WebSphere Commerce 生產環境性能管理
以 WebSphere Commerce 為核心的電子商務網站是由多種軟硬件產品共同組成的復雜系統。為了保證系統 健康地運行,運維團隊需要對整個網站做全面的性能監控,並且采取必要的主動措施以保持系統性能。本文將 介紹一些 WebSphere Commerce 電子商務網站性能監控和性能維護的最佳實踐。
WebSphere Commerce 電子商務網站的性能監控
性能監控就是通過各種監控工具了解當前應用系統運行的狀況,發現已經存在的性能問題或者可能導致性 能問題的潛在危險。性能監控工具本身作為運行的軟件也會占用系統資源,因此在選用監控工具時,要選擇對 系統影響較小的工具,並設置合適的監控級別和采樣周期,以保證既不影響應用系統的運行,又能為分析性能 問題提供足夠的數據。WebSphere Commerce 電子商務網站的性能監控根據其所監控的對象可以分為:操作系 統監控、Web 服務器監控、WebSphere 應用服務器監控和數據庫服務器監控等。
操作系統監控
操作系統資源是各種應用軟件運行的基礎,系統資源不足會嚴重影響應用軟件的性能,在生產系統運行期 間要時刻關注系統資源的使用情況。應用軟件在運行時,通常都要使用 CPU,內存和 I/O 資源,這三種資源 也是操作系統資源監控的重點。
CPU 的主要功能是解釋計算機指令以及處理計算機軟件中的數據。CPU 有 4 種運行狀態:System、User 、Wait 和 Idle。System 狀態是指 CPU 在執行操作系統的內核代碼,User 狀態是指 CPU 在執行程序代碼, Wait 狀態時 CPU 在等待 I/O 操作,而 Idle 狀態時 CPU 處於空閒狀態。電子商務網站運行時,服務器總的 CPU 占用率不宜超過 50%~70%,如果 CPU 總體使用率過高,則用戶體驗到的頁面打開時間可能受到影響。而 在各種運行狀態中,正常時應當是執行程序代碼的 User 狀態占比較高。如果 System 狀態占用率較高,說明 系統進程的工作比較繁忙,如果 Wait 占用率太高,則說明系統經常處於 I/O 等待狀態,這兩種狀態預示著 系統可能發生了某種異常。
內存用來存儲 CPU 處理的臨時數據和程序指令,起到緩沖和數據交換作用。一般地,應用服務器和數據庫 服務器都要配有充足的物理內存,並結合物理內盤的大小合理的設置 JAVA 虛擬機和數據庫服務器的最大內存 使用參數,以避免使用磁盤上的虛擬內存空間而引起性能下降。需要注意的是,操作系統會將一部分的物理內 存空間用於文件緩存,所以不能簡單地將內存占用率接近 100% 就認為內存使用出現了問題,而應當重點關注 物理內存和虛擬內存的交換情況,如果交換的頻率過高,則預示著可能出現了性能問題。
I/O 即系統的輸入輸出,包括應用程序對磁盤的讀寫、網絡傳輸及對其他外設的讀寫等。磁盤 I/O 反映 了服務器讀寫磁盤數據、寫日志等行為。網絡 I/O 反映接收請求、提供響應以及讀寫網絡資源(如遠程數據 庫)的行為。I/O 監控要同時關注 I/O 數據量和 I/O 次數,在同等大小的 I/O 數據量條件下,過於頻繁的 I/O 次數,也可能導致 I/O 資源耗盡,成為系統的瓶頸。如在監控磁盤 I/O 時,disk busy 就是一個需要關 注的重要指標。
nmon 是一種 IBM 提供的監控分析 AIX 和 Linux 操作系統資源使用的利器。在 V6 以後版本的 AIX 操作 系統已經默認安裝了 nmon 工具,推薦使用操作系統自帶的 nmon 監控操作系統資源使用。此外,IBM DeveloperWorks 上提供了多種操作系統的 nmon 工具、nmon 手冊和 nmon_analyser 分析工具等豐富的資源 可供選用。
