沒有專門的學習過pandas,都是在應用中逐漸學習的,本篇博客是記錄自己在使用pandas處理數據時候遇到的問題的筆記,以便以後查詢,免得再去搜。 這篇文章持續更新,目前空的內容是我遇到了的但還沒時間寫的,之後會補上,沒遇到的問題後續會完善,所以說並不是騙大家進來的。小伙伴們遇到什麼樣的相關問題,歡迎評論區留言,一起進步!
本文以下面的csv文件為例: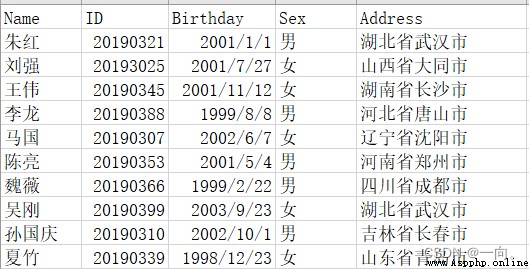
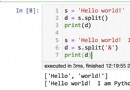
''' 我用WPS保存的csv文件用pycharm後會顯示亂碼 '''
import pandas as pd
#亂碼的一般原因是csv以ANSI編碼形式編碼,一種解決辦法是將csv用記事本打開,另存為UTF-8即可
#第二種方法就是用pandas以ANSI打開,然後再以UTF-8保存即可,之後就可以正常查看了(注意再次讀取的時候編碼不要是ANSI了)
df=pd.read_csv(filePath,encoding="ANSI")
df.to_csv(filePath, encoding="UTF-8",index=False)
#如果要讀取的文件比較多,則可以使用glob批量修改編碼格式
import glob
for file in glob.glob(FilePath): #這裡的FilePath形式:比如文件都在名為data的文件夾中,那麼FilePath就是"data\\*.csv",*.csv的意思就是任何名稱的csv文件
df=pd.read_csv(file,encoding="ANSI")
df.to_csv(file, encoding="UTF-8",index=False)#index=False的意思是不加索引號
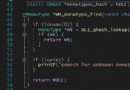
例子:直接使用
df=pd.read_csv("StudentList.csv")
結果報錯:
以ANSI讀取: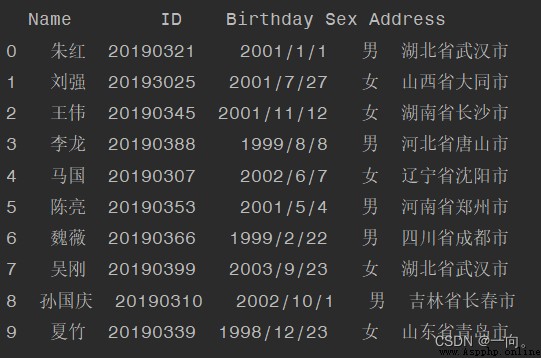
df=pd.read_csv(file,encoding="UTF-8")
#新增的數據我們用一個列表存儲,注意列表長度要與當前df的行數相等,不然報錯加不進去
nList=[1,2,3,4,5,6]#假設原df共6行,不算字段那一行
#新增字段名稱為"newField"
df["newField"]=nList
#保存
df.to_csv(file, encoding="UTF-8",index=False)
例子:新增一列“成績”: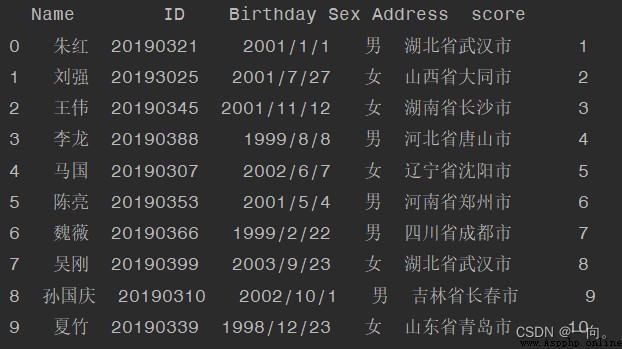
df=pd.read_csv(file,encoding="UTF-8")
#假設刪除名為"name"的列
del df["name"]
#保存
df.to_csv(file, encoding="UTF-8",index=False)
例子:刪除“ID”: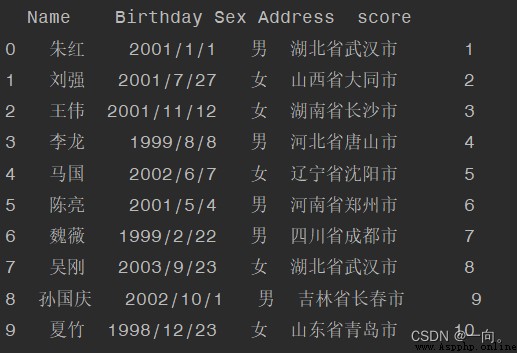
df = pd.read_csv(filePath,header=None)
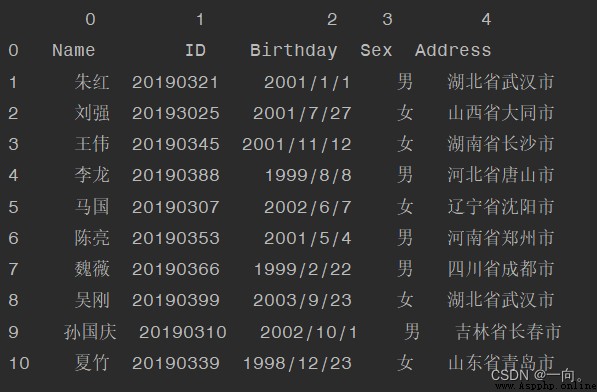
def dropText():
df = pd.read_csv(filePath)
#以FieldName為准,若其包含:yourText文本則刪除此行
df = df.drop(df[df["FieldName"].str.contains("yourtext")].index)
df.to_csv(filePath, index=False, encoding="UTF-8")
def dropDuplicate():
df = pd.read_csv(filePath)
#以FieldName為准,刪除其重復數據,保留最後一行last
df.drop_duplicates('FieldName', keep='last', inplace=True)
df.to_csv(filePath, index=False, encoding="UTF-8")
df = pd.read_csv(filePath, encoding="UTF-8")
print(len(df))
#合並效果:相同字段名的列對應追加,在豎直方向上追加,得到的新文件包含所有csv文件的所有列名。若待合並的文件的字段名或個數不對應,則不具有相應字段的值為空
df1=pd.read_csv(FilePath_1)
df2 = pd.read_csv(FilePath_2)
df3 = pd.read_csv(FilePath_3)
df=pd.concat([df1,df2,df3]) #更多列表以此類推即可
df.to_csv(FilePath, encoding='utf-8', index=False)
df = pd.read_csv(TxtFilePath,delimiter="\t",header=None)#txt沒有字段名的前提下
df.columns = ['id','name','age'] #字段名列表,這裡我們給了3個字段名
df.to_csv(CsvFilePath, encoding='utf-8', index=False)
這篇文章持續更新,小伙伴們遇到什麼樣的相關問題,歡迎評論區留言,我們一起進步啊!