1. Introduction to reptile framework
1.1. Concept of framework
- A framework is a program developed to solve a class of problems , Frame can be understood separately , box : It means to set the boundary for solving the problem , Identify the problem to be solved ; frame : The expression is to provide a certain degree of support and scalability ; So as to solve such problems and achieve the purpose of rapid development .
- The frame is a semi-finished product , The basic code has been encapsulated and the corresponding API, When developers use the framework, they directly call the encapsulated API You can save a lot of code , So as to improve work efficiency and development speed .
1.2. Why do crawlers need to use frames
- stay Python In the crawler program written , We can use the previously introduced HTTP Request the library to complete 90% Reptile requirements for . however , Due to some other factors , For example, the crawling efficiency is low 、 The amount of data required is very large and the development efficiency is very high , So we will use some frameworks to meet these requirements .
- Because some general tools are encapsulated in the framework , It can save developers' time , Increase development efficiency .
1.3.Scrapy
- Scrapy yes Python A fast development 、 High level web Data capture framework , Used to grab web Site and extract structured data from the page .
- Scrapy Used Twisted Asynchronous network framework , Can speed up our Downloads . Just a little bit of code , Data can be captured quickly .
1.4.Scrapy-Redis
- Redis: Is an open source use ANSI C Language writing 、 comply with BSD agreement 、 Support network 、 Log type that can be memory based or persistent 、Key-Value database , And provide multilingual API.
- Scrapy-Redis It's for convenience Scrapy Distributed crawling , And offered some to redis Based components ( Only components ). adopt Scrapy-Redis Can quickly implement a simple distributed crawler , This component essentially provides three functions :
- scheduler, Scheduler
- dupefilter,URL Go back to the rules
- item pipeline, Data persistence
1.5.PySpider
- PySpider Is an easy to use and powerful Python Mainstream crawler framework .
- PySprider With powerful WebUI、 Script editor 、 Task monitor 、 Project manager and result processor , It supports a variety of database backend 、 Multiple message queues 、JavaScript Rendering page crawling , It is very convenient to use .
- PySprider Is not scalable enough , The degree of configurability is not high .
2.Scrapy frame
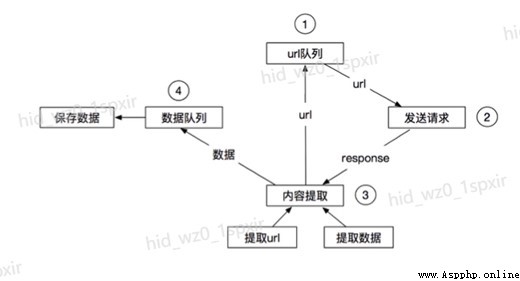
2.1. Reptile workflow
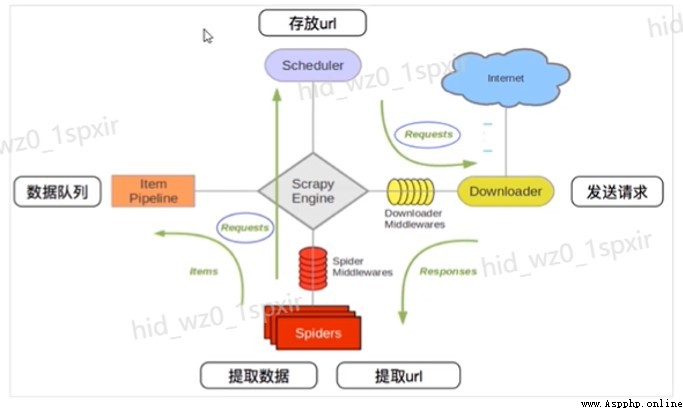
2.2.Scrapy framework
2.3. Asynchronous non-blocking
- asynchronous : The call is made after , This call goes directly back to , Whether or not it turns out ; Asynchrony is a process .
- Non blocking : The concern is that the program is waiting for the result of the call ( news , Return value ) State of , Before you can get an immediate result , This call does not block the current thread .

2.4.Scrapy Components
- engine (Engine): Data flow processing for the whole system , Trigger transaction ( Framework core ).
- Scheduler (Scheduler): To accept requests from the engine , Push into queue , And return when the engine requests it again . Think of it as a URL( Grab the web address or link ) Priority queue for , It's up to it to decide what's next , Remove duplicate URLs at the same time .