相對於其他的操作系統資源監控工具,nmon 記錄的信息十分全面,並且提供了在交互模式 和數據收集兩種監控模式,交互模式是在 nmon 的窗口中動態地觀察監控信息的變化,常用於問題診斷;數據 收集模式則是將所有的監控信息寫入日志文件中,稍後再用 nmon_analyser 分析,適合用於日常的系統監控 和歷史趨勢分析。nmon 可以監控的系統資源使用情況主要包括以下幾方面的數據:
CPU 占用率
內存使用情況
內核統計信息和運行隊列信息
磁盤 I/O 速度、傳輸和讀 / 寫比率
文件系統的使用率
磁盤適配器使用情況
網絡 I/O 速度、傳輸和讀 / 寫比率、錯誤統計、網絡傳輸包的大小
頁面空間和頁面 I/O 速度
消耗資源最多的進程
用戶自定義的磁盤組
計算機詳細信息和資源
異步 I/O,僅適用於 AIX
工作負載管理器(WLM),僅適用於 AIX
網絡文件系統(NFS)
下文以適用於 AIX 7.1 的 nmon 版本為例,為讀者展示一些 nmon 的使用方法。
使用 nmon 交互模式監控操作系統
直接在命令行提示窗口中輸入 nmon 即可啟動交互模式。當 nmon 成功啟動後,可以執行各種單個鍵命令,實時地監控操作系統不同資源的使用情況。如鍵入 l,就可以 監視 CPU 整體占用率的情況。鍵入 c,就可以查看各個 CPU 核的占用率情況。鍵入 m,就會顯示內存的使用 情況。鍵入 d,可以查看系統磁盤的使用情況,n 可以查看網絡。如果想關掉某一項監控輸出,只需要再按一 下相應的命令符即可。使用 h 命令,可以查看到所有可用的命令符。
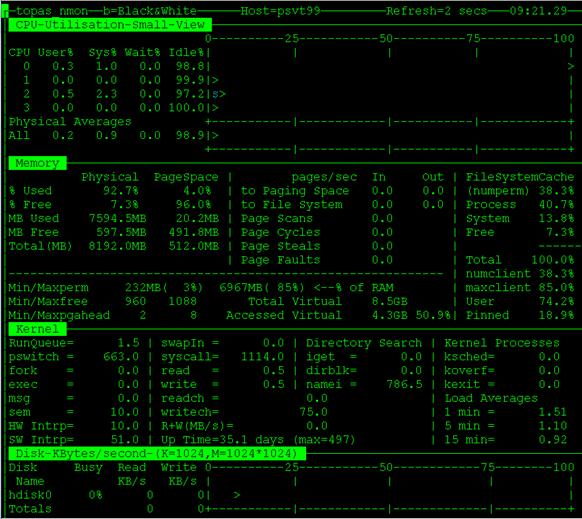
圖 1 顯示的就是 nmon 在交互 模式下的屏幕輸出,第一行顯示的是當前被監控系統的主機名和當前時間。Refresh=2 表示屏幕每 2 秒鐘刷 新一次。在 CPU 的輸出中,在右側每個 CPU 的占用率柱狀圖上,U 代表系統處於 User 狀態,S 代表系統處 於 System 狀態,W 代表 CPU 處於 Wait 狀態。左側還有數字顯示的 CPU 處於各種狀態的占用比率。在 Memory 部分的輸出中,左側的 Physical 代表物理內存,PageSpace 代表虛擬內存。中間的 pages/sec 顯示 了物理內存 RAM 和磁盤之間的交換情況,其中的 In 表示從磁盤到 RAM,Out 表示從 RAM 到磁盤。右側顯示 了在物理內存中,文件緩存 (FileSystemCache),應用程序內存 (Process),操作系統內存 (System) 和空閒 內存 (Free) 所占的比例。在磁盤信息部分顯示了磁盤的使用率,讀寫的數據量信息,其中的使用率信息 (busy) 是非常重要的性能指標,過高的使用率表示磁盤 I/O 已經成為了系統瓶頸。
圖 1. nmon 交互模式下的屏幕輸出示例
使用 nmon 數據收集模式 監控操作系統
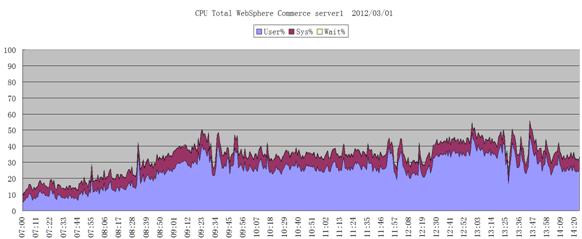
nmon 另一種運行模式是數據收集模式。用戶可以指定 nmon 運行一段時間, 並指定毎隔多長時間收集一次 nmon 數據。這些數據可以被輸出到指定文件。例如,輸入命令 nmon -f -t -s 60 -c 180,就是指將 nmon 的結果輸出到文件,每 60 秒收集一次數據,一共收集 180 次,即監控 3 個小 時,-t 表示在輸出中包含占用 CPU 資源最多的進程的信息。運行這條命令之後,用戶可以在當前目錄下找到 一個以主機名和當前時間為文件名,以 nmon 為後綴的文件。完成監控以後,可以使用 nmon_analyzer 工具 來分析輸出的 nmon 文件,它能夠將 nmon 所記錄的各項性能指標數據在時間維度上給出直觀的分析,得出圖 形化的分析結果,如圖 2 所示。有了圖形化結果的幫助,可以更方便地對性能問題進行分析診斷。
