Data preparation
import pandas as pd
df = pd.DataFrame([['ABC','Good',1],
['FJZ',None,2],
['FOC','Good',None]
],columns=['Site','Remark','Quantity'])
df
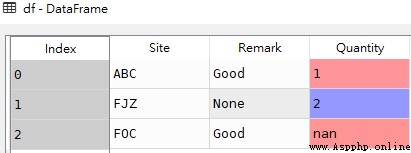
Be careful : Above Remark The data type in the field is string str type , The null value is 'None',Quantity The data type in the field is numeric , The null value is nan
1. Filter data rows with null values in a specified single column
# grammar
df[pd.isnull(df[col])]
df[df[col].isnull()] # obtain Remark Field is None The line of
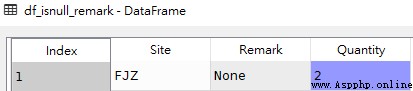
df_isnull_remark = df[df['Remark'].isnull()]
# obtain Quantity Field is None The line of
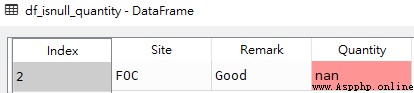
df_isnull_quantity = df[df['Quantity'].isnull()]df_isnull_remark
df_isnull_quantity
Tips
Filter the data row without null value in the specified single column
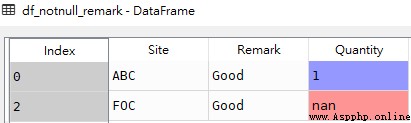
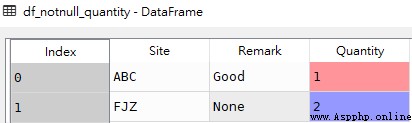
# grammar df[pd.notnull(df[col])] df[df[col].notnull()]# obtain Remark The field is non None The line of df_notnull_remark = df[df['Remark'].notnull()] # obtain Quantity The field is non None The line of df_notnull_quantity = df[df['Quantity'].notnull()]df_notnull_remark
df_notnull_quantity
2. Filter specified columns / Data rows in all columns that meet the requirement that all columns have null values
# grammar
df[df[[cols]].isnull().all(axis=1)]
df[pd.isnull(df[[cols]]).all(axis=1)]stay df Add a line to generate df1
df1 = pd.DataFrame([['ABC','Good',1],
['FJZ',None,2],
['FOC','Good',None],
[None,None,None]
],columns=['Site','Remark','Quantity'])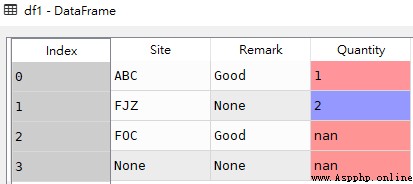
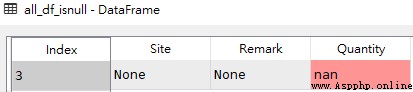
# obtain df1 All data rows with null values in columns
all_df_isnull = df1[df1[['Site','Remark','Quantity']].isnull().all(axis=1)]all_df_isnull
Tips
Filter specified columns / Data rows in all columns that meet the requirement that all columns have no null values
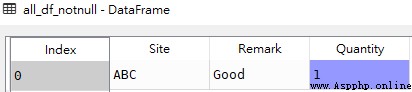
# grammar df[df[[cols]].notnull().all(axis=1)] df[pd.notnull(df[[cols]]).all(axis=1)]# obtain df1 Data rows with no null values in all columns all_df_notnull = df1[df1[['Site','Remark','Quantity']].notnull().all(axis=1)]all_df_notnull
3. Filter specified columns / Data rows in all columns that satisfy the null value of any column
# grammar
df[df[[cols]].isnull().any(axis=1)]
df[pd.isnull(df[[cols]]).any(axis=1)]df1( data source )
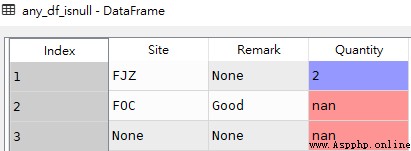
# obtain df1 Data rows in all columns that meet the requirement that any column has a null value
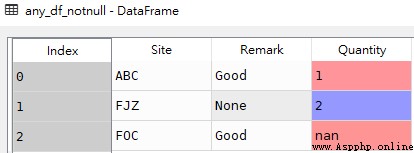
any_df_isnull = df1[df1[['Site','Remark','Quantity']].isnull().any(axis=1)] any_df_isnull
Tips
Filter specified columns / Data rows in all columns that satisfy that any column has no null value
# grammar df[df[[cols]].notnull().any(axis=1)] df[pd.notnull(df[[cols]]).any(axis=1)]# obtain df1 Data rows in all columns that satisfy that any column has no null value any_df_notnull = df1[df1[['Site','Remark','Quantity']].notnull().any(axis=1)]any_df_notnull
Numpy Look inside NaN If it's worth it , Use np.isnan()
Pabdas Look inside NaN If it's worth it , Use .isna() or .isnull()
import pandas as pd
import numpy as np
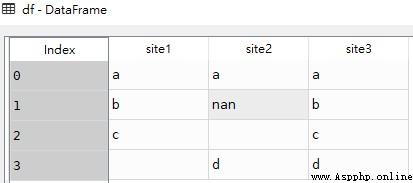
df = pd.DataFrame({'site1': ['a', 'b', 'c', ''],
'site2': ['a', np.nan, '', 'd'],
'site3': ['a', 'b', 'c', 'd']})df
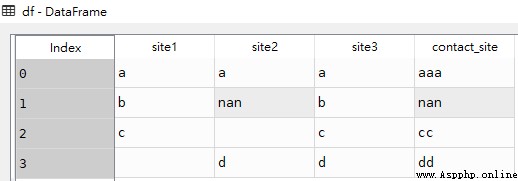
df['contact_site'] = df['site1'] + df['site2'] + df['site3']After adding a new data column df
res1 = df[df['site2'].isnull()]
res2 = df[df['site2'].isna()]
res3 = df[df['site2']=='']res1

res2

res3

Be careful :res1 and res2 Same result for , explain .isna() and .isnull() Equivalent effect of