Python What is character encoding and decoding
stay Python3 The default encoding of Chinese characters is Unicode character , Encoding refers to converting characters into byte streams , Decoding is the opposite operation .
Before the official start , We also need to sort out some basic concepts
Python String in
In the computer 8 The bit (bit) Equal to one byte (byte),8 It's bits 8 position , That is, the largest integer a byte can represent is 255(1111 1111).
If you want to expand the integer range , Need more bytes , for example 2 One byte can represent 65535,4 It can be represented by one byte 4294967295.
Based on the above principles, various coding formats have emerged , for example
ASCII Can be said 256 Characters , But only English letters are supported , Numbers and a few symbols , The scope of Chinese is much larger , So it's here GB2312 code ( Later upgraded to GBK code ), It can hold 6763 The Chinese characters , But looking at the world is not enough , More characters are needed .
here Unicode The character set appears , It holds all languages together , In order to save space when storing and transmitting data , There is UTF8 code .
How to use it?
Python Basic use of coding
adopt
ord() Function to get the integer representation of a character , adopt
chr() Convert integers to characters , For example, the following code
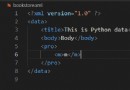
print(ord(' climb ')) # 29228
print(chr(29228))
Now that you know that numbers can be converted into numbers , Both decimal and hexadecimal numbers are OK .
for example
29228 =
722c, therefore
\u722cprint(chr(int('722c', 16)))
You can also use Unicode Transcoding tool for conversion .

Python Encoding and decoding functions
encode() and
decode() Corresponding to encoding and decoding functions respectively ,
en Is the code ,
de It's decoding .
my_b = ' The skill tree '.encode('utf-8')
print(' After the coding ',my_b) # After the coding b'\xe6\x8a\x80\xe8\x83\xbd\xe6\xa0\x91'
The decoding operation is as follows :
my_b = ' The skill tree '.encode('utf-8')
print(' After the coding ', my_b) # After the coding b'\xe6\x8a\x80\xe8\x83\xbd\xe6\xa0\x91'
my_str = my_b.decode('utf-8')
print(" After decoding ", my_str)
Note that the output after encoding is similar to the string , It is preceded by a prefix b. The statement
If the encoding and decoding methods are inconsistent , There will be a mess , For example, the following code
my_b = ' The skill tree '.encode('gbk')
print(' After the coding ', my_b) # After the coding b'\xbc\xbc\xc4\xdc\xca\xf7'
my_str = my_b.decode('utf-8')
print(" After decoding ", my_str)
The error message is as follows :
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xbc in position 0: invalid start byte
When the above types of errors occur , What needs to be done is to find the correct original code , And then deal with it .