Le contrôle des risques de crédit est l'une des applications les plus réussies de l'algorithme d'exploration des données,C'est parce qu'il y a beaucoup de données sur le secteur du crédit financier,Le scénario de la demande est clair et riche.
Le contrôle du risque de crédit consiste simplement à juger si quelqu'un a emprunté de l'argent.(Date de remboursement du mois suivant)Tu vas payer comme prévu?.Plus professionnel,Le contrôle des risques de crédit est une considération globale de la capacité de remboursement et de la volonté de remboursement,Prêter sur la base de ce jugement préalable,Cela améliore considérablement l'efficacité des opérations financières..
Contrairement à d'autres scénarios industriels d'apprentissage automatique,La finance est un domaine où l'aversion pour le risque est extrême,Sa particularité réside dans l'accent mis sur l'interprétation et la stabilité du modèle..La pratique courante dans l'industrie consiste à établir un ensemble de règles et de modèles de contrôle des risques interprétables et efficaces pour chaque commande en fonction des caractéristiques multidimensionnelles de l'exploitation minière./Utilisateurs/Prendre des décisions de jugement.
Parmi eux,Pour(Avant le prêt)Modèle de contrôle des risques avant application,Aussi appelé carte de pointage de demande--ACarte.ALa carte est un modèle clé de contrôle des risques,Le Consensus de l'industrie est que les cartes de pointage des demandes peuvent être écrasées80%Risque de crédit.En outre, il y a une carte de notation de comportement de prêtBCarte、Collecte de la carte de pointageCCarte,Et des modèles antifraude, etc..
ACarte(Application score card).L'objectif est de prévoir, au moment de la demande(Demande de carte de crédit、Demande de prêt)Évaluation quantitative du demandeur.BCarte(Behavior score card).L'objectif est de prévoir le moment de l'utilisation(Obtenir un prêt、Durée d'utilisation de la carte de crédit)Probabilité d'être en retard dans un certain temps.CCarte(Collection score card).L'objectif est de prévoir la probabilité d'un remboursement dans un certain temps après l'expiration du délai et le début de la phase de recouvrement.
Une bonne caractéristique , Il est essentiel pour les modèles et les règles . Comme demander une carte de pointage --ACarte, Il peut être classé comme suit 3 Caractéristiques des aspects :
1、 Historique du crédit : Nombre et limites des opérations de crédit 、 Ratio recettes / passif 、 Nombre de demandes de crédit 、 Durée historique du crédit 、 Nombre de nouveaux comptes de crédit ouverts 、 Taux d'utilisation des quotas 、 Nombre et montant des retards 、 Type de produit de crédit 、 Informations récupérées .( L'importance des caractéristiques des opérations de crédit est souvent la plus élevée , Moins d'informations sur la capacité et la volonté historiques de remboursement , Les modèles de contrôle des risques sont souvent abandonnés. .)
2、 Données de base et types de transactions :Âge、Situation matrimoniale、Études、 Type d'emploi et salaire annuel 、Revenus salariaux、DépôtsAUM、Situation des actifs、 Fonds d'accumulation et paiement des impôts 、 Flux des opérations autres que le crédit ( Cette catégorie est principalement considérée globalement en termes de capacité de remboursement. . Il peut également combiner la vérification multipartite de l'authenticité des données et le partage des numéros de téléphone cellulaire. 、 Information sur la fraude de groupe, comme le numéro d'identification , Utilisé pour identifier les risques de fraude .Attention, Genre 、Couleur de peau、Région géographique、Race、 Les types de caractéristiques comme les croyances religieuses doivent être utilisés avec prudence , Peut - être que le modèle fonctionnera , Mais il peut aussi causer des problèmes de discrimination algorithmique .)
3、 Public negative record class : Comme les dettes de faillite 、 Jugements civils 、Sanctions administratives、 Exécution judiciaire 、 Une liste noire de tricheurs, etc ( Ce type de caractéristique n'a pas nécessairement accès aux données , Et le degré de perte est généralement élevé , Contribution générale au modèle , Plus de volonté de remboursement / Considérations relatives à la dimension fraude )
Dans la partie pratique, nous prenons l'exemple de la carte de pointage d'application classique , Ensemble de données utilisé pour le concours de prévision du défaut de paiement des prêts personnels de la Banque centrale , Utilisez la cote de crédit pythonBibliothèque--toad、Modèle d'arbreLightgbm Et la régression logique LR Faire un modèle de notation des demandes .(Note:: Quelques termes financiers impliqués dans le texte , Pas d'explication en raison de l'espace , Questions Google peut comprendre .)
La définition du modèle de notation de l'application consiste principalement à déterminer l'échantillon et l'étiquette du modèle à l'aide d'une série d'analyses de données. .
