1.爬蟲框架介紹
1.1.框架的概念
- 框架是為了為解決一類問題而開發的程序,框架兩個字可以分開理解,框:表示制定解決問題的邊界,明確要解決的問題;架:表達的是能夠提供一定的支撐性和可擴展性;從而實現解決這類問題達到快速開發的目的。
- 框架是一個半成品,已經對基礎的代碼進行了封裝並提供相應的API,開發者在使用框架時直接調用封裝好的API可以省去很多代碼編寫,從而提高工作效率和開發速度。
1.2.為什麼爬蟲需要使用框架
- 在Python所編寫的爬蟲程序中,我們可以使用之前介紹的HTTP請求庫來完成90%的爬蟲需求。但是,由於一些其他的因素,比如爬取效率低、所需數據量非常大和開發效率等,所以我們會使用到一些框架來滿足這些需求。
- 由於框架中封裝了一些通用的工具,可以節省開發者的時間,增加開發效率。
1.3.Scrapy
- Scrapy是Python開發的一個快速、高層次的web數據抓取框架,用於抓取web站點並從頁面中提取結構化的數據。
- Scrapy使用了Twisted異步網絡框架,可以加快我們的下載速度。只需要少量的代碼,就能夠實現數據快速的抓取。
1.4.Scrapy-Redis
- Redis:是一個開源的使用ANSI C語言編寫、遵守BSD協議、支持網絡、可基於內存亦可持久化的日志型、Key-Value數據庫,並提供多種語言的API。
- Scrapy-Redis是為了更方便地實現Scrapy分布式爬取,而提供了一些以redis為基礎的組件(僅有組件)。通過Scrapy-Redis可以快速地實現簡單分布式爬蟲程序,該組件本質上提供了三大功能:
- scheduler,調度器
- dupefilter,URL去重規則
- item pipeline,數據持久化
1.5.PySpider
- PySpider是一個簡單易用且強大的Python主流爬蟲框架。
- PySprider帶有強大的WebUI、腳本編輯器、任務監控器、項目管理器以及結果處理器,它支持多種數據庫後端、多種消息隊列、JavaScript渲染頁面的爬取,使用起來非常方便。
- PySprider的可擴展程度不足,可配置化程度不高。
2.Scrapy框架
2.1.爬蟲工作流程
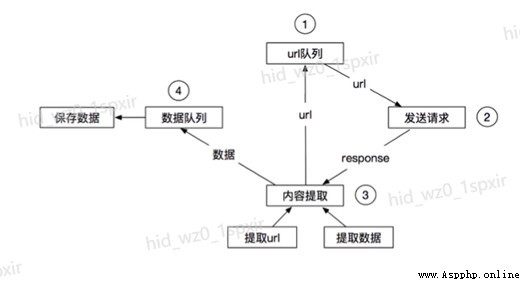
2.2.Scrapy架構

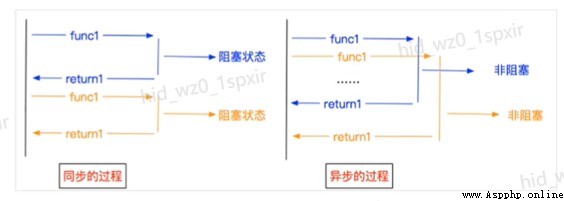
2.3.異步非阻塞
- 異步:調用在發出之後,這個調用就直接返回,不管有無結果;異步是過程。
- 非阻塞:關注的是程序在等待調用結果(消息,返回值)時的狀態,指在不能立刻得到結果之前,該調用不會阻塞當前線程。
2.4.Scrapy組件
- 引擎(Engine):用來處理整個系統的數據流處理,觸發事務(框架核心)。
- 調度器(Scheduler):用來接受引擎發過來的請求,壓入隊列中,並在引擎再次請求的時候返回。可以想象成一個URL(抓取網頁的網址或者說是鏈接)的優先隊列,由它來決定下一個要抓取的網址是什麼,同時去除重復的網址。
- 下載器(Downloader):用於下載網頁內容,並將網頁內容返回給spider(Scrapy下載器是建立在Twisted這個高效的異步模型上的)。
