Regular expression patterns :
^ Match the beginning of the string
$ Match the end of the string
. Match any character , Except for line breaks
[...] Used to represent a set of characters , List... Separately :[amk] matching 'a','m' or 'k'
[^...] be not in [] The characters in :[^abc] Match except a,b,c Other characters .
re* matching 0 One or more expressions .
re+ matching 1 One or more expressions .
re? matching 0 Or 1 Fragments defined by the previous regular expression , Not greedy
[a|b] matching a or b
{n} matching n Time
(re) Group regular expressions and remember the matching text
\w Match alphanumeric and underline
\d Match any number , Equivalent to [0-9]
\D Match any non number
Greedy mode : As long as there are characters matching the pattern after the string, they will always match
Non greedy model : Add one more ?, Stop matching as long as the matching characters appear
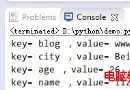
Directly convert the matching result to dictionary mode , Easy to use :
example : Id card 1102231990xxxxxxxx
import re
s = '1102231990xxxxxxxx'
res = re.search('(?P<province>\d{