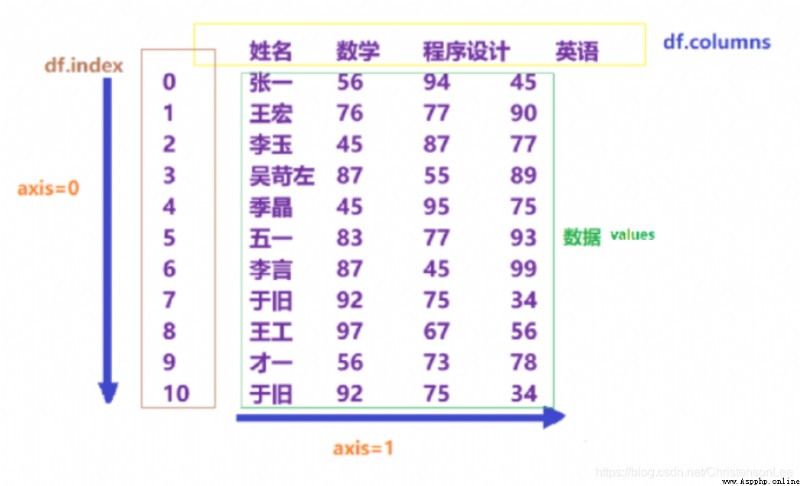
1. Format :pandas.DataFrame(data[,index[,columns]])
2. Random number generation DataFrame object , Use the default index .
import numpy as np
import pandas as pd
# Set output result column alignment
pd.set_option('display.unicode.ambiguous_as_wide', True)
pd.set_option('display.unicode.east_asian_width', True)
# stay [1,20] Generate on interval 5 That's ok 3 Column 15 A random number
# Use index Parameter specifies the index ( The default from the 0 Start ),columns Parameter specifies the title of each column
df = pd.DataFrame(np.random.randint(1, 20, (5,3)),
index=range(5),
columns=('A', 'B', 'C'))
#print(df,df.values,df.index,df.columns,sep='\n\n')
3. Random number generation DataFrame object , Use time series as an index
# simulation 2020 year 7 month 15 Cooked food in a supermarket 、 cosmetics 、 Hourly sales of daily necessities
# Use time series as an index
df = pd.DataFrame(np.random.randint(5, 15, (10, 3)),
index=pd.date_range(start='202007150900',
end='202007151800',
freq='H'),
columns=[' deli ', ' cosmetics ', ' Daily Necessities '])
#print(df,df.values,df.index,df.columns,sep='\n\n')
4. Create with dictionary DataFrame object Use the name string as an index
df = pd.DataFrame({
' Chinese language and literature ':[87,79,67,92],
' mathematics ':[93,89,80,77],
' English ':[90,80,70,75]},
index=[' Zhang San ', ' Li Si ', ' Wang Wu ', ' Zhao Liu '])
#print(df,df.values,df.index,df.columns,sep='\n\n')
5. Nested dictionary creation DataFrame object .
External key generation column name , Internal keys generate index labels .
df = pd.DataFrame({
' Zhang San ':{
' mathematics ':67,' Programming ':78},
' Yang Xia ':{
' Physics ':78,' Programming ':99},
' My pupils are popping ':{
' mathematics ':56,' Internship ':67}})
print(df,df.values,df.index,df.columns,sep='\n\n')
Running results :
Zhang San Yang Xia My pupils are popping
mathematics 67.0 NaN 56.0
Programming 78.0 99.0 NaN
Physics NaN 78.0 NaN
Internship NaN NaN 67.0
[[67. nan 56.]
[78. 99. nan]
[nan 78. nan]
[nan nan 67.]]
