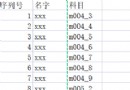
python字典的底層實現的是哈希表。調用python內置的哈希函數,將鍵(key)作為參數進行轉換(哈希運算+取余運算),得到一個唯一的地址(地址的索引),然後將值(value)存放到對應的地址中(給相同的鍵賦值會直接覆蓋原值,因為相同的鍵轉換後的地址時一樣的)
哈希表(Hash Table,又稱為散列表)是一種線性表的存儲結構。由一個直接尋址表 T (假設大小為m) 和一個哈希函數 h(k) 組成。對於任意可哈希對象,通過哈希函數(一般先進行哈希計算,然後對結果進行取余運算),將該對象映射為尋址表的索引 [0,1,2,…m-1],然後在該索引所對應的空間 T[0,1,2,…,m-1] 進行變量的存儲/讀取等操作。如下圖所示。
用順序表存儲數據
存儲鍵值對時,通過哈希函數計算出鍵對應的索引,將值存到索引對應的數據區中
獲取數據時,通過哈希函數計算出鍵對應的索引,將該索引對應的數據取出來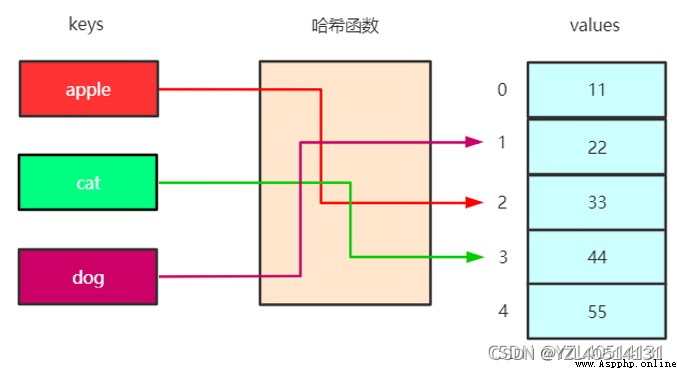
注:鍵(Key)必須是可哈希的,即,通過哈希函數可為此鍵計算出唯一地址。
對於 Python 來說,變量,列表、字典、集合這些都是可變的,所以都不能做為鍵(Key)來使用。因為元組裡邊可以存放列表這類可變元素,所以如果實在想拿元組當字典的鍵(Key),那必須對元組做限制:元組中只包括像數字和字符串這樣的不可變元素時,才可以作為字典中有效的鍵(Key)。另外還需要注意的一點是,Python 的哈希算法對相同的值計算得到的結果是一樣的,也就是說 12315 和 12315.0 的值相同,他們被認為是相同的鍵(Key)。
插入: 對鍵進行哈希和取余運算,得到一個哈希表的索引,如果該索引所對應的表地址空間為空,將鍵值對存入該地址空間;
查詢/更新: 對鍵進行哈希和取余運算,得到一個哈希表的索引,如果該索引所對應的地址空間中健與要查詢/更新的健一致,那麼就將該鍵值對取出來 / 更新該鍵所對應的值;
擴容: 字典初始化的時候,會對應初始化一個有k個空間的表,等空間不夠用的時候,系統就會自動擴容,這時候會對已經存在的鍵值對 重新進行哈希取余運算(重新進行插入操作)保存到其它位置;
對於任何哈希函數,都會出現兩個不同的元素映射到同一個位置上的情況,這種情況稱為哈希沖突
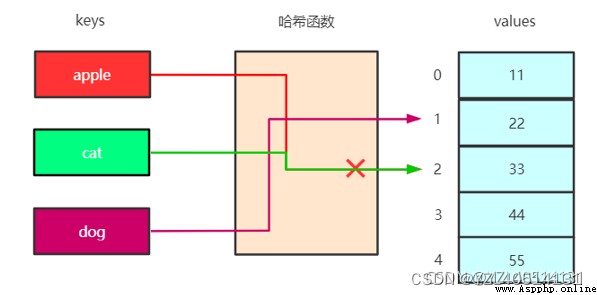
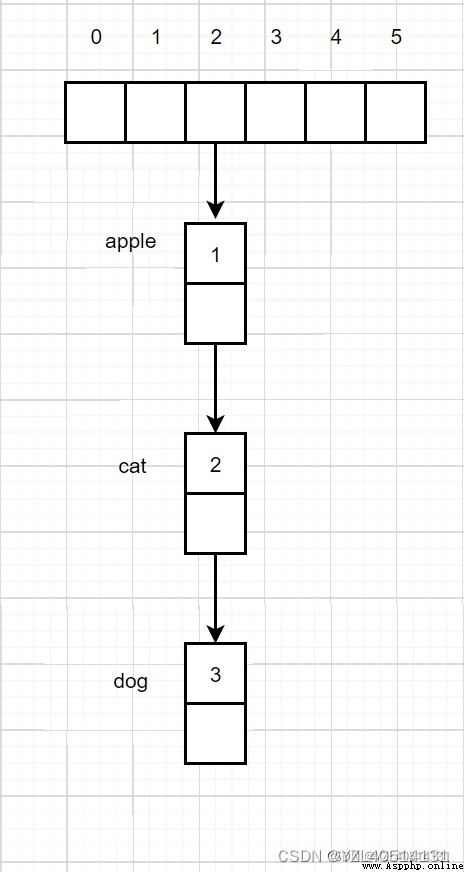