圖 2. CPU 占用率在時間維度上的 nmon 分析結果示例
由於 nmon 的數據收 集模式提供了一種信息全面,消耗較小的監控方式,建議在電子商務網站的所有服務器上都要配置 nmon 以數 據收集模式采集數據。可以使用 AIX 或 Linux 上的 cron 腳本每天啟動一個運行 24 小時的 nmon,這樣易 於後期的分析。對於使用 nmon 數據收集模式記錄的數據,要做同一時間和不同時間兩個維度比較,分析並盡 早發現問題。例如,對於使用多個磁盤存放數據的數據庫服務器,同一時間內這些磁盤的讀寫速率要基本一致 ,如果少數幾個磁盤的讀寫速率明顯高於其它磁盤,則說明數據庫的數據分布不合理,應當及時調整,以免磁 盤 I/O 成為系統瓶頸。對於不同時間數據,例如可以選取間隔 1 個月訪問量相近的兩天的數據做比較,如果 發現某種服務器資源的消耗有了較大幅度的增長,就需要分析原因,以避免系統性能進一步惡化。
應 用服務器的監控
WebSphere 應用服務器性能監控基礎結構
WebSphere Commerce 是基於 WebSphere 應用服務器的。為了監控應用服務器的整體健康狀況 ,WebSphere 提供了性能監控基礎結構 (Performance Monitor Infrastructure,簡稱為 PMI)。PMI 提供了應用服務器資源,應用資源和操作系統 關鍵資源的平均統計信息。PMI 中的性能數據可以通過 WebSphere API 實時得到,IBM 和第三方廠商基於這 些數據,開發了一些性能監控方案可供選擇。如 IBM Tivoli 性能查看器 , IBM ITCAM 等。
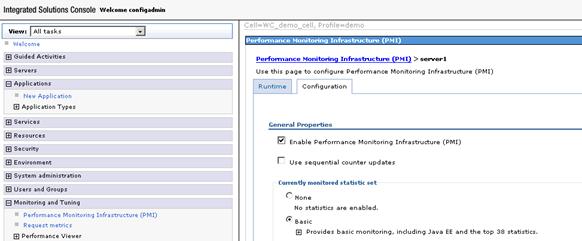
WebSphere 應用服務器中的 PMI 默認情況下是關閉的,可以在管理控制台中打開。如圖 3 所示,要 啟用 PMI,在管理控制台裡,選擇“監控和調整”->“性能監控基礎結構”,選擇服務器,然後,選中“ 啟用性能監控基礎結構”,單擊“保存”。這裡要注意各種不同的監控級別,默認為“基本”。在監控應用服 務器時,要根據實際的情況,選擇合適的監控級別。如果是對生產系統進行監控,一定要選擇少量最關心的指 標進行監控,且要通過壓力測試評估其影響。作者在壓力測試中發現,對於某些應用,在壓力較大時,“基本 ”級別的 PMI 監控也可能引發內存溢出問題,只能使用“自定義”級別且選擇少量的指標進行監控。另外需 要注意,啟用 PMI 後需要重新啟動應用服務器才能生效。
圖 3. 啟用 WebSphere 性能監控 基礎結構
Tivoli 性能查看器
PMI 收集到的數據可以通過 WebSphere 應用服務器內置的 Tivoli 性能查看器(Tivoli Performance Viewer,或簡稱 TPV)來進行分析和統計。可以從 WebSphere 應用服務器的管理控制台裡查看 Tivoli 性能查看器。如圖 4 所示,選擇“監控和調整”->“性能查看器”->“當前活動”,選中要監 控的服務器,單擊“啟動監控”,即可開始對該服務器的實時監控(前提是該服務器的 PMI 已啟用)。
圖 4. 啟動 Tivoli 性能查看器
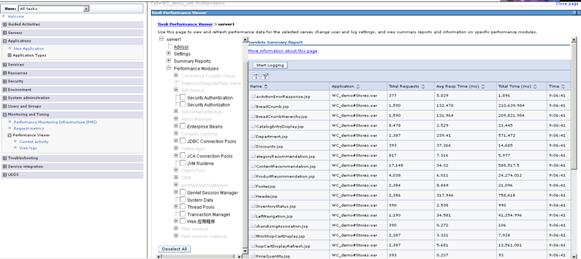
性能查看器啟動之後,單擊當前監 控的應用服務器,就可以查看該應用服務器的各種性能信息。TPV 可以通過圖形化的方式監控應用服務器內各 種資源的使用隨時間變化的情況。圖形顯示區內顯示哪些曲線可以通過在左側性能模塊列表中的選擇或取消某 些項來進行定制。
動態高速緩存監控器
