摘要:本文介紹了循環碼和卷積碼兩種編碼方式,並且,作者給出了兩種編碼方式的編碼譯碼的python實現
關鍵字:循環碼,系統編碼,卷積碼,python,Viterbi算法
設 \(C\) 是一個 \(q\) 元 \([n,n-r]\) 循環碼,其生成多項式為\(g(x), \text{deg}(g(x))=r\)。顯然,\(C\) 有 \(n-r\) 個信息位,\(r\) 個校驗位。我們用 \(C\) 對信息源 \(V(n-r,q)\) 中的向量進行表示。
對任意信息源向量 \(a_0a_1\cdots a_{n-r-1}\in V(n-r,q)\),循環碼有兩種編碼思路:
構造信息多項式
\[a(x) = a_0+a_1x+\cdots+a_{n-r-1}x^{n-r-1}該信息源的多項式對應於循環碼 \(C\) 的一個碼字
\[c(x)=a(x)g(x)構造信息多項式
\[\bar{a}(x)=a_0x^{n-1}+a_1x^{n-2}+\cdots+a_{n-r-1}x^r顯然當 \(a_0,a_1,\cdots,a_{n-r-1}\) 不全為零時。\(r\lt\text{deg}(\bar{a}(x))=n-1\)。用 \(g(x)\) 去除 \(\bar{a}(x)\),得到
\[\bar{a}(x)=q(x)g(x)+r(x)其中 \(\text{deg}(r(x))\lt\text{deg}(g(x))=r\),信息源多項式被編碼為C中的碼字
\[c(x)=q(x)g(x)+r(x)=\bar{a}(x)-r(x)可以看到,\(\bar{a}(x)\) 和 \(r(x)\) ,沒有相同的項,所以這種編碼方式為系統編碼。也即,如果將 \(c(x)\) 中的 \(x\) 的項按生降次排序,則碼字前 \(n-r\) 位就是信息位,後 \(r\) 位是校驗位。
已知 \(C\) 是一個二元 \((7,4)\) 循環碼,生成多項式為 \(g(x)=x^3+x+1\)。
\(0101\in V(4,2)\) 是代編碼的信息向量
也即,\(0101\in V(4,2)\) 被編碼為\(0111001\in V(7,2)\)
也就是,\(0101\in V(4,2)\) 被編碼為\(0101100\in V(7,2)\)
一般而言,系統碼解碼速度相比非系統編碼更快。接下來我們對上述例子進一步探索。
考慮 \(F_2[x]/\langle x^7-1\rangle\) 中階數大於3的基。
\[f_1(x)=x^6=(x^3+x+1)(x^3+x+1)+x^2+1也即,\(1000\in V(4,2)\) 被編碼為\(1000101\in V(7,2)\)。
\[f_2(x)=x^5=(x^2+1)(x^3+x+1)+x^2+x+1也即,\(0100\in V(4,2)\) 被編碼為\(0100111\in V(7,2)\)。
\[f_3(x)=x^4=x(x^3+x+1)+x^2+x也即,\(0010\in V(4,2)\) 被編碼為\(0010110\in V(7,2)\)。
\[f_4(X)=x^3=(x^3+x+1)+x+1也即,\(0001\in V(4,2)\) 被編碼為\(0001011\in V(7,2)\)。
所以生成多項式為 \(g(x)=x^3+x+1\) 的 \((7,4)\) 循環碼C的生成矩陣為
\[G=首先我們不加證明的引入循環矩陣的校驗多項式核校驗矩陣的知識。