- Downloader (Downloader): For downloading web content , And return the content of the web page to spider(Scrapy The Downloader is built on Twisted On this efficient asynchronous model ).
- Reptiles (Spiders):spider Is the main body of the crawler , Used to extract the information you need from a specific web page , The so-called entity (item). Users can also extract links from , Give Way Scrapy Continue to grab next page .
- The Conduit (Pipeline): Responsible for handling entities extracted from web pages by crawlers , The main function is to persist entities 、 Verify the validity of the entity 、 Clear unwanted information . When the page is parsed by the crawler , Will be sent to project pipeline , And process the data in several specific order .
- Downloader middleware (Downloader Middlewares): be located Scrapy Framework between engine and Downloader , Mainly dealing with Scrapy Request and response between engine and Downloader .
- Crawler middleware (Spider Middlewares): Be situated between Scrapy Components between engine and crawler , The main task is to deal with spider Response input and request output .
- Scheduler middlewares (Scheduler Middlewares): Be situated between Scrapy Middleware between engine and scheduling , from Scrapy Requests and responses sent by the engine to the schedule .
2.5. establish Scrapy engineering
- establish Scrapy The order of the project :scrapy startproject + < Project name >
- scrapy startproject MySprider
- Engineering structure
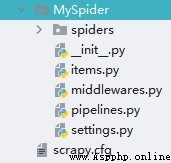
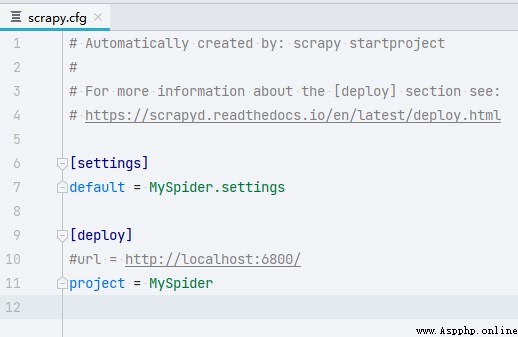
2.6. Project analysis - scrapy.cfg
- scrapy.cfg:Scrapy Project configuration file for , It defines the configuration file path of the project 、 Deploy relevant information, etc .
- settings: Global configuration files in the project .
- deploy: Project deployment configuration .
2.7. Project analysis - middlewares
- middlewares.py: It can be divided into crawler middleware and download middleware .
- MyspiderSpiderMiddleware: Crawler middleware can be customized requests Request and proceed response Filter , Generally, handwriting is not required .
- MyspiderDownloaderMiddleware Can customize the download extension , For example, setting up a proxy .
2.8. Project analysis - settings
- settings.py: The global configuration file for the project .
- Common field :
- USER_AGENT: Set up user-agent Parameters ( Default not on ).
- ROBOTSTXT_OBEY: Whether to abide by robots agreement , The default is to comply with ( Default on ).
- CONCURRENT_REQUESTS: Set the number of concurrent requests ( The default is 16 individual ).
- DOWNLOAD_DELAY: Download delay ( Default no delay ).
- COOKIES_ENABLED: Open or not cookie, That is to say, each request should be accompanied by the previous cookie( The default is on ).
- DEFAULT_REQUEST_HEADERS: Set the default request header ( Default not set ).
- SPIDER_MIDDLERWARES: Crawler middleware , The setting process is the same as the pipeline ( Default not on )
- DOWNLOADER_MIDDLEWARES: Download Middleware ( Default not on ).
- ITEM_PIPELINES: Pipe opening .
2.9. Project analysis - items,pipelines
- items.py: Definition item data structure , That is, the content you want to crawl , all item All definitions can be put here .
- pipelines.py: Definition item pipeline The implementation of is used to save data .
- Different pipeline Can process data from different reptiles , adopt spider.name Attribute to distinguish .
- Different pipeline The ability to perform different data processing operations on one or more crawlers , For example, data cleaning , One for data storage .
- process_item(self,item,spider): Realize to item Data processing .
- open_spider(self,spider): Only execute once when the crawler is on .
- close_spider(self,spider): Only execute once when the crawler is turned off .
