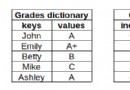
install Scrapy:pip install scrapy -i https://mirrors.aliyun.com/pypi/simple/ ( Followed by -i https://mirrors.aliyun.com/pypi/simple/ Domestic resources will improve the download speed )
open Cmd / PyCharm–Terminal
Enter the path where you want to create the crawler project , Input :scrapy startproject Project name ( Create a crawler project )
(1) Set up ROBOTSTXT_OBEY = Falserobots Explanation of the agreement :https://blog.csdn.net/wz947324/article/details/80633668( Some websites don't allow crawlers to visit , If the robot agreement is observed , Cannot crawl )(2) Turn on DOWNLOAD_DELAY = 3 Download delay :DOWNLOAD_DELAY = 3, Access to the server has passed 3s Ask for more data , Used to simulate user access (3) Turn on :DEFAULT_REQUEST_HEADERS = { ‘Accept’: ‘text/html,application/xhtml+xml,application/xml;q=0.9,/;q=0.8’,‘Accept-Language’: ‘en’,} You can set the default request header here , Delete the original content Set up :User-Agent:------ Set up :Cookie:------(4) Turn on :DOWNLOADER_MIDDLEWARES = { ‘zhaobiao( Project name ).middlewares.ZhaobiaoDownloaderMiddleware’: 543,} Download Middleware : Configure agent IP(5) Turn on :ITEM_PIPELINES = { ‘zhaobiao( Project name ).pipelines.ZhaobiaoPipeline’: 300,} Pipeline files : Point to pipelines.py file (6)scrapy Operation of the project Method 1: Create a start file :from scrapy import cmdline cmdline.execute('scrapy crawl bilian( Crawler file name ).split() Method 2:Terminal:cmdline.execute(‘scrapy crawl bilian( Crawler file name )’.split())