定義 設 \(C\subset R_n\) 是一個 \(q\) 元 \([n,n-r]\) 循環碼,其生成多項式為 \(g(x)\),校驗多項式定義為
\[h(x)\triangleq(x^n-1)/g(x)定理 設 \(C\subset R_n\) 是一個 \(q\) 元 \([n,n-r]\) 循環碼,其生成多項式為 \(g(x)\),校驗多項式為 \(h(x)\),則對任意 \(c(x)\in R_n(x)\),\(c(x)\) 是 \(C\) 的一個碼字當且僅當 \(c(x)h(x)=0\)。
定理 設\(C\subset R_n\) 是一個 \(q\) 元 \([n,n-r]\) 循環碼,其生成多項式為 \(g(x)\),校驗多項式記為
\[h(x)=(x^n-1)/g(x)\triangleq h_{n-r}x^{n-r}+\cdots+h_1x+h_0且其校驗矩陣為
\[H=所以可得,對於已知 \(C\) 是一個二元 \((7,4)\) 循環碼,生成多項式為 \(g(x)=x^3+x+1\),校驗多項式為 \(h(x)=x^4+x^3+x^2+1\),校驗矩陣為
\[H=因為是系統編碼,所以,如果將 \(c(x)\) 中的 \(x\) 的項按降冪次排序,則碼字前 \(n-r\) 位就是信息位,後 \(r\) 位是校驗位。也就是,如果不出錯,則接受的的碼字的前 4 個''字母''(信息比特)就是對方傳輸的信息。
但是考慮到一般情形,二元循環碼解碼流程如下
對於上述碼字,若接收到 \(y=0110010\),\(S(y)=yH^T=011=1*H_4\),所以發送碼字為 \(0111010\),也即代表信息源 \(0111\)。
對於上述循環碼,python程序實現如下
# (7,4)二元循環碼
# 生成多項式 g(x)= x^3+x+1
import numpy as np
# 生成矩陣
G = np.array([
[1,0,0,0,1,0,1],
[0,1,0,0,1,1,1],
[0,0,1,0,1,1,0],
[0,0,0,1,0,1,1]
])
# 校驗矩陣
H = np.array([
[1,1,1,0,1,0,0],
[0,1,1,1,0,1,0],
[0,0,1,1,1,0,1]
])
# 編碼
def encode_cyclic(x):
if not len(x) == 4:
print("請輸入4位信息比特")
return
y = np.dot(x,G)
print(x,"編碼為:",y)
return y
# 譯碼,過程與漢明碼一致
def decode_cyclic(y):
if not len(y) == 7:
print("請輸入7位信息比特")
return
x_tmp = np.dot(y,H.T)%2
if (x_tmp!=0).any():
for i in range(H.shape[1]):
if (x_tmp==H[:,i]).all():
y[i] = (y[i]-1)%2
break
x = y[0:4]
print(y,"解碼為:",x)
return x
# 測試
if __name__ == '__main__':
y = [1,0,0,0,1,0,1]
decode_cyclic(y)
x=[1,0,0,0]
encode_cyclic(x)
卷積碼是信道編碼技術的一種,屬於一種糾錯碼。最早由1955年Elias最早提出,目的是為了減少在信源消息在信道傳輸過程中產生的差錯,增加接收端譯碼的准確性。