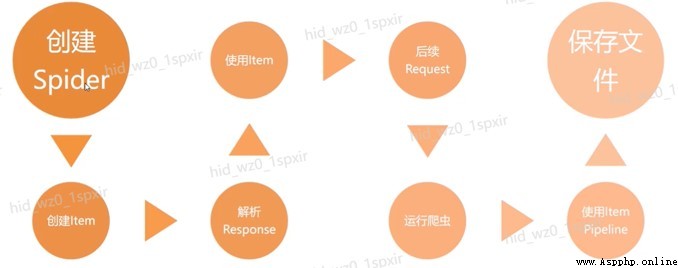
2.10.Scrapy Crawler execution process
2.11.ScrapyShell
- ScrapyShell yes Scrapy A terminal tool provided , It allows you to view Scrapy Properties and methods of objects in , And test Xpath.
- Type... On the command line :scrapy shell < Website url>, Get into Python Interactive terminal for .
- Go to the interactive command line :scrapy shell http://xxxx.xxx
- After entering the interactive command line :
- response.xpath(): Direct tests xpath Whether the rules are correct .
- response.url: Currently responding to url Address .
- response.request.url: The current response to the corresponding request url Address .
- response.headers: Response head
- response.body: Response body , That is to say html Code , The default is byte type .
- response.requests.headers: The request header of the current response .
2.12.Scrapy journal
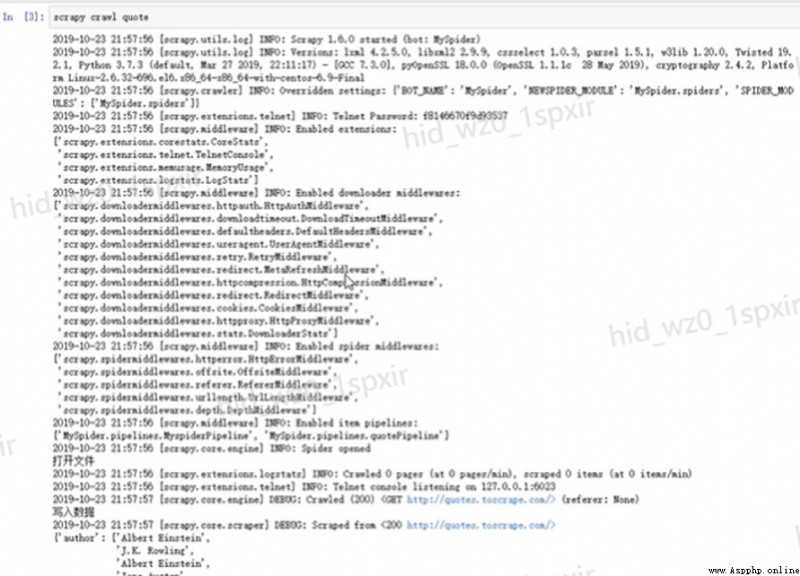
2.13.Scrapy Log parsing
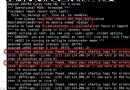
- Scrapy Some log information will be printed by default at runtime .
- [scrapy.utils.log] INFO:scrapy engineering settings Information .
- [scrapy.middleware] INFO: Extension program for project startup 、 Download Middleware 、 The Conduit .
- [scrapy.extension.telnet] DEBUG: The crawler can run with talnet Command to control .
- [scrapy.statscollectors] INFO: Some statistics at the end of the crawler .
2.14. Reptile classification
- Scrapy The crawlers in the framework fall into two categories :Spider and Crawlspider.
- Spider The design principle of the class is to only crawl start_url Pages in the list .
- Crawlspider yes Spider The derived class ( A subclass ),CrawlSpider Class defines some rules (rule) Can match the URL Address , Assemble into Request Object is automatically sent to the engine , Can also specify callback function .
2.15. establish spider
- Use command :scrapy genspider + < Reptile name > + < Domain name allowed to crawl >
- scrapy genspider baidu www.baidu.com
2.16.Spider Argument parsing
- Use the command to create spider Some code will be generated automatically :
- BaiduSpider: Current reptile class .
- name: Unique identifier of the crawler .
- allowed_domains:url Range .
- start_urls: Starting crawling url.