Index([' mathematics ', ' Programming ', ' Physics ', ' Internship '], dtype='object')
Index([' Zhang San ', ' Yang Xia ', ' My pupils are popping '], dtype='object')
6. By Series A dictionary composed of DataFrame object
df = pd.DataFrame({
'product':pd.Series([' The TV ',' mobile phone ',' Air conditioner ']),
'price':pd.Series([6500,3400,7899]),
'count':[23,45,28]})
df1 = pd.DataFrame({
'product':[' The TV ',' mobile phone ',' Air conditioner '],
'price':[6500,3400,7899],
'count':[23,45,28]})
print(df,df1,sep='\n\n')
# The dictionary can be partially selected , Generate DataFrame object
dt = {
'product':[' The TV ',' mobile phone ',' Air conditioner '],
'price':[6500,3400,7899],
'count':[23,45,28]}
# Generated by the 'product' And 'count' Column DataFrame object
df1 = pd.DataFrame(dt,columns=['product','count'])
print('\n',df1)
Running results :
product price count
0 The TV 6500 23
1 mobile phone 3400 45
2 Air conditioner 7899 28
product price count
0 The TV 6500 23
1 mobile phone 3400 45
2 Air conditioner 7899 28
product count
0 The TV 23
1 mobile phone 45
2 Air conditioner 28
1. See the former n That's ok 、 after n Row data : function head() And tail() Use
df = pd.DataFrame({
' Chinese language and literature ':[87,79,67,92,67,87,54],
' mathematics ':[93,89,80,77,56,78,69],
' English ':[90,80,70,75,75,34,85]},
index=[' Zhang San ', ' Li Si ', ' Wang Wu ', ' Zhao Liu ',' The crown ',' Zhang Yi ',' Wu Yu '])
print(' Look at all the data '.center(20,'='))
#print(df,'\n')
# See the former n That's ok 、 after n Row data : function head() And tail() Use
print(' See the former 5 Row data '.center(20,'='))
#print(df.head(5),df.head(),sep='\n\n') # With no arguments , The default is 5
print(' After viewing 3 Row data '.center(20,'='))
#print(df.tail(3),df.tail(),sep='\n\n') # With no arguments , The default is 5
2. Using column names to access a column's data
# Using column names to access a column's data
print('\n',df)
print(' utilize [ Name ] Access the entire column of data '.center(20,'='))
print(df[' Chinese language and literature '].head(2))
print("df. Name And df[' Name '] Visit the same ".center(30,'='))
print(df[' Chinese language and literature '],df. Chinese language and literature ,sep='\n')
# utilize [ Name , Name ,...] Accessing multiple columns of data
print(' utilize [ Name , Name ,...] Accessing multiple columns of data '.center(26,'='))
print(df[ [' Chinese language and literature ',' English '] ].tail(6))
Running results :