卷積碼的生成方式是將待傳輸的信息序列通過線性有限狀態移位寄存器,也就是在卷積碼的編碼過程中,需要輸入消息源與編碼器中的沖激響應做卷積。具體說來,在任意時段,編碼器的 \(n\) 個輸出不僅與此時段的 \(k\) 個輸入有關,還與寄存器中前 \(m\) 個輸入有關。卷積碼的糾錯能力隨著 \(m\) 的增加而增大,同時差錯率隨著 \(m\) 的增加而成指數下降。
參數 \((n,k,m)\) 解釋如下:
由此看來,卷積碼編碼的結果與之前的輸入有關,編碼具有記憶性,是非分組碼。而分組碼的編碼只於當前輸入有關,編碼不具有記憶性。
1967年Viterbi提出基於動態規劃的最大似然Viterbi譯碼法。
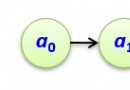
如下圖為:(2,1,2)卷積碼的編碼示意圖
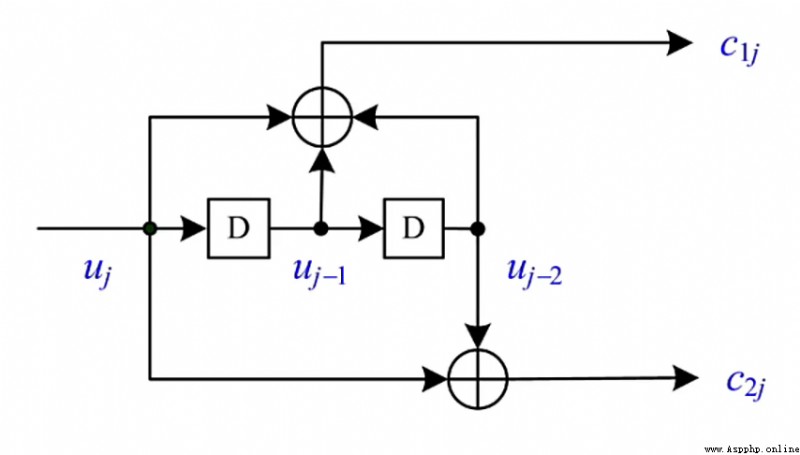
其中,\(j\) 表示時序,
\[\begin{aligned}為了後續說明卷積碼中重要的“狀態”概念,現引入記號(僅以2個輸出為例,\(n\) 個輸出可以此類推):
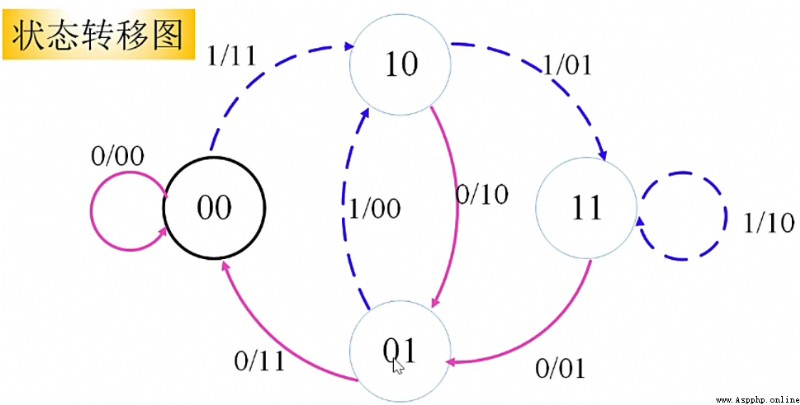
所以不難看出(2,1,2)卷積碼由 4 種可能的狀態,為 \((00),(01),(10),(11)\)。
對於狀態我們有如下引理
引理
給定出發狀態 \(s_{j-1}\) 和當前的輸入 \(u_j\),可以確定出到達狀態 \(s_j\) 以及當前輸出 \(c_{1_j}c_{2j}\)
給定狀態的變化序列 \(s_0s_1s_2\cdots\),將能確定出輸入序列 \(u_0u_1u_2\cdots\) 以及輸出序列\(c_{10}c{20}c_{11}c_{21}\cdots\)
注:我們默認初始狀態\(s_{-1}=0\)
從上述描述中,不難看出,卷積碼的全部信息都包含在狀態變化序列中。
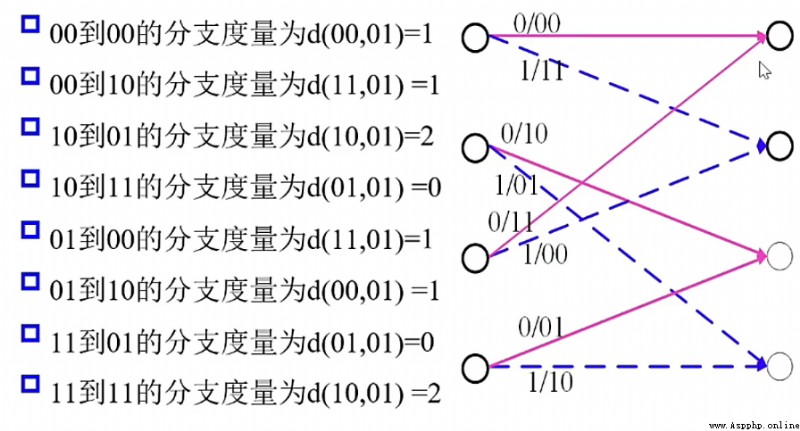
下圖為“格圖”,

格圖結構更加緊湊,代表著時間的移動,也即,信息比特在不斷輸入。
從上圖中,我們可得出,若輸入序列是 \(10110\),則輸出序列為 \(11 10 00 01 01\)。
代碼示例如下
# (2,1,2)卷積碼
# 卷積編碼
def encode_conv(x):
# 存儲編碼信息
y = []
# 兩個寄存器u_1 u_2初始化為0
u_2 = 0
u_1 = 0
for j in x:
c_1 = (j + u_1 + u_2)%2
c_2 = (j+u_2)%2
y.append(c_1)
y.append(c_2)
# 更新寄存器
u_2 = u_1
u_1 = j
print(x,"編碼為:",y)
return y
# 測試代碼
if __name__ == '__main__':
encode_conv([1,0,1,1,0])
我們注意到
設 \(j\) 時刻接受的比特是 \(y_{1j}y_{2j}\)
例如從第 \(i\) 步到第 \((i+1)\) 步接收的比特位 \(01\)
如下為輸入比特:01 11 01 的格圖。
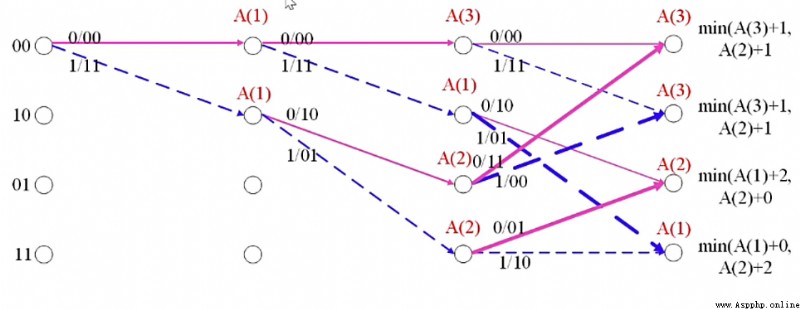
其中 \(A(i)\) 表示從開始時刻到當前時刻的累積度量為 \(i\)
對於接收序列為:01 11 01 11 00
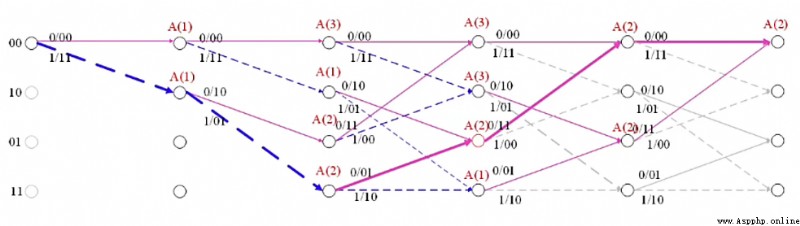
