Hello everyone , I'm brother Chen ~
Share again today Pandas And SQL Comparison of .
Pandas and SQL There are many similarities , It is used to query the data of two-dimensional tables 、 Handle , Are commonly used tools in data analysis .
For only Pandas Or only SQL Friend, , You can quickly learn another from today's example .
First , Reading data
import pandas as pd
import numpy as np
tips = pd.read_csv('tips.csv')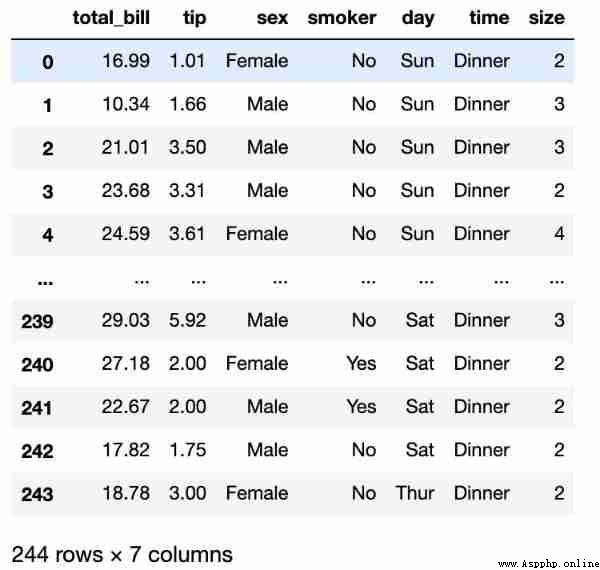
Inquire about total_bill and tip Two
tips[["total_bill", "tip"]]use SQL Realization :
select total_bill, tip
from tips; In the query results , Add a new column tip_rate
tips['tip_rate'] = tips["tip"] / tips["total_bill"]use SQL Realization :
select *, tip/total_bill as tip_rate
from tips; Inquire about time Column is equal to Dinner also tip Column greater than 5 The data of
tips[(tips["time"] == "Dinner") & (tips["tip"] > 5.00)]use SQL Realization :
select *
from tips
where time = 'Dinner' and tip > 5.00;Group and count according to a column
tips.groupby("sex").size()
'''
sex
Female 87
Male 157
dtype: int64
'''use SQL Realization :
select sex, count(*)
from tips
group by sex;Aggregate multiple values by multiple columns
tips.groupby(["smoker", "day"]).agg({"tip": [np.size, np.mean]})use SQL Realization :
select smoker, day, count(*), avg(tip)
from tips
group by smoker, day; Construct two temporary DataFrame
df1 = pd.DataFrame({"key": ["A", "B", "C", "D"], "value": np.random.randn(4)})
df2 = pd.DataFrame({"key": ["B", "D", "D", "E"], "value": np.random.randn(4)}) First use Pandas respectively inner join、left join、right join and full join.
# inner join
pd.merge(df1, df2, on="key")
# left join
pd.merge(df1, df2, on="key", how="left")
# inner join
pd.merge(df1, df2, on="key", how="right")
# inner join
pd.merge(df1, df2, on="key", how="outer")use SQL respectively :
# inner join
select *
from df1 inner join df2
on df1.key = df2.key;
# left join
select *
from df1 left join df2
on df1.key = df2.key;
# right join
select *
from df1 right join df2
on df1.key = df2.key;
# full join
select *
from df1 full join df2
on df1.key = df2.key;Stack the two tables vertically
pd.concat([df1, df2])use SQL Realization :
select *
from df1
union all
SELECT *
from df2;Stack the two tables vertically and remove the duplicate
pd.concat([df1, df2]).drop_duplicates()use SQL Realization :
select *
from df1
union
SELECT *
from df2; Yes tips in day Records with the same value in the column are recorded according to total_bill Sort .
(tips.assign(
rn=tips.sort_values(["total_bill"], ascending=False)
.groupby(["day"])
.cumcount()
+ 1
)
.sort_values(["day", "rn"])
)use SQL Realization :
select
*,
row_number() over(partition by day order by total_bill desc) as rn
from tips tday Records with the same column values will be divided into the same window , And in accordance with the total_bill Sort , The data between Windows does not affect each other , This kind of operation is called Open the window .
That's all for today . Through several simple practical cases, you can intuitively feel Pandas and SQL Similarities in data processing .
If this article is useful to you, just click Looking at Let's encourage .
- EOF -
Recommended reading Click on the title to jump to
1、 Recommend an automatic tool that is easy to use and can make money part-time - Hamibot
2、 Tencent announcement 23 Photos of the first office years ago , It's so chronological
3、 The Institute earns 20000 yuan a month , What kind of experience is it !
4、Jupyter Notebook Nanny class course
I think this article will help you ? Please share with more people
Praise and watching is the greatest support ️