Tout d'abord,, Ajouter quelques explications sur la terminologie du contrôle des risques financiers . Si le concept est vague , Je peux vérifier et comprendre :
Nombre de délais(M) :Désigne le nombre de jours en retard entre la date de remboursement réelle et la date d'échéance, État des retards par intervalle .MExtrait deMonth on BookLe premier mot de.(Note:: Les divisions d'intervalles définies par les différentes institutions peuvent varier ) M0:Actuellement en retard(OuCReprésentation,Extrait deCurrent) M1:En retard1-30Jour M2:En retard31-60Jour M3:En retard61-90Jour M4:En retard91-120Jour M5:En retard121-150Jour M6:En retard151-180Jour M7+:En retard180Plus de jours
Point d'observation: Fenêtre temporelle au niveau de l'échantillon . Point dans le temps utilisé pour construire l'ensemble d'échantillons (Par exemple:2010Année10 Les utilisateurs qui demandent un prêt en mois ), Différentes définitions de liens sont différentes ,Plus abstrait,Voici quelques exemples: Si c'est un modèle de demande , Le point d'observation est défini comme le temps de demande de prêt de l'utilisateur. ,Prends - le.19Année1-12 Toutes les demandes de prêt mensuelles sont utilisées comme échantillon de construction ; Si c'est un modèle de comportement de prêt , Un point d'observation est défini comme une date spécifique ,Oui.19Année6Mois15 Prêt quotidien 、 Exemple de construction d'une demande de prêt sans retard .
Période d'observation: Fenêtre temporelle au niveau des caractéristiques . Fenêtre temporelle relative des caractéristiques de construction , Par exemple, avant que l'utilisateur demande un prêt 12Dans les mois(2009Année10 Fin du mois 2010Année10 Les données mensuelles avant la demande de prêt sont disponibles , Peut avoir le montant moyen de la consommation de l'utilisateur 、Nombre de fois、 Caractéristiques des données telles que le nombre de prêts ). La période d'observation est définie pour aligner les caractéristiques de chaque échantillon , La longueur est généralement déterminée par les données .Un point à noter est, Seulement cette fois. Avant la demandeDonnées caractéristiques de, Sinon, les données seront compromises (Passage du temps, Prévoir les phénomènes passés avec l'avenir ).
Période de performance: Fenêtre temporelle au niveau de l'étiquette . Définir les bonnes et les mauvaises étiquettes YFenêtre de temps pour, Le risque de crédit a un décalage naturel , Parce que l'utilisateur emprunte un mois (Première phase) J'ai commencé à rembourser. , Il est possible qu'il ait fallu plusieurs périodes avant que le retard ne se produise .
Pour les données de course disponibles , Durée des caractéristiques des données (Période d'observation)、Échantillons de données、 Les définitions des étiquettes ont été analysées à l'avance. . Mais pour les affaires réelles, , L'échantillon de données et la définition du modèle sont également essentiels à la demande de carte de pointage. . Après tout, il n'y a peut - être pas de données ou d'étiquettes disponibles dans la scène réelle. ( Définition du bien et du mal , Certaines entreprises analysent leurs activités à l'avance pour les modélisateurs ), Et c'est aussi simple qu'un modèle de classification .
Déterminer la taille de l'échantillon et l'étiquette pour la modélisation , C'est - à - dire combien d'échantillons de données le modèle apprend à distinguer les bons 、 Mauvais échantillon d'étiquettes . Si la taille de l'échantillon est faible 、 Il y a un problème avec la définition de l'étiquette , Les résultats de l'étude seront probablement mauvais .
Détermination de la taille de l'échantillon de modélisation , Empiriquement, plus il y a d'échantillons qui répondent aux critères de modélisation, mieux c'est. , Il est préférable qu'une catégorie ait plus de quelques milliers d'échantillons .Mais... Pour la définition de l'étiquette , Peut - être que notre intuition est plus simple ,Par exemple,“ Un bon utilisateur est un utilisateur qui n'a pas de retard , Un mauvais utilisateur est un utilisateur en retard ”, Mais ce n'est pas facile à quantifier. , Il y a deux principaux facteurs à prendre en considération :
【 Mauvaise définition 】 Combien de jours de retard est considéré comme un mauvais client .Par exemple,: Seulement en retard 2 Dieu est un mauvais client pour la modélisation ?