通過上述路徑分析圖可得,經過最大似然譯碼分析後,譯碼序列為:11000
Viterbi譯碼python實現如下:
def decode_conv(y):
# shape = (4,len(y)/2)
# 初始化
score_list = np.array([[ float('inf') for i in range(int(len(y)/2)+1)] for i in range(4)])
for i in range(4):
score_list[i][0]=0
# 記錄回溯路徑
trace_back_list = []
# 每個階段的回溯塊
trace_block = []
# 4種狀態 0-3分別對應['00','01','10','11']
states = ['00','01','10','11']
# 根據不同 狀態 和 輸入 編碼信息
def encode_with_state(x,state):
# 編碼後的輸出
y = []
u_1 = 0 if state<=1 else 1
u_2 = state%2
c_1 = (x + u_1 + u_2)%2
c_2 = (x + u_2)%2
y.append(c_1)
y.append(c_2)
return y
# 計算漢明距離
def hamming_dist(y1,y2):
dist = (y1[0]-y2[0])%2 + (y1[1]-y2[1])%2
return dist
# 根據當前狀態now_state和輸入信息比特input,算出下一個狀態
def state_transfer(input,now_state):
u_1 = int(states[now_state][0])
next_state = f'{input}{u_1}'
return states.index(next_state)
# 根據不同初始時刻更新參數
# 也即指定狀態為 state 時的參數更新
# y_block 為 y 的一部分, shape=(2,)
# pre_state 表示當前要處理的狀態
# index 指定需要處理的時刻
def update_with_state(y_block,pre_state,index):
# 輸入的是 0
encode_0 = encode_with_state(0,pre_state)
next_state_0 = state_transfer(0,pre_state)
score_0 = hamming_dist(y_block,encode_0)
# 輸入為0,且需要更新
if score_list[pre_state][index]+score_0<score_list[next_state_0][index+1]:
score_list[next_state_0][index+1] = score_list[pre_state][index]+score_0
trace_block[next_state_0][0] = pre_state
trace_block[next_state_0][1] = 0
# 輸入的是 1
encode_1 = encode_with_state(1,pre_state)
next_state_1 = state_transfer(1,pre_state)
score_1 = hamming_dist(y_block,encode_1)