- 爬蟲(Spiders):spider是爬蟲程序主體,用於從特定的網頁中提取自己需要的信息,即所謂的實體(item)。用戶也可以從中提取鏈接,讓Scrapy繼續抓取下一個頁面。
- 管道(Pipeline):負責處理爬蟲從網頁中提取的實體,主要的功能是持久化實體、驗證實體的有效性、清除不需要的信息。當頁面被爬蟲解析後,將被發送到項目管道,並經過幾個特定的次序處理數據。
- 下載器中間件(Downloader Middlewares):位於Scrapy引擎和下載器之間的框架,主要是處理Scrapy引擎與下載器之間的請求及響應。
- 爬蟲中間件(Spider Middlewares):介於Scrapy引擎和爬蟲之間的組件,主要工作是處理spider的響應輸入和請求輸出。
- 調度中間件(Scheduler Middlewares):介於Scrapy引擎和調度之間的中間件,從Scrapy引擎發送到調度的請求和響應。
2.5.創建Scrapy工程
- 創建Scrapy項目的命令:scrapy startproject + <項目名字>
- scrapy startproject MySprider
- 工程結構
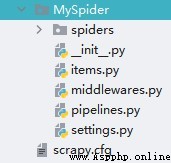
2.6.項目解析 - scrapy.cfg
- scrapy.cfg:Scrapy的項目配置文件,其內定義了項目的配置文件路徑、部署相關信息等內容。
- settings:項目中的全局配置文件。
- deploy:項目部署配置。
2.7.項目解析 - middlewares
- middlewares.py:可以分為爬蟲中間件和下載中間件。
- MyspiderSpiderMiddleware:爬蟲中間件是可以自定義requests請求和進行response過濾,一般不需要手寫。
- MyspiderDownloaderMiddleware可以自定義的下載擴展,比如設置代理等。
2.8.項目解析 - settings
- settings.py:項目的全局配置文件。
- 常用字段:
- USER_AGENT:設置user-agent參數(默認未開啟)。
- ROBOTSTXT_OBEY:是否遵守robots協議,默認是遵守(默認開啟)。
- CONCURRENT_REQUESTS:設置並發請求的數量(默認是16個)。
- DOWNLOAD_DELAY:下載延遲(默認無延遲)。
- COOKIES_ENABLED:是否開啟cookie,即每次請求帶上前一次的cookie(默認是開啟)。
- DEFAULT_REQUEST_HEADERS:設置默認請求頭(默認未設置)。
- SPIDER_MIDDLERWARES:爬蟲中間件,設置過程和管道相同(默認未開啟)
- DOWNLOADER_MIDDLEWARES:下載中間件(默認未開啟)。
- ITEM_PIPELINES:開啟管道。
2.9.項目解析 - items,pipelines
- items.py:定義item數據結構,即自己要爬取的內容,所有item的定義都可以放在這裡。
- pipelines.py:定義item pipeline的實現用於保存數據。
- 不同的pipeline可以處理不同爬蟲的數據,通過spider.name屬性來區分。
- 不同的pipeline能夠對一個或多個爬蟲進行不同的數據處理的操作,比如一個進行數據清洗,一個進行數據的保存。