動態高速緩存(Dynamic Cache)是 WebSphere 應用服務器提供的一套緩存解決方案,正確適當的使用動態緩存對提升 WebSphere Commerce 電子 商務網站的性能至關重要。前一節介紹的 TPV 也提供一些動態高速緩存的監控功能,在生產服務器上可以使 用 TPV 監控一些動態高速緩存的基本信息,比如內存中緩存條目的占用情況、緩存命中率等。在這裡,作者 要推薦使用 WebSphere 應用服務器內置的高速緩存監控器(CacheMonitor)。除了提供動態高速緩存的各種 詳細信息外,高速緩存監控器還提供對動態高速緩存的一些手工操作,比如清空緩存、使特定的緩存條目失效 等。
關於動態高速緩存監控器的使用詳情,請參見本系列中關於動態緩存的介紹文章。
數據庫 服務器的監控
當通過操作系統資源監控發現數據庫服務器的資源使用出現異常,或通過應用服務器性能監控發現數據庫 成為瓶頸時,就可以開啟數據庫服務器的性能監控器監控數據庫管理系統的工作狀態。數據庫服務器性能監控 主要考察各種數據庫內部資源(緩存、數據庫連接等)的使用情況、完成數據庫服務的各種操作(比如排序) 的執行情況,以及發現死鎖問題或者有異常的 SQL 語句。
DB2 性能監控
DB2 內置了很多性能監控工具,比如 DB2 快照監控器(Snapshot Monitor)、行為監控器 (Activity Monitor)、事件監控器(Event monitor)、健康監控器(Health Monitor)等。另外,還有一 個圖形化的健康中心。這些監控工具分別有不同的用途。其中,事件監控器根據監控事件的不同又可分為死鎖 監控器、語句監控器等。在電子商務應用的性能監控過程中,比較常用到的是快照監控器、死鎖監控器。
1 .快照監控器
DB2 提供的快照監控器是作者最常使用的監控工具。它可以在某一時刻對 DB2 的狀態做一個快照,它能夠提供在這一時刻數據庫管理系統中某個或者某些對象的狀態信息。DB2 工作的大多 數關鍵信息都可以通過快照監控器獲得。既可使用快照監控器獲取 DB2 某一時刻的工作狀態,也可以間隔一 段時間比較快照監控器獲取的快照發現某些工作狀態的變化趨勢。比如,當在 WebSphere 應用服務器的日志 中出現了死鎖引發事務回滾的異常,這個時候就可以打開快照監控器的死鎖開關,執行一次快照。從快照監控 器的輸出記錄中,可以快速查看關於鎖使用情況的各種信息。
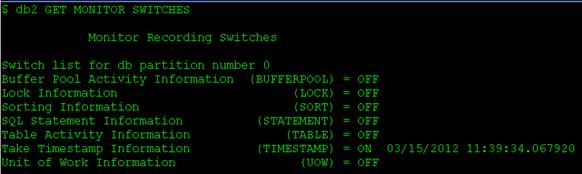
前面提到過監控級別,DB2 快照監控器 的監控級別是通過對各種監控對象的開關進行控制的。監控特定對象之前,需要把要監控對象的開關打開。用 戶可以針對 DB2 數據庫管理系統進行監控,也可以針對數據庫實例進行監控。監控對象包括緩沖池(Buffer Pool)、鎖(Lock)、排序(Sorting)、SQL 語句(SQL statement)、表動作(Table activity)、時間戳 (Timestamp)和工作單元(Unit of work)等。這些監控對象的開關可以通過如下 DB2 命令查看和打開。對 數據庫實例進行監控時,如果要查看數據庫監控對象開關狀態,可以執行 db2 GET MONITOR SWITCHES,如圖 5 所示。
圖 5. 查看數據庫監控對象開關狀態
打開指 定的數據庫監控對象開關時需要執行命令:db2 Update MONITOR SWITCHES USINGswitch- nameON/OFF。可以一次打開一個或多個開關。例如,針對數據庫打開對緩沖池和鎖的監控,可 以通過如下的命令:db2 Update MONITOR SWITCHES USING LOCK ON BUFFERPOOL ON。執行該命令之 後,再執行查看命令,就可以發現緩沖池和鎖的監控開關都已經打開了。一般來講,不管打開什麼監控對象, 推薦同時打開時間戳監控開關。打開鎖和緩沖池的開關後一段時間,執行命令:db2 GET SNAPSHOT 。就可以得到這段時間的數據庫快照,如打開了緩沖池和鎖的監控開關,就可以在快照中看到相對應的信息, 而其他未打開開關的對象則只是顯示“Not Collected”。