# 輸入為1,且需要更新
if score_list[pre_state][index]+score_1<score_list[next_state_1][index+1]:
score_list[next_state_1][index+1] = score_list[pre_state][index]+score_1
trace_block[next_state_1][0] = pre_state
trace_block[next_state_1][1] = 1
if pre_state==3 or index ==0:
trace_back_list.append(trace_block)
# 默認寄存器初始為 00。也即,開始時刻,默認狀態為00
# 開始第一個 y_block 的更新
y_block = y[0:2]
trace_block = [[-1,-1] for i in range(4)]
update_with_state(y_block=y_block,pre_state=0,index=0)
# 開始之後的 y_block 更新
for index in range(2,int(len(y)),2):
y_block = y[index:index+2]
for state in range(len(states)):
if state == 0:
trace_block = [[-1,-1] for i in range(4)]
update_with_state(y_block=y_block,pre_state=state,index=int(index/2))
# 完成前向過程,開始回溯
# state_trace_index 表示 開始回溯的狀態是啥
state_trace_index = np.argmin(score_list[:,-1])
# 記錄原編碼信息
x = []
for trace in range(len(trace_back_list)-1,-1,-1):
x.append(trace_back_list[trace][state_trace_index][1])
state_trace_index = trace_back_list[trace][state_trace_index][0]
x = list(reversed(x))
print(y,"解碼為:",x)
return x
# 測試代碼
if __name__ == '__main__':
# 對應 1 1 0 0 0
decode_conv([0,1,1,1,0,1,1,1,0,0])
參考
(7,3)循環碼編碼譯碼 C實現
卷積編碼及維特比譯碼 - mdnice 墨滴
有噪信道編碼—線性分組碼_哔哩哔哩_bilibili
一.背景 最近在Azkaban的測試工作中,需要在測試環境下模擬線上的調度場景進行穩定性測試.故而重操python舊業,通過python編寫腳本來構造類似線上的調度場景.在腳本編寫過程中,碰到這樣一個 ...
Python的字符串格式化有兩種方式: 百分號方式.format方式 百分號的方式相對來說比較老,而format方式則是比較先進的方式,企圖替換古老的方式,目前兩者並存.[PEP-3101] This ...
python提供了一些有趣且實用的函數,如any all zip,這些函數能夠大幅簡化我們得代碼,可以更優雅的處理可迭代的對象,同時使用的時候也得注意一些情況 any any(iterable) ...