- process_item(self,item,spider):實現對item數據的處理。
- open_spider(self,spider):在爬蟲開啟的時候僅執行一次。
- close_spider(self,spider):在爬蟲關閉的時候僅執行一次。
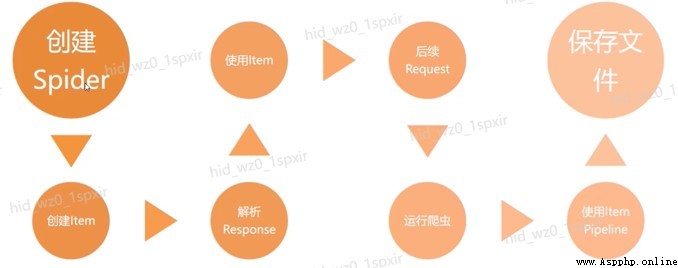
2.10.Scrapy爬蟲執行流程
2.11.ScrapyShell
- ScrapyShell是Scrapy提供的一個終端工具,能夠通過它查看Scrapy中對象的屬性和方法,以及測試Xpath。
- 在命令行內輸入:scrapy shell <網站的url>,進入Python的交互式終端。
- 進入交互式命令行:scrapy shell http://xxxx.xxx
- 進入交互式命令行後:
- response.xpath():直接測試xpath規則是否正確。
- response.url:當前響應的url地址。
- response.request.url:當前響應對應的請求的url地址。
- response.headers:響應頭
- response.body:響應體,也就是html代碼,默認是byte類型。
- response.requests.headers:當前響應的請求頭。
2.12.Scrapy日志
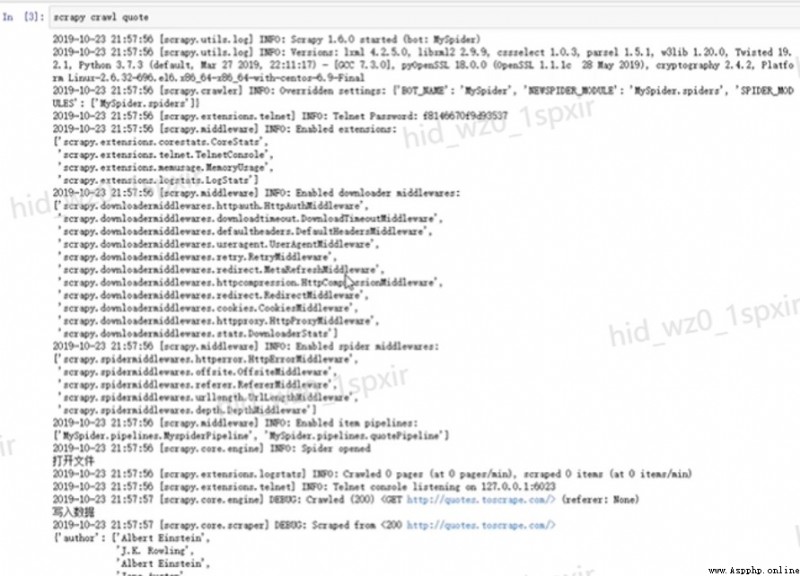
2.13.Scrapy日志解析
- Scrapy在運行時會默認打印一些日志信息。
- [scrapy.utils.log] INFO:scrapy工程的settings信息。
- [scrapy.middleware] INFO:工程啟動的擴展程序、下載中間件、管道。
- [scrapy.extension.telnet] DEBUG:爬蟲運行時能夠用talnet命令進行控制。
- [scrapy.statscollectors] INFO:爬蟲結束時的一些統計信息。
2.14.爬蟲分類
- Scrapy框架中的爬蟲分為兩類:Spider和Crawlspider。
- Spider類的設計原則是只爬取start_url列表中的網頁。
- Crawlspider是Spider的派生類(一個子類),CrawlSpider類定義了一些規則(rule)能夠匹配滿足條件的URL地址,組裝成Request對象後自動發送給引擎,同時能夠指定callback函數。
2.15.創建spider
- 使用命令:scrapy genspider + <爬蟲名字> + <允許爬取的域名>
- scrapy genspider baidu www.baidu.com
2.16.Spider參數解析
- 使用命令創建spider後會自動生成一些代碼:
- BaiduSpider:當前的爬蟲類。
- name:爬蟲的唯一標識名。
- allowed_domains:url范圍。
- start_urls:起始爬取的url。
- parse:數據定位。

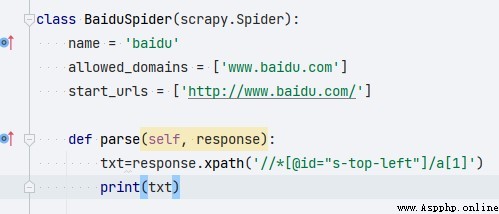
2.17.定義parse
parse方法定義了response的處理過程:
- Scrapy中的response可以直接使用xpath進行數據定位