2 .死鎖監控器
DB2 的事件監控器 獲取的是當發生某個事件時的系統信息。這些事件包括一個事務的結束,一個 SQL 語句的完成,以及檢測到 一個死鎖等。
快照監控器只能提供關於鎖使用的基本信息,比如死鎖的數量、LOCKLIST 的使用情況等 。如果想得到死鎖比較詳細的信息,必須使用死鎖監控器。死鎖監控器是一種特殊的事件監控器,單純的死鎖 監控器只能提供關於鎖的信息,而不能提供關於使用鎖的 SQL 語句的信息,所以,作者在使用死鎖監控器的 時候通常聯合 SQL 語句監控器共同使用。與快照監控器不同,死鎖監控器不能提供某一時刻的統計信息,只 能查看某個時間間隔之內的所有事件(死鎖及其語句)。
要使用死鎖監控器,先要創建一個事件監控 器來監控語句(statements)事件和死鎖(deadlocks)事件。(在下面的步驟中,讀者需要將 dbname, username,password 替換成自己的數據庫名、用戶名和密碼)
在需要監控的時間間隔之初執行以下命 令:
db2 "connect to dbname user username using password"
db2 "create event monitor demoMon for statements, deadlocks with
details write to 'path\monitor\demoMon'"
db2 "set event monitor demoMon state=1"
demoMon 是在這個例子中要創建的時間監 控器的名字,path 是需要保存分析數據的路徑。with details 是比較重要的命令行參數,如果沒有制定這個 參數,產生的事件日志就會缺少很多信息,強烈推薦使用這個參數。該命令還可以有其他參數,比如 MAXFILES、MAXFILESIZE 等,用於控制產生的事件文件大小和數量。如果確信有足夠的磁盤空間,可以省略這 些參數。
在執行完上述的步驟後,不要關閉 DB2 命令窗口,因為在監控時間間隔結束後,還要在同一 個命令窗口執行下一組命令:
db2 "set event monitor demoMon state=0"
db2evmon – path path\monitor\demoMon > deadlocks
如果沒有在同一個命令窗口執行這兩組命令,有可能收集不到死鎖事件信息。在執行這兩組命令之間,如 果數據庫操作產生了一些死鎖,DB2 就會在 path/monitor/demoMon 下生成一組擴展名為“.evt”的文件,這 些就是事件文件。
最後一條 db2evmon 命令將這些事件文件轉換為容易讀懂的關於死鎖和語句信息的 文本信息,
Oracle 監控
Oracle 10 之後的版本新增加了性能監控工具 AWR。Oracle 的 AWR 工具提供的信息有些類似於 DB2 快照監控器提供的信息,是基於時間間隔的,在這點上又有點類似於 DB2 的 事件監控器。由於 AWR 隨產品部署而默認打開,它默認以一個小時為周期抓取系統狀態快照,使用上較為方 便。當然,AWR 也可以按需設置監控時間點。
Oracle AWR 的作用主要有兩點:第一,在 Oracle 數據 庫實例出現問題時用於發現和解決問題;第二,它可以提供 SQL 語句處理方面的統計結果,通過這些統計結 果可以得知有哪些 SQL 語句使用的頻率較高或者處理所用的時間較長,從而可以對這些 SQL 語句進行重點優 化。