軟件開發是現時很火的職業.據美國勞動局發布的一項統計數據顯示,從2014年至2024年,美國就業市場對開發人員的需求量將增長17%,而這個增長率比起所有職業的平均需求量高出了7%.很多人年輕人會選擇編 ...
title: 可愛的豆子--使用Beans思想讓Python代碼更易維護 toc: false comments: true date: 2016-06-19 21:43:33 tags: [Pyth ...
起因 在極客學院講授<使用Python編寫遠程控制程序>的課程中,涉及到查看被控制電腦屏幕截圖的功能. 如果使用PIL,這個需求只需要三行代碼: from PIL import Image ...
字節流和字符串 當使用Python定義一個字符串時,實際會存儲一個字節串: "abc"--[97][98][99] python2.x默認會把所有的字符串當做ASCII碼來對待,但 ...
由於經常需要到服務器上執行些命令,有些命令懶得敲,就准備寫點腳本直接浏覽器調用就好了,比如這樣: 因為線上有現成的Apache,就直接放它裡面了,當然訪問安全要設置,我似乎別的隨筆裡寫了安全問題,這裡 ...
引言 最近剛剛用python寫完了一個解析protobuf文件的簡單編譯器,深感ply實現詞法分析和語法分析的簡潔方便.乘著余熱未過,頭腦清醒,記下一點總結和心得,方便各位pythoner參考使用. ...
工作後好久沒上博客園了,雖然不是很忙,但也沒學生時代閒了.今天上博客園,發現好多的文章都是年終總結,想想是不是自己也應該總結下,不過現在還沒想好,等想好了再寫吧.今天寫寫自己在工作後用到的技術干貨,爭 ...
近期,經常有人問 JMeter 3.0 使用時,生成的 HTML 報告圖表中的中文亂碼問題.在此,簡略的說一下解決的方法. 編碼相關信息如下: 1.查看控制 csv.xml 等配置結果文件生成.讀取的 ...
1.添加用戶 useradd 選項 用戶名 其中各選項含義如下: -c comment 指定一段注釋性描述.-d 目錄 指定用戶主目錄,如果此目錄不存在,則同時使用-m選項,可以創建主目錄.-g ...
在這學習stm32半年的時間中,雖然明顯的感覺到自己在進步,但是還是發現學習方法的錯誤.由於急功近利的性格,在學習stm32之初,我選擇了最簡單的辦法,用庫函數來寫程序,而且也由於我這急功近利的性格, ...
串口進行操作的類,其中包括寫和讀操作,類可設置串口參數.設置接收函數.打開串口資源.關閉串口資源,操作完成後,一定要關閉串口.接收串口數據事件.接收數據出錯事件.獲取當前全部串口.把字節型轉換成十六進 ...
bool為布爾型,只有一個字節,取值false和true #include<iostream>using namespace std;int main(){ int year; bool ...
原文http://www.cnblogs.com/TianFang/archive/2012/10/12/2721883.html 最近寫了一個下載程序,發現有一個問題:掛機下載的時候,下載任務會因為 ...
buffer是node裡的一個模塊,這個模塊的出現是因為js沒有閱讀和操作二進制數據流而出現的 buffer是什麼及作用? Buffer顧名思義叫緩沖區,用於存儲速度不同步的設備或優先級不同的設備之間 ...
通過這些狀態類可以為行或單元格設置顏色. .active---鼠標懸停在行或單元格上時所設置的顏色 .success--–標識成功或積極的動作 .info----標識普通的提示信息或動作 .warni ...
RabbitMQ隊列 RabbitMQ是一個在AMQP基礎上完整的,可復用的企業消息系統.他遵循Mozilla Public License開源協議. MQ全稱為Message Queue, 消息隊列 ...
訂單超賣問題是涉及到庫存項目的重中之重,這裡我總結一下常用的方法 1.簡單處理[update & select 合並](樂觀鎖) beginTranse(開啟事務)$num = 1; try{ ...