Code :
f = open("1.txt","r")
s = f.read()
View type :
type(s)The result is str type (byte), There's no mistake here .
s + u'XXX'
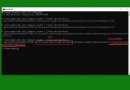
str Type plus one utf-8 What's wrong with encoding a string ?
s Will be implicitly converted to utf-8, however s There may be some Chinese characters that are not in utf-8 The coding of , It will lead to an error !
processing method :s.decode("gb2312") Use gb2312 First to unicode There is no problem with splicing types .
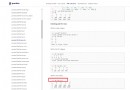
sqlite3.connect( Chinese path )
If the Chinese path is str The type will not be found , You need to change the Chinese path to unicode, Still need to use decode("gb2312").