Pyspark uses pandas_ UDF error: java lang.IllegalArgumentException
Pyspark uses pandas_ UDF error: java lang.IllegalArgumentException
pyspark Use pandas_udf Its a hole in my life 1. Key code :# udf using two column
 Python interview questions_ Chapter (5)
Python interview questions_ Chapter (5)
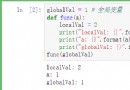
List of articles 1. How to modify global variables inside a function ① python Wh
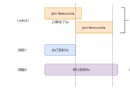
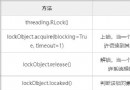 5 Python thread locks
5 Python thread locks
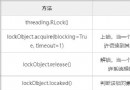
Heres the catalog title Thread safety The function of lock 1、Lock() Synchroniz
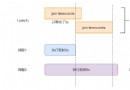 Python + threading module multi-threaded learning
Python + threading module multi-threaded learning
python Multithreading Python Threads threadingPython Multithreading for I/O inte
 OCR character recognition in Python
OCR character recognition in Python
Translating pictures into words is generally called optical character recognitio
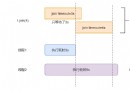 Python + Threading module Multithreading Learning
Python + Threading module Multithreading Learning
python MultithreadingPython ThreadthreadingPythonMultithreading pourI/ODensePyth
 python + threading模塊 多線程學習
python + threading模塊 多線程學習
python 多線程Python 線程threadingPython多線程適用於I/O密集型Python多線程的工作過程構造函數線程函數start()join(
 Python - file read / write
Python - file read / write
Preface Use Python When programming , I often encounter the operation of readin
Python可以不寫pass,但是要寫個字符串占位
我們知道可以寫pass來占位,如果不加pass,而是空在那裡,會報錯。if 1==1: pass print(hh) 事實上不一定要寫pass,寫個字符串(相當
Python切片步長為負時,默認從尾部開始
str1=abcd print(str1[::-3]) print(str1[-1::-1]) print(str1[::-1]) 輸出:da dcba dcb
Python含有列表的元組是不可hash的
print({ ([1,2],):3}) 輸出:Traceback (most recent call last): File XX.py, line xx,
pyspark 使用pandas_udf 報錯:java.lang.IllegalArgumentException
pyspark使用pandas_udf時的一個坑1. 關鍵代碼:# udf using two columns def prod(rating, exp): x
Python | 單下劃線和雙下劃線可訪問性
環境: Python 3.10.41. 總結先放總結單下劃線雙下劃線類屬性和方法TrueFalse子類調用父類屬性和方法TrueFalse模塊函數TrueTru
Python-文件常用函數-讀文件-寫文件-定位文件
文章目錄1.常用函數1.1.open函數1.2.讀取模式2.讀文件2.1直接打開就讀2.2.read()讀取2.3.readlines()讀取2.4.readl