Conformément aux directives de Bâle ,Généralement en retard90Oh, mon Dieu.(M4+)Clients, C'est - à - dire défini comme un mauvais client . Plus générique ,Peut être utilisé“Taux de roulement”Méthodes d'analyse(Roll Rate Analysis) Déterminer combien de jours est “Mauvais”, La méthode de base est l'analyse statistique des retards M Quelle est la probabilité que le client soit en retard? M+1Période(La même chose., Il est peu probable que nous attendions que tous nos clients aient un an de retard pour nous assurer qu'il est un mauvais client. . Le coût du temps est trop élevé , Il y aura moins d'échantillons de données ).Voici un exemple:, Nous analysons la probabilité de détérioration de chaque période en retard au moyen d'un taux de roulement. .Actuellement en retard(M0) Probabilité de ne pas être en retard le mois prochain 99.71%;Actuellement en retardM1, La probabilité de retard continu le mois prochain est 54.34%;En coursM2 La probabilité de continuer à être en retard le mois prochain est aussi élevée que *90.04%*.Nous pouvons voirM2 C'est un point d'inflexion évident. ,Peut prendreM2+ Comme définition d'un mauvais échantillon .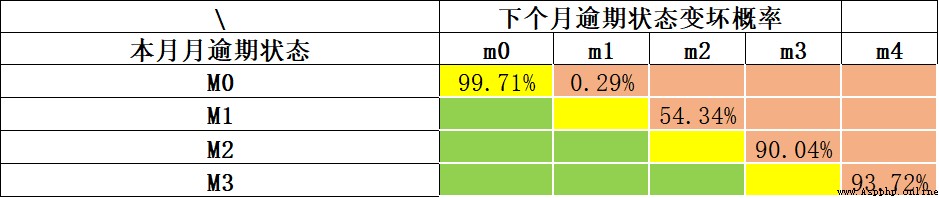
【Période de performance】 Moment de la demande de prêt (C'est - à - dire::Point d'observation) Combien de temps après l'exposition , Pour déterminer si le client est en retard .Par exemple,: Après avoir prêté de l'argent, j'ai observé un client 60 Tous les versements de la journée ont été effectués à temps. , Pour juger s'il est bon /Mauvais client?
C'est - à - dire déterminer la période de rendement , Les méthodes d'analyse couramment utilisées sont VintageAnalyse(Vintage Dans le domaine du crédit, il ne s'agit pas seulement d'évaluer le temps nécessaire pour que les clients soient pleinement exposés. , C'est - à - dire la maturité , Il peut également être utilisé pour analyser les différences entre les stratégies de contrôle des risques à différentes périodes. ), Accumuler la tendance à l'augmentation de l'exposition des mauvais utilisateurs en analysant l'historique , Pour déterminer le nombre minimum de périodes nécessaires pour exposer la plupart des mauvais clients. . La mauvaise définition de l'exemple suivant est M4+, Nous pouvons voir les numéros M4+ Mauvais client passé 9Ou10 Une performance d'environ un mois , En gros, tout est exposé. , Le nombre total de mauvais clients à l'arrière est relativement stable . Ici, nous pouvons positionner la période de performance 9Ou10Mois~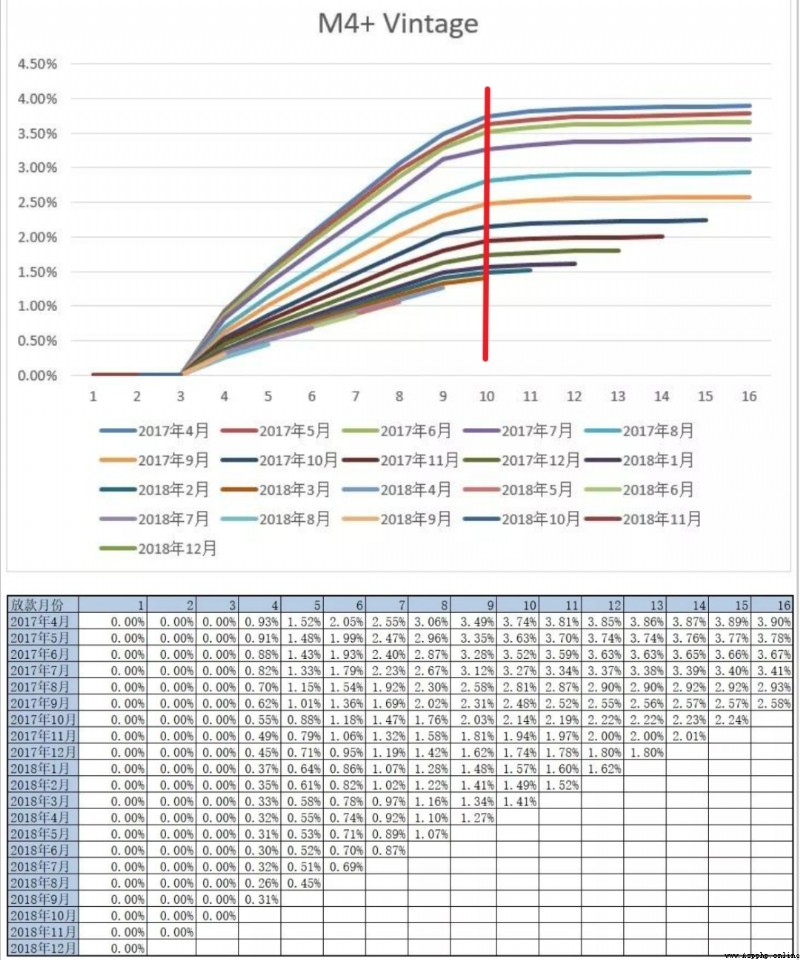
Une mauvaise définition et la période de rendement requise ont été identifiées , Nous pouvons déterminer l'étiquette de l'échantillon , Échantillons de modélisation finalement délimités :
Bon utilisateur:Période de performance(Par exemple:9Mois) Aucun échantillon d'utilisateurs en retard .