設置完成之後,在需要監控的時間間隔之初,設置一個監控起始點:
sqlplus as sysdba
exec DBMS_WORKLOAD_REPOSITORY.CREATE_SNAPSHOT();
exit
在需要監控的時間間隔之末, 再設置一個監控終止點:
sqlplus as sysdba
exec DBMS_WORKLOAD_REPOSITORY.CREATE_SNAPSHOT();
exit
需要注意的是,這裡默認登錄的是 OID 變量指定的 Oracle 實例,如果讀者希望登錄指定數據庫實例,需要在啟動 sqlplus 是自行修改。為了更利 於進行性能分析,可以在性能測試或者性能問題出現前後進行多次快照的抓取。每次抓取的時候系統會指定一 個 ID,並把統計數據存在數據庫表中,之後,用戶可以指定任何兩個 ID 之間進行性能數據的輸出,系統就 會輸出在這兩個時間點之間所統計的所有數據。
需要收集監控結果的時候。執行命令:
sqlplus as sysdba
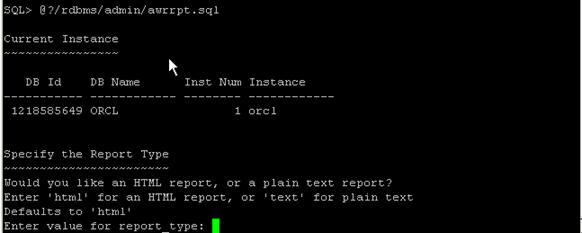
@?/rdbms/admin/awrrpt.sql
系統會有相應輸出如下:
圖 6. 選 擇收集 AWR 報告的數據庫實例
選擇正確的實例後,系統提示輸入 需要幾天內的快照檢查點
圖 7. 選擇 AWR 檢查點的時間范圍
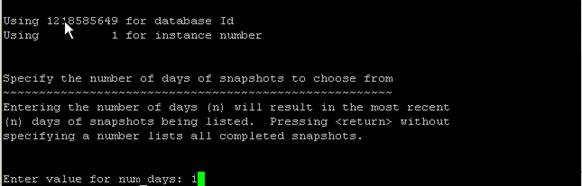
分別選擇起始和終止 的檢查點後,選擇輸出文件格式及文件名就能得到在兩個檢查點之間數據庫的狀態報告。
圖 8. 選擇 AWR 檢查點
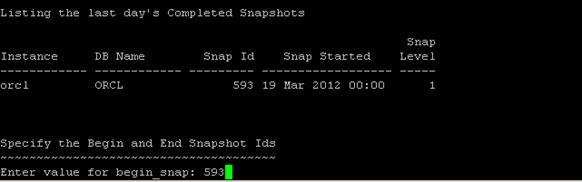
圖 9. 選擇輸出格式

圖 10. 選擇保存文件

輸出結果的第一頁是一個針對這個 數據庫實例的性能總結,包括狀態、比例和百分比。之後的每個段落提供了各個部分的性能統計的細節,包括 數據文件輸入輸出、回滾片段、系統統計、隊列、緩沖器等待和鎖信息等。因此,在進行問題診斷時,往往應 該先查看總結頁,從總結頁中發現哪些關鍵區域有問題,然後,在後面的統計細節中進行進一步的分析。對 AWR 更詳細的介紹請參考 Oracle 的相關技術資料。
WebSphere Commerce 電子商務網站的性能維護
定期的日志分析
生產環境的狀態,有一項重要信息來源就是日志分析。通過日志分析可以讓系統管理人員了解掌握系統的 運行狀態,為定制最優的性能維護計劃提供可靠保證。WebSphere Commerce 電子商務網站可供分析的日志包 括:
各服務器的監控日志
HTTP 服務器的訪問日志
應用服務器的 Java 垃圾回收日志
應用服務器的 SystemOut 和 SystemErr 日志
日志分析可以包括對日志同一時刻的分析和不同時刻的比較分析。比如 HTTP 服務器的訪問日志,其中有 一項很重要的日志項就是服務器的響應時間,可以在同一時刻中找出平均響應時間超過了標准值的頁面作為性 能問題反饋給開發人員。也可以比較一個月前後的平均響應時間變化,如果一個命令的平均響應時間增長十分 明顯,即使其還沒有超出標准值,也需要盡快分析響應時間變化的原因,在性能問題發生之前采取主動的措施 。
數據庫性能維護
在生產環境中,數據庫會隨著數據增刪查改等操作而產生數據分布變化、磁盤空間碎片、索引結構變化等 問題。數據庫需要根據表、索引和視圖的統計信息來預估不同訪問計劃的開銷,以選擇最優的訪問計劃。數據 分布的變化使數據庫中存儲的統計信息與實際的統計信息發生偏差,這些偏差會使數據庫服務器不能使用最優 化的訪問計劃查詢數據。磁盤空間碎片的產生使表和索引占據了比實際需要大的空間,查詢時數據庫也需要讀 取更多的數據頁。索引的結構會隨著數據的增加和刪除而產生過多的葉子節點和層次,數據庫在查詢索引時需 要花費更多的時間。這些問題都會引起數據庫性能的下降,而基於 WebSphere Commerce 的電子商務網站數據 庫屬於聯機交易型,數據的增刪改查非常頻繁,因此需要定期對數據庫進行維護操作,保證其運行在健康穩定 的狀態。本文以 DB2 數據庫為例,說明對電子商務網站數據庫服務器的常用維護操作。
