參數優化建議
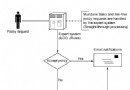
WebSphere Commerce 是基於 WebSphere 應用程序服務器開發的大型電子商務應用程序。在初次成功安裝 WebSphere Commerce 應用程序之後,安裝程序已經對服務器上的關鍵參數進行了初始化調整。這組默認值是 WebSphere Commerce 測試團隊經過反復測試總結出來的一組初始化的參數值。建議維護人員以這組默認值作 為初始值進行測試,比較測試結果與期望值的差距,從而有計劃的對應用程序服務器的部分參數進行優化。如 果您正在維護的生產環境運行正常,系統性能可以達到預期要求,我們不建議您對現有的環境進行優化。
其實調優本身並沒有一個最優解。系統是否能夠滿足客戶的需求並盡可能多的發現和解決系統存在的 隱患,很大程度上取決於維護人員的經驗。生產環境不允許做實驗,所以在測試環境上進行完整充分的測試是 非常必要的。另外生產環境和測試環境規模存在差異,在設置參數時需要考慮參數的適用性。
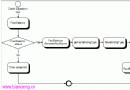
圖 1. 性能調優的生命周期
WebSphere Commerce 參數優化原理
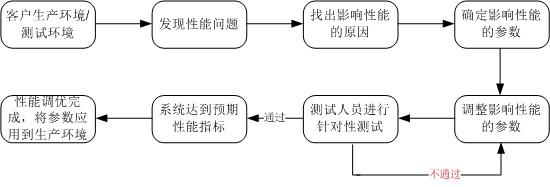
WebSphere Commerce 是一個數據庫密集型的應用程序,大多數 JSP 和 Servlet 請求都需要訪問後端 的數據庫,同時系統後台還運行著多個任務。所以它並不完全滿足漏斗模型的假設條件。在參數調優過程中可 以借鑒漏斗模型的原理,但是要針對特定部分做一些調整。
圖 2. 數據庫密集型應用程序的 參數調優模型
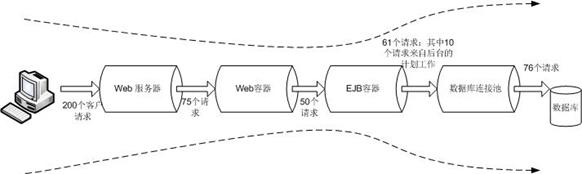
在某一特定的測試環境中,假設有 200 個並發用戶同時到達 Web 服務器,Web 服務器的並發處理能力為 75,應用程序服務器 Web 容器連接池 的值為 50,之後請求從 Web 容器到數據庫連接池的大小設置為 61,對於 WebSphere Commerce 這裡不僅需 要考慮 Web 容器處理的請求數,同時也要考慮預留一部分資源滿足後台工作的需要,其中包括:1. 後台計劃 工作 2. 管理員登錄管理控制台操作 3. 處理數據拷貝(data prop)。
* 數據庫連接池的大小 = Web 服務器轉發的客戶請求 + 後台計劃工作 (Scheduler Job) + 管理員連接後台數據庫所產生的數據庫連接請求 + 處理 data prop 的請求所需要的連接數
上面的例子說明,Web 容器和數據庫連接池的大小之間的比 例要根據具體應用程序的需求進行調整,不能盲目應用漏斗模型。
參數調優的基本原則
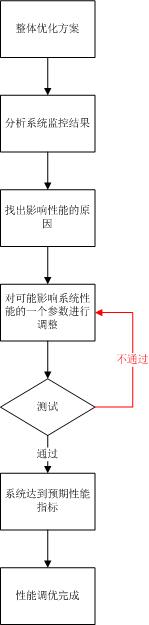
在決定進行參數調優之前,首先需要制定一份詳細的調優方案,明確調優的目標,然後根據 系統監控結果,找出可能影響系統性能的方面,嘗試在系統上每次只調整一個參數,監控系統性能指標的變化 情況,根據系統監控的結果,再做進一步調節的計劃。參數調優中最重要的原則是:每次最好只調整一個參數 。
圖 3. 參數調優流程圖
關鍵參數說明
IBM HTTP Server
建議在調整 IBM HTTP Server (IHS) 的參數之前,結合 NMON 監控數據,error_log, access_log 和 http_plugin.log 的日志信息分析性能問題的瓶頸。
參數位 置:/<WCS_ROOT>/instances/<instance_name>/httpconf/ httpd.conf 文件
假設某一測 試環境有兩台 IHS 服務器同時處理客戶請求,高峰時段預計有 7000 個並發用戶訪問,可以根據下列公式計 算 ThreadsPerChild, ServerLimit 和 MaxClients 關系:
MaxClients = ThreadsPerChild × ServerLimit