Mauvais utilisateur:Période de performance(Par exemple:9Mois) Retard interne (Par exemple:M2+) Échantillons d'utilisateurs pour .
Utilisateurs gris : Comportement en retard au cours de la période de performance , Mais pas mal défini (Par exemple:M2+)Échantillons.Note:: Dans la pratique, les délais sont souvent dépassés. 3 Les utilisateurs dans les jours sont également classés comme de bons utilisateurs .
Par exemple, l'heure est 2022-10Fin du mois,Période de performance9Dans un mois.,On peut l'avoir.2022-01 Exemple de demande pour le mois et avant (C'est aussi connu sous le nom de Point d'observation), étiqueter bon ou mauvais ,Modélisation.
Par l'introduction de la notation de crédit ci - dessus , Il est clair que les bons utilisateurs sont généralement beaucoup plus grands que les mauvais. , C'est un scénario typique où les catégories sont très inégales , Une approche déséquilibrée est examinée ci - dessous .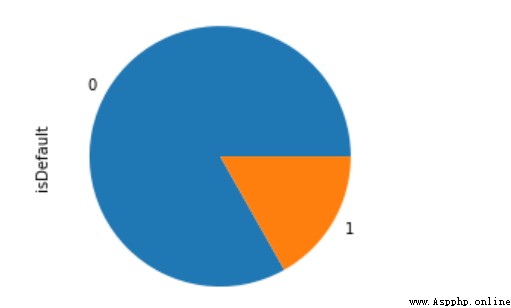
Documents du dictionnaire de données pour cet ensemble de données 、 Introduction au concours et Code de cet article ,Peut atteindrehttps://github.com/aialgorithm/Blog Téléchargement du Répertoire de codes correspondant au projet
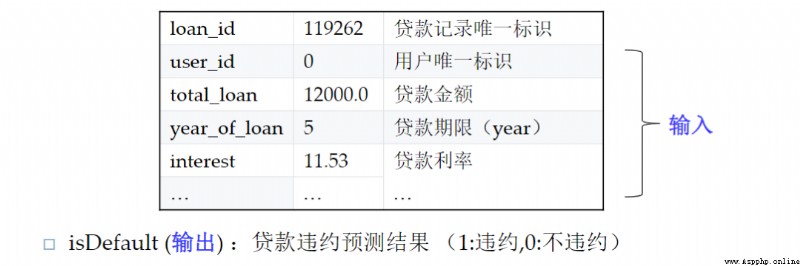
L'ensemble de données est l'ensemble de données de prévision du défaut de paiement des prêts personnels de la Banque centrale. , Les champs individuels sont désensibilisés ( La plupart des données financières sont confidentielles ). Les principaux champs caractéristiques contiennent des renseignements personnels de base 、Capacité économique、 Historique du prêt, etc 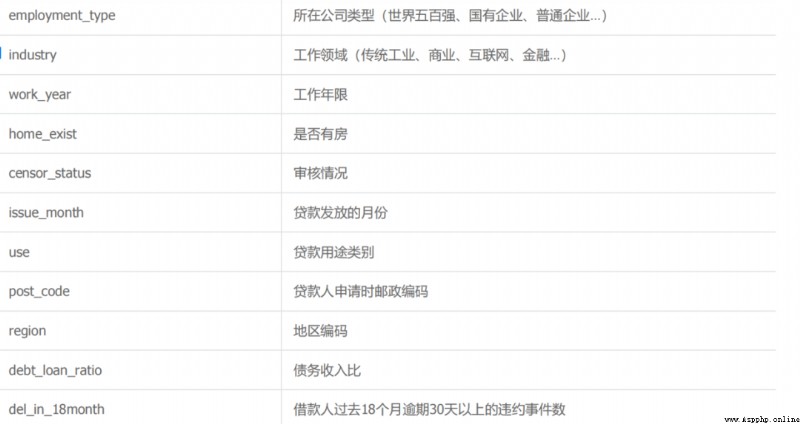 Données disponibles10000Échantillons,38 Caractéristiques primitives des dimensions ,Parmi euxisDefaultPour les étiquettes, Défaut de paiement en retard .
Données disponibles10000Échantillons,38 Caractéristiques primitives des dimensions ,Parmi euxisDefaultPour les étiquettes, Défaut de paiement en retard .

import pandas as pd
pd.set_option("display.max_columns",50)
train_bank = pd.read_csv('./train_public.csv')
print(train_bank.shape)
train_bank.head()Le prétraitement des données concerne principalement l'information sur la date 、 Traitement des données sur le bruit , Et les catégories suivantes 、 Caractéristiques du type numérique .