Chinese language and literature mathematics English
Zhang San 87 93 90
Li Si 79 89 80
Wang Wu 67 80 70
Zhao Liu 92 77 75
The crown 67 56 75
Zhang Yi 87 78 34
Wu Yu 54 69 85
=== utilize [ Name ] Access the entire column of data ====
Zhang San 87
Li Si 79
Name: Chinese language and literature , dtype: int64
====df. Name And df[' Name '] Visit the same =====
Zhang San 87
Li Si 79
Wang Wu 67
Zhao Liu 92
The crown 67
Zhang Yi 87
Wu Yu 54
Name: Chinese language and literature , dtype: int64
=== utilize [ Name , Name ,...] Accessing multiple columns of data ===
Chinese language and literature English
Li Si 79 80
Wang Wu 67 70
Zhao Liu 92 75
The crown 67 75
Zhang Yi 87 34
Wu Yu 54 85
3. Access specified information
# Access all information of the specified information , If displayed " Wu Yu " All achievements
# Conditions of the query , Access through the row index .
print(' Show all Wu Yu's achievements '.center(30,'='))
print(df[df.index==' Wu Yu '])
print(' Show all crown scores '.center(30,'='))
print(df[df.index==' The crown '])
print(' Show all the scores of Zhao Liu '.center(30,'='))
print(df[df.index==' Zhao Liu '])
4. Add or modify a column of data
# Add a new column of data , The new data must match the number of rows of the original data . Otherwise ValueError Throw an exception
df['python'] = [78,54,89,76,56,45,87] # If the index does not exist , Add a piece of data
df[' Chinese language and literature '] = [100,100,100,100,100,100,100] # If index exists , Modifying data
print(df)
5. Add or modify a row of data
# use loc function ( Inquire about ), Insert a line directly
print(' newly added Yu Yi All the achievements of '.center(29,'='))
df.loc[' Yu Yi '] = [66,45,88,99] # If the index does not exist , Add a piece of data
df.loc[' Zhao Liu '] = [99,99,99,99] # If index exists , Modifying data
print(df)
Running results :
========== Show all Wu Yu's achievements ===========
Chinese language and literature mathematics English
Wu Yu 54 69 85
========== Show all crown scores ===========
Chinese language and literature mathematics English
The crown 67 56 75
========== Show all the scores of Zhao Liu ===========
Chinese language and literature mathematics English
Zhao Liu 92 77 75
Chinese language and literature mathematics English python
Zhang San 100 93 90 78
Li Si 100 89 80 54
Wang Wu 100 80 70 89
Zhao Liu 100 77 75 76
The crown 100 56 75 56
Zhang Yi 100 78 34 45
Wu Yu 100 69 85 87
========= newly added Yu Yi All the achievements of ========
Chinese language and literature mathematics English python
Zhang San 100 93 90 78
Li Si 100 89 80 54
Wang Wu 100 80 70 89
Zhao Liu 99 99 99 99
The crown 100 56 75 56
Zhang Yi 100 78 34 45
Wu Yu 100 69 85 87
Yu Yi 66 45 88 99
6. Using slices to access one or more rows of data
# Using slices to access one or more rows of data
print(' Using slices to access one or more rows of data '.center(26,'='))
print(df[:1],df[3:6],sep='\n\n')
# Use the index to access the specified element
print(df[' mathematics '][6])
Running results :
====== Using slices to access one or more rows of data ======
Chinese language and literature mathematics English python
Zhang San 100 93 90 78
Chinese language and literature mathematics English python
Zhao Liu 99 99 99 99
The crown 100 56 75 56
Zhang Yi 100 78 34 45
69
7. Using slices to access multiple rows and columns of data
print(' Using slices to access multiple rows and columns of data '.center(26,'='))
#print(df[ [' Chinese language and literature ','python',' mathematics '] ][2:5])
#print(df[2:5][ [' Chinese language and literature ','python',' mathematics '] ])
Running results :
======= Using slices to access multiple rows and columns of data =======
Chinese language and literature python mathematics
Wang Wu 100 89 80
Zhao Liu 99 99 99
The crown 100 56 56
Chinese language and literature python mathematics
Wang Wu 100 89 80
Zhao Liu 99 99 99
The crown 100 56 56
8. utilize loc,iloc To access or modify specified information
''' loc[ Row index name or condition , Column index name ] iloc[ Row index location , Column index position ] or iloc[ Row index location ] namely iloc Index with numbers '''
print(df)
print(' The index for 5 The line of iloc[5]'.center(40,'='))
print(df.iloc[5])
print(' The index for [3:5] The line of iloc[3:5]'.center(40, '='))
print(df.iloc[3:5])
print(' The index for [3:5] And the column is 0:2 All data for '.center(40, '='))
print(df.iloc[3:5,0:2])
print(' Access the specified row (0,3,5) Specified column (0,2) The data of '.center(40, '='))
print(df.iloc[[0,3,5],[0,2]])
print(' visit " Yu Yi " Chinese and python achievement '.center(40, '='))
print(df)
print(' Change the row index to 5 Value iloc[5]'.center(40,'='))
df.iloc[5]=[100,65,99,99] # Change the row index to 5 Value
print(df.iloc[5])
print(' Change the index to [3:5] The row data of iloc[3:5]'.center(40, '='))