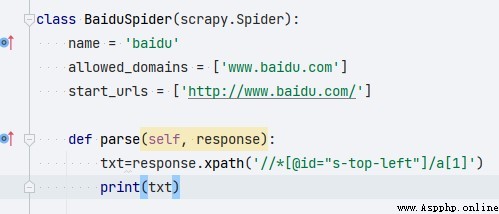
- parse: Data location .

2.17. Definition parse
parse Method defines response Processing of :
- Scrapy Medium response You can use it directly xpath Data location
2.18.Scrapy.Request
scrapy.Request(url[,callback,method=“GET”,headers,body,cookies,meta,dont_filter=False]):scrapy Class used to send requests in .
- callback: The current request url Response handler for .
- method: Appoint POST or GET request .
- headers: Receive a dictionary , It does not include cookies.
- cookies: Receive a dictionary , Special placement cookies.
- body: Receive a dictionary , by POST The data of .
- dont_filter: Filter url, Not for the requested url Ask again .
- meta: Realize data transfer in different analytic functions .
2.19. Run crawler
Execute in the project directory scrapy crawl +spider
- scrapy crawl quote
- It will print scrapy Project log for , There is no way to open the pipeline to set data processing , The crawled data will also be in the log file .
2.20.Crawlspider Crawler creation
establish crawlspider:
- scrapy genspider -t crawl Reptile name Crawling range
- scrapy genspider -t crawl crawl_baidu www.baidu.com
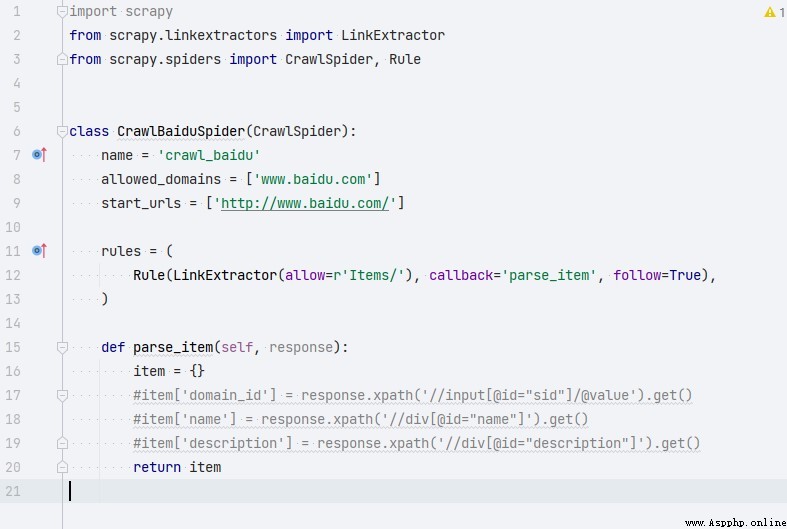
2.21.Crawlspider Argument parsing
Compared with Spider,CrawlSpider Many more rules attribute . Less parse Method .
- rules: That satisfies the matching rule url.
- Rule To express a rule .
- LinkExtractor: Connect extractor , It can be done by regularization 、xpath To match .
- callback: Represents the... Extracted by the connection extractor url Address response callback function .
2.22.Scrapy middleware
- Scrapy The main function of the middleware in is to perform some processing during the running of the crawler , For example, for non 200 Response follow-up processing of 、 When sending a request headers Fields and cookie To deal with .
- Scrapy The middleware in can be divided into two types according to their functions : Download Middleware 、 Crawler middleware .
2.23. Download Middleware
- The main function is after the request to the web page , Do some processing when the page is downloaded .
- Download Middleware Downloader Middlewares:
- process_request(self,request,spider): When each request When downloading middleware , The method is called .
- process_response(self,request,response,spider): When the Downloader is finished http request , Called when a response is passed to the engine .
2.24. Crawler middleware
- The main function is to do some processing in the process of crawler running .
- Crawler middleware Spider Middleware:
- process_spider_input: Receive one response Object and deal with .
- process_spider_exception:spider Called when an exception occurs .
2.25. Precautions for middleware use
- Scrapy The middleware in is written in the project middlewares.py In file .
- After the middleware is written, it needs to be in settings.py Open in file .
- SPIDER_MIDDLEWARES: Crawler middleware
- DOWNLOADER_MIDDLEWARES: Download Middleware