# Type de date:issueDate Convertir enpandasType de date dans, Traitement des caractéristiques numériques
train_bank['issue_date'] = pd.to_datetime(train_bank['issue_date'])
# Extraction de caractéristiques à plusieurs échelles
train_bank['issue_date_y'] = train_bank['issue_date'].dt.year
train_bank['issue_date_m'] = train_bank['issue_date'].dt.month
# Temps d'extractiondiff # Convertir en jours
base_time = datetime.datetime.strptime('2000-01-01', '%Y-%m-%d') # Définir au hasard l'heure de référence initiale
train_bank['issue_date_diff'] = train_bank['issue_date'].apply(lambda x: x-base_time).dt.days
# On peut le découvrir.earlies_credit_mon Ça devrait être l'année. - Format du mois , Voici un extrait simple de l'année
train_bank['earlies_credit_mon'] = train_bank['earlies_credit_mon'].map(lambda x:int(sorted(x.split('-'))[0]))
train_bank.head()
# Traitement des années de travail
train_bank['work_year'].fillna('10+ years', inplace=True)
work_year_map = {'10+ years': 10, '2 years': 2, '< 1 year': 0, '3 years': 3, '1 year': 1,
'5 years': 5, '4 years': 4, '6 years': 6, '8 years': 8, '7 years': 7, '9 years': 9}
train_bank['work_year'] = train_bank['work_year'].map(work_year_map)
train_bank['class'] = train_bank['class'].map({'A': 0, 'B': 1, 'C': 2, 'D': 3, 'E': 4, 'F': 5, 'G': 6})
# Traitement des valeurs manquantes
train_bank = train_bank.fillna('9999')
# Distinction Valeur numérique Ou caractéristiques de catégorie
drop_list = ['isDefault','earlies_credit_mon','loan_id','user_id','issue_date']
num_feas = []
cate_feas = []
for col in train_bank.columns:
if col not in drop_list:
try:
train_bank[col] = pd.to_numeric(train_bank[col]) # Convertir en valeur numérique
num_feas.append(col)
except:
train_bank[col] = train_bank[col].astype('category')
cate_feas.append(col)
print(cate_feas)
print(num_feas)Si ouiLightgbm Modélisation pour faire des prévisions par défaut ,Traitement simple des données, En gros, le Code est terminé. .lgb Le modèle arborescent est un modèle puissant d'apprentissage intégré , Absence d'autogreffe 、 Traitement des variables de catégorie , Il n'y a pas beaucoup de travail à faire sur les caractéristiques , La modélisation est très pratique , Les modèles fonctionnent généralement bien , Vous pouvez également exporter l'importance des caractéristiques .
(By the way, Application de la carte de pointage régression logique de l'industrie LRCe sera plus, Parce que le modèle est simple , C'est mieux expliqué aussi ).
def model_metrics(model, x, y):
""" Évaluation """
yhat = model.predict(x)
yprob = model.predict_proba(x)[:,1]
fpr,tpr,_ = roc_curve(y, yprob,pos_label=1)
metrics = {'AUC':auc(fpr, tpr),'KS':max(tpr-fpr),
'f1':f1_score(y,yhat),'P':precision_score(y,yhat),'R':recall_score(y,yhat)}
roc_auc = auc(fpr, tpr)
plt.plot(fpr, tpr, 'k--', label='ROC (area = {0:.2f})'.format(roc_auc), lw=2)
plt.xlim([-0.05, 1.05]) # Paramètresx、y Limites supérieure et inférieure de l'arbre , Pour ne pas coïncider avec les bords , Mieux observer l'ensemble de l'image