為了能有效的 更新數據分布統計信息和檢查整理磁盤空間碎片,DB2 提供了 RUNSTATS,REORGCHK,REORG 等工具來完成這 些任務。RUNSTATS 命令用於更新數據庫表、索引和視圖的統計信息,REORGCHK 基於統計信息判斷表和索引是 否有必要做 REORG 操作,而 REOGR 命令用於完成表和索引的重新組織。根據實際經驗,對於電子商務網站的 數據庫服務器,需要每天都運行 RUNSTAT 操作,而對於 REORGCHK 和 REORG 操作,一周運行一次即可。這些 操作可以在數據庫運行時執行,但執行這些操作時,對於數據庫性能的影響比較明顯,因此應當盡量選擇電子 商城業務的低谷期,如凌晨完成這些維護操作。
理論上,需要對數據發生了很多變化的表執行 RUNSTATS 命令,但為了簡單,可以從 DB2 系統表 syscat.tables 中查出 WebSphere Commerce 用戶下所有 type 字段為 T 的表,這樣在更新統計信息時不會遺漏新增加的表。RUNSTATS 提供了不同的級別以供不同的 場景選擇,其中 WITH DISTRIBUTION AND DETAILED INDEXES ALL 是最高級別的收集。為了能在執行 RUNSTATS 時,用戶仍然可以讀寫數據庫表,需要增加 ALLOW WRITE ACCESS 選項。例如,使用以下的語句對 WebSphere Commerce 的產品屬性表收集統計信息:
db2 runstats on table WCS.ATTRIBUTE with distribution and
detailed indexes all allow write access
因為 REORGCHK 是基於統計信息的, 執行 REORGCHK 前要保證所使用的統計信息時最新的,如果執行前已經執行過 RUNSTATS,可以使用命令 db2 reorgchk current statistics on table all。如果沒有執行過 RUNSTATS,可以通過下面命令執行:db2 reorgchk update statistics on table all。 該命令可以根據系統表信息檢查所有數據庫表的空間情況。下 圖給出了一個REORGCHK的輸出例子。輸出開頭給出了三種不同的碎片標准,每個數據表的狀態,都可以通過每 行的最後一列“REORG”顯示出來,如果該表滿足某個碎片標准就會在相應位置以“*”標記出來。
圖 11. DB2 REORGCHK 輸出實例
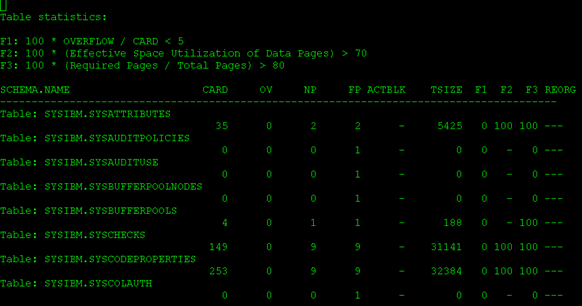
根據REORGCHK 的輸出,下一步可以 對需要做碎片整理的表和 索引執行 REORG 命令,以使數據庫表和索引回復健康的結構,如
db2 reorg TABLE WCS.ATTRIBUTE
db2 reorg indexes all for table WCS.ATTRIBUTE
之後因為數據 表被重寫,需要再次執行 RUNSTATS 更新數據統計信息。
垃圾數據清理
隨著電子商務網站運行 時間的推移,數據庫中會積累大量的運行時數據,其中很多的信息,如過期的用戶會話信息等,數據量增長得 非常快且在一定時間後就不再使用了。過快增長的無用數據,使得數據庫查詢的性能下降,備份和恢復的時間 增長,還需要消耗過量的存儲空間。對於一個業務量巨大的電子商務網站,幾個星期內所累積的運行時數據就 可能引起數據庫的性能問題。因此,需要為電子商務網站制定一個垃圾數據清理策略。
