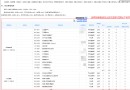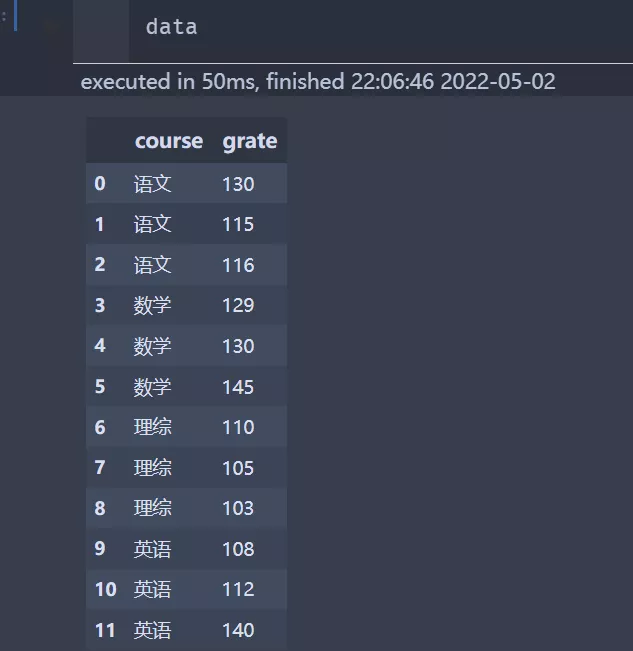
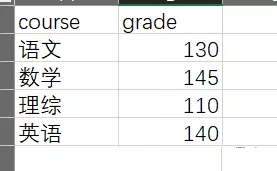
現在需要將course分組,然後選擇出每一組裡面的最大值和最小值,並保留下來
實現下面數據結果:
直接使用groupby函數,不能直接達到此效果,需要在groupby函數上添加apply和lambda函數
代碼如下:
import pandas as pddata = pd.read_excel('group_apply.xlsx')data1 = data.groupby('course').apply(lambda t: t[(t['grade']==t['grade'].min()) ^ (t['grade']==t['grade'].max())])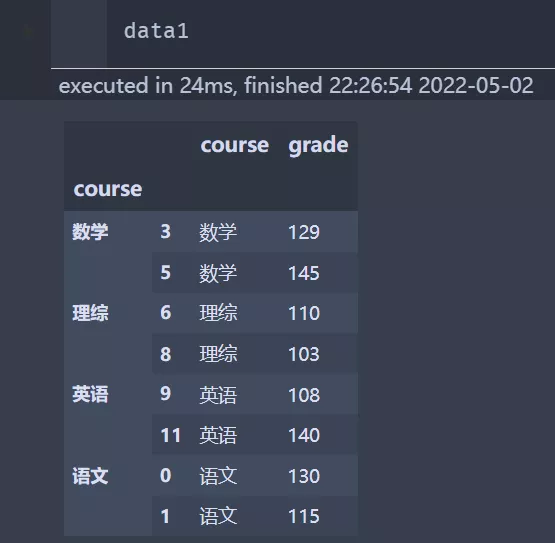
前面的index,是兩列,所以需要處理一下,這個是groypby函數處理之後所產生,只需要刪除即可
data2 = data1.reset_index(drop=True)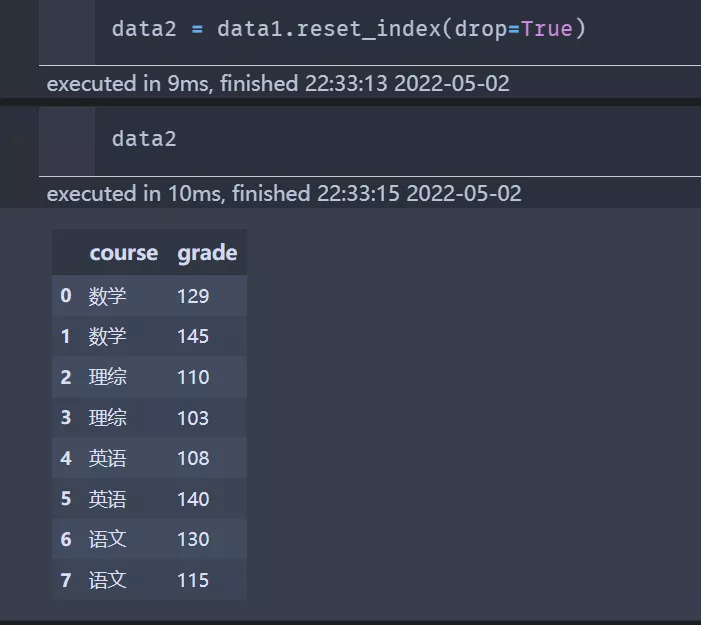
代碼整合:
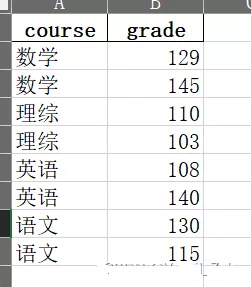
import pandas as pddata = pd.read_excel('group_apply.xlsx')data1 = data.groupby('course').apply(lambda t: t[(t['grade']==t['grade'].min()) ^ (t['grade']==t['grade'].max())])data2 = data1.reset_index(drop=True)寫入到excel中:
到此這篇關於python groupby函數實現分組後選取最值的文章就介紹到這了,更多相關python groupby 內容請搜索軟件開發網以前的文章或繼續浏覽下面的相關文章希望大家以後多多支持軟件開發網!