plt.ylim([-0.05, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate') # Peut utiliser le chinois, Mais vous devez importer certaines bibliothèques, c'est - à - dire des polices
plt.title('ROC Curve')
plt.legend(loc="lower right")
return metrics
# Diviser l'ensemble de données:Ensembles de formation et d'essais
train_x, test_x, train_y, test_y = train_test_split(train_bank[num_feas + cate_feas], train_bank.isDefault,test_size=0.3, random_state=0)
# Modèle d'entraînement
lgb=lightgbm.LGBMClassifier(n_estimators=5,leaves=5, class_weight= 'balanced',metric = 'AUC')
lgb.fit(train_x, train_y)
print('train ',model_metrics(lgb,train_x, train_y))
print('test ',model_metrics(lgb,test_x,test_y))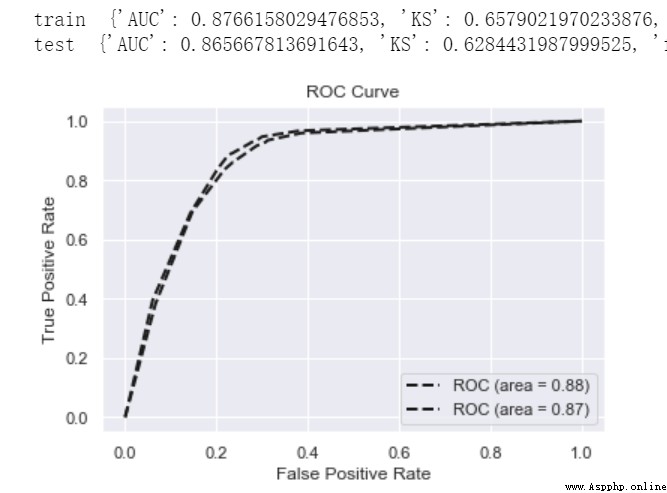
from lightgbm import plot_importance
plot_importance(lgb)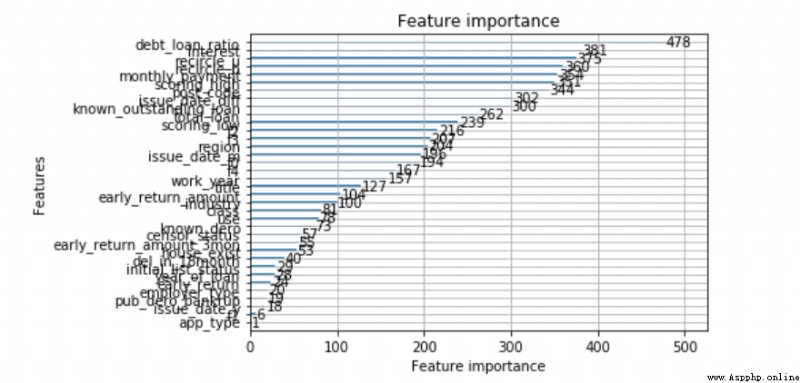
LRC'est - à - dire la régression logique, Est un modèle linéaire généralisé , Parce que son modèle est simple 、 Bonne explication , Est le plus souvent utilisé dans le secteur financier .
C'est aussi parce queLRC'est trop simple., Pas de capacité non linéaire , Par conséquent, nous avons souvent besoin d'une ingénierie plus complexe des caractéristiques , Comme dans le cas du compartiment WOEMéthode de codage, Amélioration de la capacité non linéaire du modèle .À propos deLR Principes et méthodes d'optimisation , La lecture suivante est fortement recommandée :
《Analyse complète et réalisation de la régression logique(Python)》
《 Résumé des techniques d'optimisation de la régression logique (Tous)》
On passe par là.toad Réalisation de l'analyse des caractéristiques 、Sélection des caractéristiques、 Caractéristiques WOECodage
# DonnéesEDAAnalyse
toad.detector.detect(train_bank)
# Sélection des caractéristiques, Selon la pertinence Taux de délétion、IV Indicateurs équivalents
train_selected, dropped = toad.selection.select(train_bank,target = 'isDefault', empty = 0.5, iv = 0.05, corr = 0.7, return_drop=True, exclude=['earlies_credit_mon','loan_id','user_id','issue_date'])
print(dropped)
print(train_selected.shape)
# Diviser l'ensemble d'entraînement Test Set
train_x, test_x, train_y, test_y = train_test_split(train_selected.drop(['loan_id','user_id','isDefault','issue_date','earlies_credit_mon'],axis=1), train_selected.isDefault,test_size=0.3, random_state=0)# Cartouche carrée caractéristique
combiner = toad.transform.Combiner()
# Données de formation et méthode de compartimentage spécifiée
combiner.fit(pd.concat([train_x,train_y], axis=1), y='isDefault',method= 'chi',min_samples = 0.05,exclude=[])
# Enregistrer les résultats en boîte dans un dictionnaire
bins = combiner.export()
bins Compartimentage des caractéristiques , Chaque caractéristique est discrète en sous - boîtes individuelles .
Et ensuite,LR Traitement des caractéristiques de l'ingénierie des caractéristiques -- Réglage manuel de la monotonie du compartiment .