哈希表的每一個位置都連接一個鏈表,當發生沖突時,沖突的元素會被加到該位置的鏈表的最後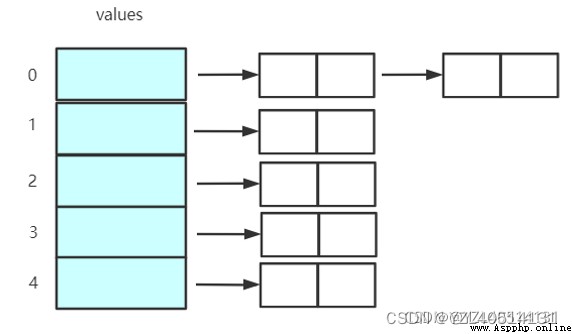
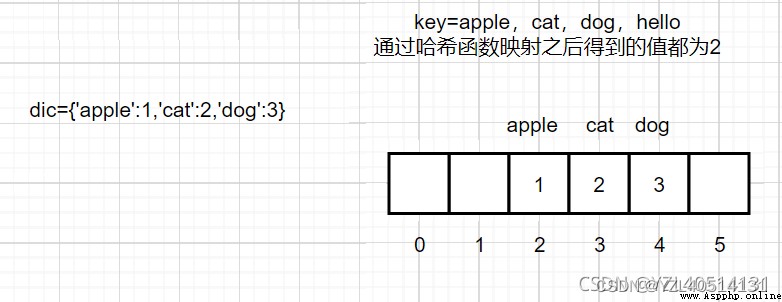
如果哈希函數得到的位置i已經有數據了,那麼就往後探查新的位置來存儲這個值
線性探測:如果i有數據了,則探測i+1,i+2…以此類推,直到找到空的位置
a、key=apple,cat,dog,hello,通過哈希函數映射之後得到的值都為2
b、現有一個字典dic={‘apple’:1,‘cat’:2,‘dog’:3},存儲數據,
c、原索引為2的位置沒有存儲數據,此時將apple的值1存儲到這個
d、接著cat尋址到索引為2的位置,發現這個位置已經有值了,會繼續往後探測,依次類推
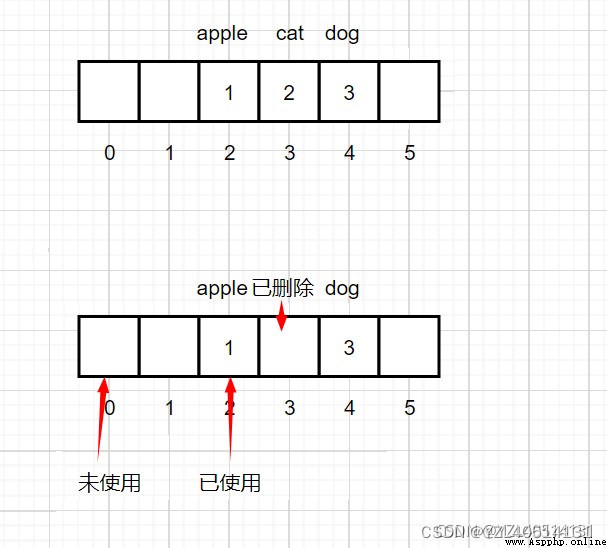
a、獲取dic[‘dog’]的時候,先到索引為2的位置去獲取
b、獲取不到繼續向後探測
dic.remove(‘cat’)
a、給每一個節點定義一個狀態
未使用
已使用
已刪除
開鏈法:
優點:刪除節點比較容易,數據量比較大使用開鏈法
缺點:使用空間比較大
開放尋址法:
刪除節點不能真正的把節點刪掉,給每一個節點定義一個狀態,數據量比較小使用開放尋址法
缺點:
a、使用開放尋址法,那麼順序表總歸會有一天會填滿
b、一般為了保證插入和查找的效率,哈希表一般在元素數量在容量的2/3時,就會進行擴容
c、擴容之後,計算的哈希函數也會隨之變化,那麼裡面的數據存儲的順序也會變化

 A few hand training items that beginners must see to learn Python are easy but not boring
A few hand training items that beginners must see to learn Python are easy but not boring
Python Its an object-oriented
 The python remote control server Python installation requirements Txt (super simple)
The python remote control server Python installation requirements Txt (super simple)
Reference resources : Referenc