner
class Robot(TorchRobot):
def __init__(self, maze):
""" initialization Robot class :param maze: Maze object """
super(Robot, self).__init__(maze)
maze.set_reward(reward={
"hit_wall": 5.0,
"destination": -maze.maze_size ** 2.0,
"default": 1.0,
})
self.maze = maze
self.epsilon = 0
""" Open the golden finger , Get full view """
self.memory.build_full_view(maze=maze)
self.loss_list = self.train()
def train(self):
loss_list = []
batch_size = len(self.memory)
while True:
loss = self._learn(batch=batch_size)
loss_list.append(loss)
success = False
self.reset()
for _ in range(self.maze.maze_size ** 2 - 1):
a, r = self.test_update()
if r == self.maze.reward["destination"]:
return loss_list
def train_update(self):
def state_train():
state=self.sense_state()
return state
def action_train(state):
action=self._choose_action(state)
return action
def reward_train(action):
reward=self.maze.move_robot(action)
return reward
state = state_train()
action = action_train(state)
reward = reward_train(action)
return action, reward
def test_update(self):
def state_test():
state = torch.from_numpy(np.array(self.sense_state(), dtype=np.int16)).float().to(self.device)
return state
state = state_test()
self.eval_model.eval()
with torch.no_grad():
q_value = self.eval_model(state).cpu().data.numpy()
def action_test(q_value):
action=self.valid_action[np.argmin(q_value).item()]
return action
def reward_test(action):
reward=self.maze.move_robot(action)
return reward
action = action_test(q_value)
reward = reward_test(action)
return action, reward