L'importance de cette étape réside davantage dans les contraintes d'interprétation commerciale des caractéristiques. , L'effet sur l'ajustement du modèle n'est pas nécessairement positif . Ici, nous considérons subjectivement que la plupart des caractéristiques des différents taux de créances irrécouvrables de la boîte badrate Ça devrait satisfaire une relation monotone. , Et les hauts et les bas sont difficiles à comprendre . Comme le nombre de demandes de crédit , Plus la valeur de la boîte est élevée , Plus le taux de créances irrécouvrables est élevé .(Note:: Les caractéristiques de l'âge peuvent ne pas satisfaire à cette monotonie )
On peut voirebt_loan_ratio Le cas de Boxing de cette variable ,Selonbad_rateGraphique des tendances, Et s'assurer que la proportion d'échantillons d'un seul sous - ensemble n'est pas inférieure à 0.05, Pour régler le compartiment , Atteindre la monotonie .( D'autres caractéristiques peuvent être ajustées de cette façon , Le réglage de la monotonie prend du temps )
adj_var = 'scoring_low'
# Le compartiment d'origine avant le réglage [560.4545455, 621.8181818, 660.0, 690.9090909, 730.0, 775.0]
adj_bin = {adj_var: [ 660.0, 700.9090909, 730.0, 775.0]}
c2 = toad.transform.Combiner()
c2.set_rules(adj_bin)
data_ = pd.concat([train_x,train_y], axis=1)
data_['type'] = 'train'
temp_data = c2.transform(data_[[adj_var,'isDefault','type']], labels=True)
from toad.plot import badrate_plot, proportion_plot
# badrate_plot(temp_data, target = 'isDefault', x = 'type', by = adj_var)
# proportion_plot(temp_data[adj_var])
from toad.plot import bin_plot,badrate_plot
bin_plot(temp_data, target = 'isDefault',x=adj_var)Avant ajustement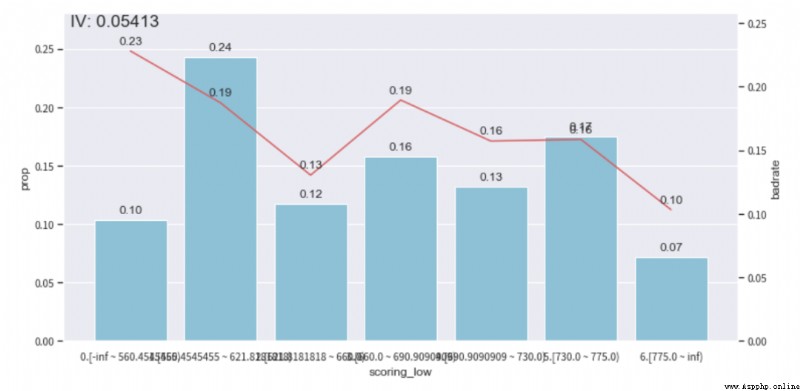
Après ajustement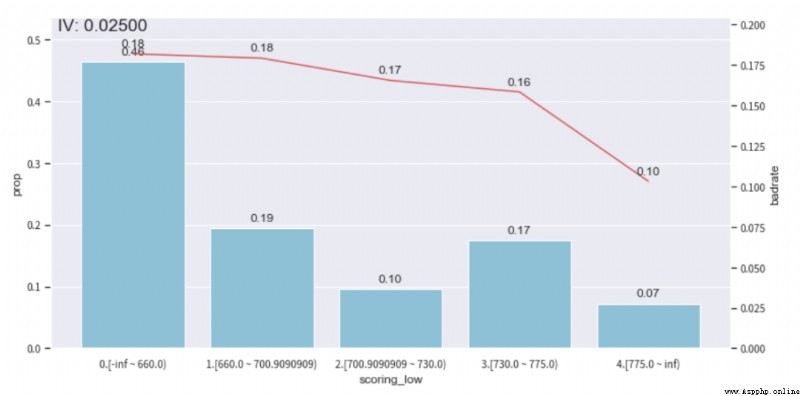
# Mise à jour du compartiment ajusté
combiner.set_rules(adj_bin)
combiner.export()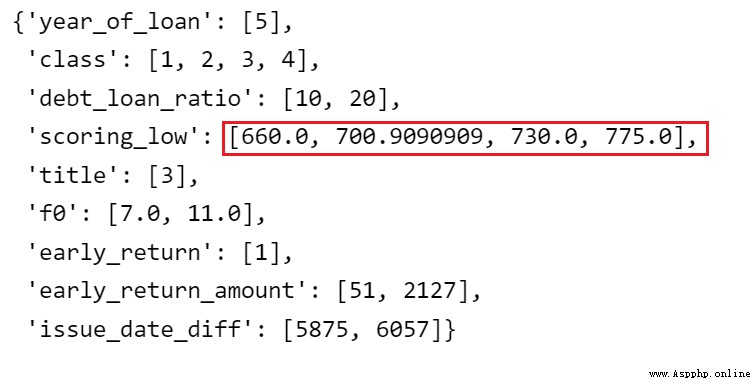
La prochaine étape consiste à faire des boîtes séparées pour chaque caractéristique WOECodage,AdoptionWOE Les poids sont codés pour chaque sous - boîte ,PromotionLR Non - linéarité du modèle .
