No special study pandas, All of them are gradually learned through application , This blog is a record of my use of pandas Notes on problems encountered while processing data , For future reference , So as not to search again . This article is constantly updated , At present, the empty content is what I met but haven't had time to write , After the meeting , Problems not encountered will be improved in the future , So I didn't lie to everyone . What kind of problems do you have , Leave a comment in the comments section , Progress together !
This article is based on the following csv File as an example :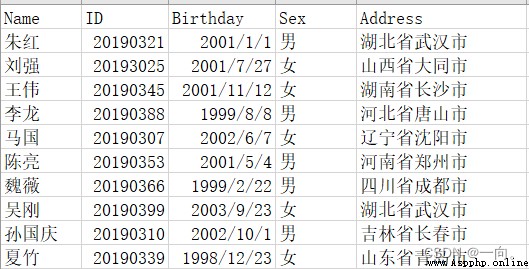
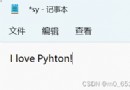
''' I use WPS The saved csv For documents pycharm It will display garbled code '''
import pandas as pd
# The general reason for garbled code is csv With ANSI Code form code , One solution is to csv Open in Notepad , Save as UTF-8 that will do
# The second way is to use pandas With ANSI open , And then UTF-8 Save it , Then you can view it normally ( Be careful not to read the code again ANSI 了 )
df=pd.read_csv(filePath,encoding="ANSI")
df.to_csv(filePath, encoding="UTF-8",index=False)
# If there are many files to read , You can use glob Batch modify coding format
import glob
for file in glob.glob(FilePath): # there FilePath form : For example, the files are all named data In the folder of , that FilePath Namely "data\\*.csv",*.csv It means any name csv file
df=pd.read_csv(file,encoding="ANSI")
df.to_csv(file, encoding="UTF-8",index=False)#index=False Don't use quotation marks
Example : Use it directly
df=pd.read_csv("StudentList.csv")
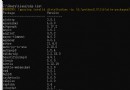
The result is wrong :
With ANSI Read :
df=pd.read_csv(file,encoding="UTF-8")
# We use a list to store the new data , Note that the length of the list should be the same as the current df The number of rows is equal , Otherwise, the error report will not be added
nList=[1,2,3,4,5,6]# Hypothetical origin df common 6 That's ok , Not counting the field line
# The new field name is "newField"
df["newField"]=nList
# preservation
df.to_csv(file, encoding="UTF-8",index=False)
Example : Add a new column “ achievement ”: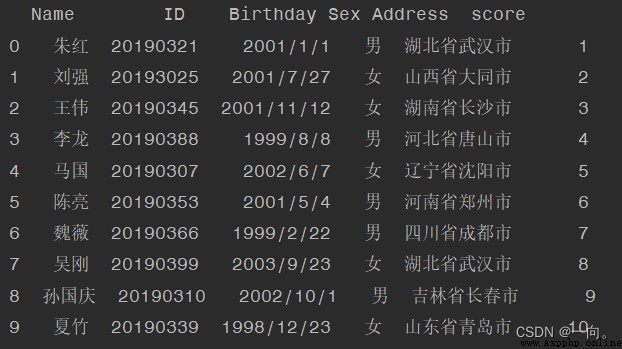
df=pd.read_csv(file,encoding="UTF-8")
# Suppose the deletion is named "name" The column of
del df["name"]
# preservation
df.to_csv(file, encoding="UTF-8",index=False)
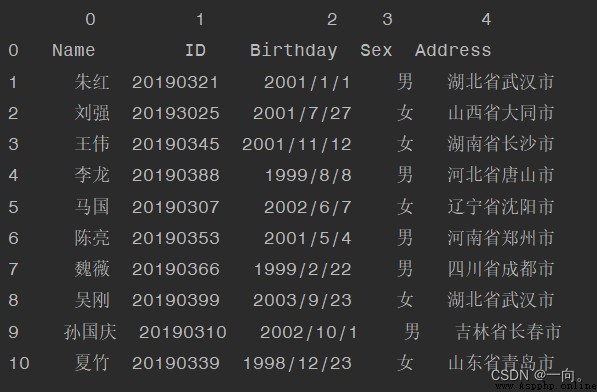
Example : Delete “ID”: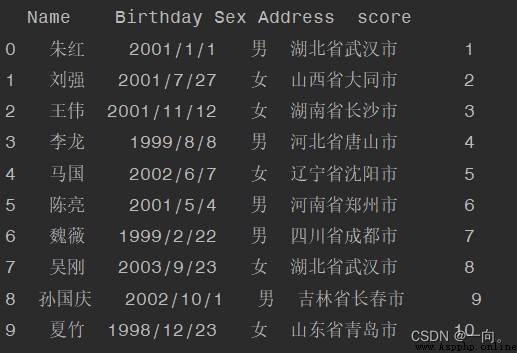
df = pd.read_csv(filePath,header=None)
def dropText():
df = pd.read_csv(filePath)
# With FieldName Subject to , If it contains :yourText Text delete this line
df = df.drop(df[df["FieldName"].str.contains("yourtext")].index)
df.to_csv(filePath, index=False, encoding="UTF-8")
def dropDuplicate():
df = pd.read_csv(filePath)
# With FieldName Subject to , Remove its duplicate data , Keep the last line last
df.drop_duplicates('FieldName', keep='last', inplace=True)
df.to_csv(filePath, index=False, encoding="UTF-8")
df = pd.read_csv(filePath, encoding="UTF-8")
print(len(df))
# Merge effect : Columns with the same field name are appended , Add... In the vertical direction , The resulting new file contains all csv All column names of the file . If the field names or numbers of the files to be merged do not correspond , Then the value without corresponding field is null
df1=pd.read_csv(FilePath_1)
df2 = pd.read_csv(FilePath_2)
df3 = pd.read_csv(FilePath_3)
df=pd.concat([df1,df2,df3]) # More lists and so on
df.to_csv(FilePath, encoding='utf-8', index=False)
df = pd.read_csv(TxtFilePath,delimiter="\t",header=None)#txt Without the field name
df.columns = ['id','name','age'] # List of field names , Here we give 3 Field names
df.to_csv(CsvFilePath, encoding='utf-8', index=False)
This article is constantly updated , What kind of problems do you have , Leave a comment in the comments section , Let's make progress together !