2.18.Scrapy.Request
scrapy.Request(url[,callback,method=“GET”,headers,body,cookies,meta,dont_filter=False]):scrapy中用於發送請求的類。
- callback:當前請求url的響應的處理函數。
- method:指定POST或GET請求。
- headers:接收一個字典,其中不包括cookies。
- cookies:接收一個字典,專門放置cookies。
- body:接收一個字典,為POST的數據。
- dont_filter:過濾url,不會對已請求過的url再次請求。
- meta:實現數據在不同的解析函數中傳遞。
2.19.運行爬蟲
在項目目錄下執行scrapy crawl +spider
- scrapy crawl quote
- 運行後會打印scrapy的項目日志,沒有開啟管道設置數據處理的方法,爬取的數據也會在日志文件中。
2.20.Crawlspider爬蟲創建
創建crawlspider:
- scrapy genspider -t crawl 爬蟲名字 爬取范圍
- scrapy genspider -t crawl crawl_baidu www.baidu.com
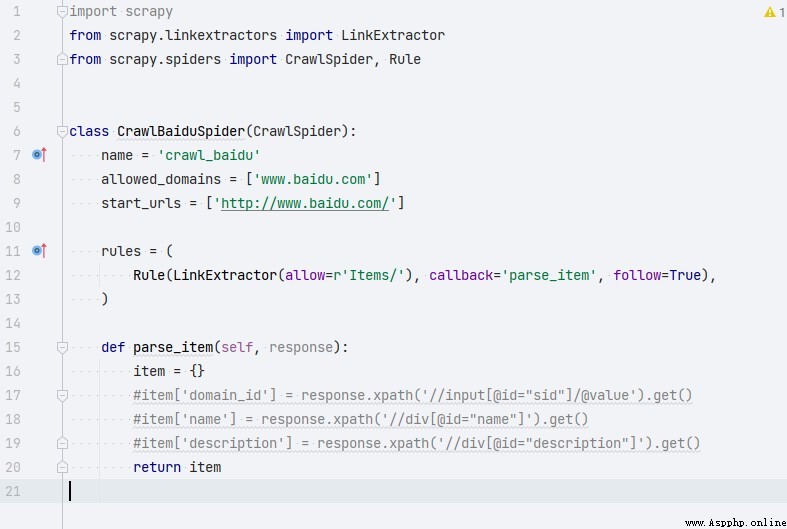
2.21.Crawlspider參數解析
相比於Spider,CrawlSpider中多了rules屬性。少了parse方法。
- rules:滿足匹配規則的url。
- Rule表示規則。
- LinkExtractor:連接提取器,可以通過正則、xpath來進行匹配。
- callback:表示經過連接提取器提取出來的url地址響應的回調函數。
2.22.Scrapy中間件
- Scrapy中的中間件主要功能為在爬蟲運行過程中進行一些處理,如對於非200的響應後續處理、發送請求時headers字段和cookie的處理。
- Scrapy中的中間件根據功能可以分為兩類:下載中間件、爬蟲中間件。
2.23.下載中間件
- 主要功能在請求到網頁後,頁面被下載時進行一些處理。
- 下載中間件Downloader Middlewares:
- process_request(self,request,spider):當每個request通過下載中間件時,該方法被調用。
- process_response(self,request,response,spider):當下載器完成http請求,傳遞響應給引擎時調用。
2.24.爬蟲中間件
- 主要功能是在爬蟲運行過程中進行一些處理。
- 爬蟲中間件Spider Middleware:
- process_spider_input:接收一個response對象並處理。
- process_spider_exception:spider出現的異常時被調用。
2.25.中間件使用注意事項
- Scrapy中的中間件寫在工程項目中的middlewares.py文件中。
- 中間件在寫好以後需要在settings.py文件中開啟。
- SPIDER_MIDDLEWARES:爬蟲中間件
- DOWNLOADER_MIDDLEWARES:下載中間件