#CalculWOE, Calculé uniquement sur l'ensemble d'entraînement WOE, Sinon, l'étiquette fuit
transer = toad.transform.WOETransformer()
binned_data = combiner.transform(pd.concat([train_x,train_y], axis=1))
#C'est exact.WOE Convertir la valeur de , Mapping to the original data set . Pour l'ensemble de formation fit_transform, Pour l'ensemble d'essai transform.
data_tr_woe = transer.fit_transform(binned_data, binned_data['isDefault'], exclude=['isDefault'])
data_tr_woe.head()
## test woe
# Diviser d'abord la boîte
binned_data = combiner.transform(test_x)
#C'est exact.WOE Convertir la valeur de , Mapping to the original data set . Pour l'ensemble d'essai transform.
data_test_woe = transer.transform(binned_data)
data_test_woe.head()UtiliserwoeCodétrainModèle de formation aux données. Pour un ensemble de données très déséquilibré comme le contrôle des risques financiers , L'approche la plus courante consiste à prélever des échantillons positifs dans quelques classes ou à utiliser un apprentissage sensible aux coûts. class_weight='balanced', Pour augmenter le poids d'apprentissage de quelques classes .Visible:《 Un article résout le déséquilibre de l'échantillon (Tous)》
PourLR Modèle isofaible , Les différences entre les mesures de l'ensemble de formation et de l'ensemble d'essai sont généralement observées. (gap)C'est moins, C'est - à - dire qu'il y a peu de surajustement .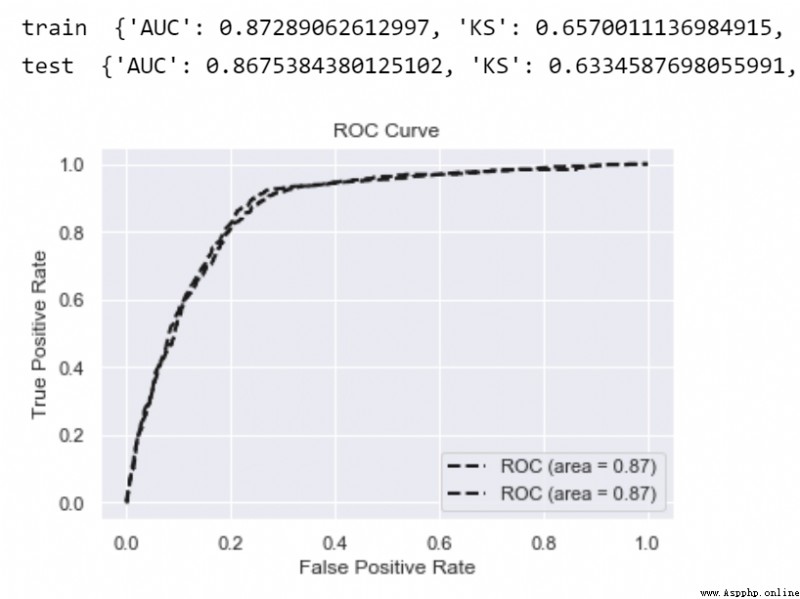
# FormationLRModèle
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression(class_weight='balanced')
lr.fit(data_tr_woe.drop(['isDefault'],axis=1), data_tr_woe['isDefault'])
print('train ',model_metrics(lr,data_tr_woe.drop(['isDefault'],axis=1), data_tr_woe['isDefault']))
print('test ',model_metrics(lr,data_test_woe,test_y))Utiliser la formationLRModèle,Produits(Probabilité) Tableau de distribution des scores , Taux combiné d'homicide involontaire 、 Le taux de rappel et les besoins opérationnels déterminent un seuil de notation approprié. cutoff (Note::Dans le scénario réel, Il convertit également la probabilité non linéaire en une fraction entière plus intuitive score=A-B*ln(odds), La carte de pointage pratique est plus intuitive 、 Application uniforme .)
train_prob = lr.predict_proba(data_tr_woe.drop(['isDefault'],axis=1))[:,1]
test_prob = lr.predict_proba(data_test_woe)[:,1]
# Group the predicted scores in bins with same number of samples in each (i.e. "quantile" binning)
toad.metrics.KS_bucket(train_prob, data_tr_woe['isDefault'], bucket=10, method = 'quantile') Lorsque la probabilité de prédire cet utilisateur est supérieure au seuil fixé , Cela signifie que la probabilité de défaut de cet utilisateur est élevée , Pour refuser sa demande de prêt .
Un excellent examen du passé
Itinéraire et téléchargement de données pour les débutants(Graphique et texte+Vidéo)Télécharger la série d'introduction à l'apprentissage automatique《Apprentissage automatique》(Discours de Huang haiguang)Impression de documents tels que les notes d'apprentissage en machine et en profondeur《Méthodes d'apprentissage statistique》Code Recovery album Machine Learning ExchangeqqGroupe955171419,Veuillez scanner le Code pour rejoindre le Groupe Wechat
 Graduation design based on python+vue+elementui+django freshman enrollment management system (separation of front and back ends)
Graduation design based on python+vue+elementui+django freshman enrollment management system (separation of front and back ends)
The content of this graduation
 Python之Request庫的安裝、安裝卻無法import、“You should consider upgrading via the ‘python -m pip.....“
Python之Request庫的安裝、安裝卻無法import、“You should consider upgrading via the ‘python -m pip.....“
Python之Request庫的安裝、安裝卻無法import