制定垃圾數據 清理策略的第一步,是要研究哪些數據表需要做清理。可以按周或者按月收集生產環境數據庫表數據量的信息 ,然後分析數據增長的速度,對其中速度增長最快的表優先進行數據清理。在理清了數據量增長最快的表後, 下一步是確認哪些數據需要保留,哪些數據可以被清理。根據在多數 WebSphere Commerce 網站運營的經驗, 以下的數據表是重點的清理對象:
ORDERS (其中 P 未定狀態的訂單,J 廢棄狀態的訂單)
MEMBER (其中 G 未注冊類型的用戶)
ADDRESS (地址表)
CTXMGMT 和 CTXDATA (用戶會話信息表)
SCHSTATUS (定時任務狀態表)
數據清理策略中非常重要的策略就是制定無效數據的保存期限,保 存期限的制定要根據數據不同的特點來制定。對於 WebSphere Commerce 運行時產生的臨時數據,如廢棄狀態 的訂單和過期的用戶會話信息,是無需保存的,當天清除即可。有一些臨時數據,如定時任務表中已經執行執 行完成或失敗的定時任務,需要保存稍長的時間如一周到一個月,以方便系統管理人員排查系統錯誤。而一些 對用戶購物可能產生影響的數據,如用戶廢棄的購物車,需要和業務人員共同商議保存多長時間。對於另外一 些數據,如用戶完成的訂單和審計信息,要轉移到備份庫以後,再實施清理。需要提醒的是,業務人員、系統 管理人員進行數據的保存期限要後,要建立文檔來管理,如果有變化也通過變更計劃管理。
WebSphere Commerce 產品提供了數據清理定時任務和 DBClean 工具來幫助系統管理員清理臨時數據,如默認開啟的 ActivityCleanUp 和 CleanJob 任務,就分別用於清理過期的用戶會話信息和執行完成的定時任務信息,和其 它的定時任務一下,系統管理員可以在同一的界面裡調節這些數據清理定時任務的執行頻率和執行時間。
DBClean 是一個更加功能強大和靈活的實用程序,可以在 WebSphere Commerce 的安裝目錄的 bin 目 錄下找到這一程序。DBClean 已經提供了一些 WebSphere Commerce 自帶數據庫表的清理腳本,例如要刪除 180 天前已取消狀態和在垃圾箱中的訂單可以執行以下的命令:
./dbclean.sh -object order -type markfordelete -instancexml
WC_installdir /instances/instance_name/xml/instance_name.xml
- db dbname -dbuser user -days 180
考慮到數據庫中可能積累了大量的待清理數據,而且數據刪除也 是比較影響數據庫性能的,DBClean 命令中有兩個可選參數,max 和 commit 可以用於調節 DBClean 的最大 刪除行數和提交頻率,以控制數據刪除執行的時間和鎖釋放的時間。commit 的默認值 1000 適合於大多數的 數據庫表,對於一些級聯關系比較少的表,為 commit 設置一個更大的值,如 5000,可以加快腳本執行的時 間。
用戶還可以通過擴展 DBClean 的方法增加對清理新增表的支持。需要注意的是,在准備好 DBClean 腳本以後,要進行功能測試,以驗證腳本能夠達到預期的清理目標。還需要進行性能測試,以驗證腳 本對數據庫性能的沖擊,和腳本是否能在數據維護窗口時間內執行完成。當數據清理腳本准備完成以後,就可 以在安裝 WebSphere Commerce 的機器上配置 cron 定時任務,定期地的清理垃圾數據了。執行垃圾數據清理 以後,通常數據庫表會發生較大的變化,建議執行 RUNSTATS 以保持數據查詢的性能。