df.iloc[3:5]=100 # The index for [3:5] All data are modified to 100
print(df.iloc[3:5])
print(' take python Multiply the score by 0.7'.center(40, '='))
df. Chinese language and literature =df. Chinese language and literature *0.7
print(df)
print(' take " Wu Yu " Scores are all increased 10'.center(40, '='))
df.loc[' Wu Yu '] =df.loc[' Wu Yu ']+10
Running results :
Chinese language and literature mathematics English python
Zhang San 100 93 90 78
Li Si 100 89 80 54
Wang Wu 100 80 70 89
Zhao Liu 99 99 99 99
The crown 100 56 75 56
Zhang Yi 100 78 34 45
Wu Yu 100 69 85 87
Yu Yi 66 45 88 99
============= The index for 5 The line of iloc[5]=============
Chinese language and literature 100
mathematics 78
English 34
python 45
Name: Zhang Yi , dtype: int64
========== The index for [3:5] The line of iloc[3:5]==========
Chinese language and literature mathematics English python
Zhao Liu 99 99 99 99
The crown 100 56 75 56
========= The index for [3:5] And the column is 0:2 All data for ==========
Chinese language and literature mathematics
Zhao Liu 99 99
The crown 100 56
======== Access the specified row (0,3,5) Specified column (0,2) The data of =========
Chinese language and literature English
Zhang San 100 90
Zhao Liu 99 99
Zhang Yi 100 34
=========== visit " Yu Yi " Chinese and python achievement ===========
Chinese language and literature mathematics English python
Zhang San 100 93 90 78
Li Si 100 89 80 54
Wang Wu 100 80 70 89
Zhao Liu 99 99 99 99
The crown 100 56 75 56
Zhang Yi 100 78 34 45
Wu Yu 100 69 85 87
Yu Yi 66 45 88 99
=========== Change the row index to 5 Value iloc[5]============
Chinese language and literature 100
mathematics 65
English 99
python 99
Name: Zhang Yi , dtype: int64
======= Change the index to [3:5] The row data of iloc[3:5]========
Chinese language and literature mathematics English python
Zhao Liu 100 100 100 100
The crown 100 100 100 100
============= take python Multiply the score by 0.7=============
Chinese language and literature mathematics English python
Zhang San 70.0 93 90 78
Li Si 70.0 89 80 54
Wang Wu 70.0 80 70 89
Zhao Liu 70.0 100 100 100
The crown 70.0 100 100 100
Zhang Yi 70.0 65 99 99
Wu Yu 70.0 69 85 87
Yu Yi 46.2 45 88 99
============== take " Wu Yu " Scores are all increased 10===============
Chinese language and literature mathematics English python
Zhang San 70.0 93.0 90.0 78.0
Li Si 70.0 89.0 80.0 54.0
Wang Wu 70.0 80.0 70.0 89.0
Zhao Liu 70.0 100.0 100.0 100.0
The crown 70.0 100.0 100.0 100.0
Zhang Yi 70.0 65.0 99.0 99.0
Wu Yu 80.0 79.0 95.0 97.0
Yu Yi 46.2 45.0 88.0 99.0
9. Filter data that meets the criteria
# Filter languages below 60 The achievement of
df1 = df[df. Chinese language and literature <60]
df11 = df[df[' Chinese language and literature ']<60]
print(df1,df11,sep='\n\n')
# Screening languages and python All below 60 Information about
df2 = df[(df. Chinese language and literature <60) & (df.python<60)]
print(df2)
Running results :
Chinese language and literature mathematics English python
Yu Yi 46.2 45.0 88.0 99.0
Chinese language and literature mathematics English python
Yu Yi 46.2 45.0 88.0 99.0
Empty DataFrame
Columns: [ Chinese language and literature , mathematics , English , python]
Index: []
10. How to insert data
import pandas as pd
# Use the list to generate DataFrame object
df1 = pd.DataFrame([[' Zhang Yi ',' male ',20],
[' Fifty ',' male ',22],
[' Wu Xia ',' male ',18],
[' Liujiaoyu ',' Woman ',19]],
columns=[' full name ',' Gender ',' Age '])
print(" Add a new column at the end ".center(30,'='))
print(" Add... At the end of the data frame ‘ Native place ’ A column of ")
# The number of elements added to the column should be the same as that of the original data column
df1[' Native place ']=[' jiangsu ',' Henan ',' jiangsu ',' Zhejiang ']
print(df1)
# Add a column at the specified position use insert()
print(" Add a new column at the specified position : use insert()".center(30,'='))
# If in ’ Gender ‘ Then add a column ’ class ‘. It can be used insert Methods
# Grammar format : list .insert(index, obj)
# index : object obj Index location to insert .
# obj : To insert an object in the list ( Name )
df1.insert(2,' class ',[' Talented person 1901']*4)
print(df1)
Running results :
=========== Add a new column at the end ============
Add... At the end of the data frame ‘ Native place ’ A column of
full name Gender Age Native place
0 Zhang Yi male 20 jiangsu
1 Fifty male 22 Henan
2 Wu Xia male 18 jiangsu
3 Liujiaoyu Woman 19 Zhejiang
===== Add a new column at the specified position : use insert()=====
full name Gender class Age Native place
0 Zhang Yi male Talented person 1901 20 jiangsu
1 Fifty male Talented person 1901 22 Henan
2 Wu Xia male Talented person 1901 18 jiangsu
3 Liujiaoyu Woman Talented person 1901 19 Zhejiang
Did the big guy learn ? Remember to connect three times with one button ~
Three kegs ~ O(∩_∩)O ha-ha ~