MaxClients 設定 IHS 同時處理的最大請求數,任何超出 MaxClients 限制的請求 都將放入 ListenBacklog 隊列中。ServerLimit 設定 IHS 服務器可使用的最大進程數,ThreadsPerChild 設 定每個進程中最大線程數。由於有兩台 IHS 服務器同時處理請求,所以每一台 IHS 服務器的 MaxClients 設 置為 3500,ThreadsPerChild 的默認值為 100,從而計算出 ServerLimit 的值為 35。ServerLimit 和 ThreadsPerChild 的值可以根據系統性能的要求再做調整(一般增加線程數而不是進程數,節省系統資源消耗 )。
<IfModule worker.c> ThreadLimit 25 ServerLimit 35 StartServers 1 MaxClients 3500 MinSpareThreads 25 MaxSpareThreads 75 ThreadsPerChild 100 MaxRequestsPerChild 0 </IfModule>
另外由於客戶訪問通常會有大量的 HTTP Log 寫入 error_log, access_log 文 件,頻繁對磁盤進行寫操作會降低 IO 性能,建議在 httpd.conf 中添加以下內容打開 BufferedLogs 選項。
BufferedLogs on
Web 容器線程池
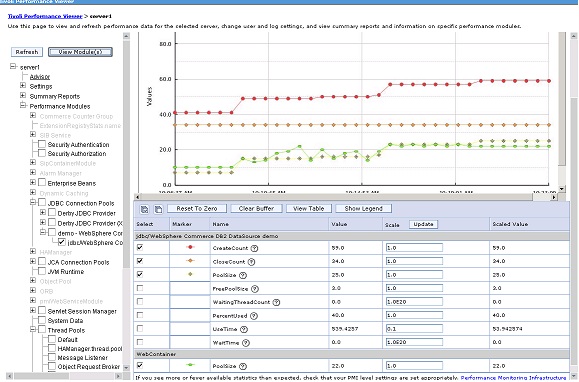
由於只有動態 Web 請求會到達應用 服務器並被 Web 容器線程池處理,建議通過 PMI/TPV 工具實時監控 Web 容器使用情況以選取合適值。
選擇“監控與調優”-> “PMI”-> 選擇指定的被監控應用服務器,在該頁面選擇打開 PMI 開 關。之後選擇“監控與調優”-> “性能查看器”-> “當前活動”-> 選擇指定的被監控應用服務器 ,先選擇指定的被監控服務器及服務器列表上方的“開始監控”項,然後選擇被監控服務器頁面,在該頁面選 擇左側“線程池”列表,並打開“Web 容器”模塊查看。可根據下面公式簡單計算所需的 Web 容器線程數量 :
到達應用服務器的動態請求總數 = Web 容器線程數 × 應用服務器實例數
圖 4. Web 容器使用情況監控圖
IBM JAVA 虛擬機
Java 虛擬機的堆大小會影響垃圾收集的行為。較大的堆會減少總體垃圾回收的次數。同時 ,較大的堆也會增加垃圾回收的時間。在 IBM Java 虛擬機中定義最大值和最小值,最大值稱為閥值,最小值 稱為初始值。當堆棧使用情況達到閥值時,將會觸發垃圾回收功能以釋放不再使用的對象所占用的內存空間, 並壓縮堆棧。一般情況下垃圾回收器工作時會停止其他操作。
在更改初始堆大小和最大堆大小之前, 應考慮以下幾點:
32 位 JVM 和 64 位 JVM 可以使用的最大堆和最小堆限制不同,32 位系統上 JVM 堆最大值為 2GB,如果 應用程序需要使用大於 2GB 的內存,那麼應該選擇在 64 位 JVM 上運行。
一般情況下,應將 JVM 最大堆大小設置為比初始堆大小更大的值。
如果不確定如何調整 JVM 堆的初始值,可以考慮將初始值大小設置為最大值的 25%。然後根據運行情況再 確定進一步調整的方案。
4. 如果需要消除 JVM 堆擴大或減小時出現的開銷,可以把 JVM 初始值和最大值 設置為相同。那麼這部分內存將被 JVM 虛擬機永久占用。 如果多個 JVM 虛擬機同時運行在一台物理機器上 ,而這台機器的物理內存又不是很充裕,從資源共享的角度出發,不建議這樣設置。
此外,基於 WAS v6.1 和 WAS v7 的 WebSphere Commerce 產品,我們還可以根據具體情況靈活運用四種 內存回收策略來提高系統的性能:
-Xgcpolicy:optthruput:默認的內存回收策略。設置此參數可以提高吞吐量,但是垃 圾回收暫停時間會延長。在垃圾回收期間,所有的應用程序處理都將被停止。
-Xgcpolicy:optavgpause:通過在應用程序執行期間並行的執行垃圾回收,從而縮短垃 圾回收暫停時間。這種方法會對應用程序的整理吞吐率有一定的影響。
-Xgcpolicy:gencon:將堆分成不同的區域,長生命周期的對象和短生命周期的對象將 分別存放在不同的區域空間中,而存放短生命周期的空間會頻繁的進行垃圾回收。從而實現高吞吐率的同時縮 短整理垃圾回收時間。WebSphere Commerce 推薦使用 gencon 作為內存回收策略。並且在 WebSphere Commerce v7 裡已經將這個參數作為默認值設置在 JVM 虛擬機的一般參數裡。
-Xgcpolicy:subpool:運用類似 optthruput 的垃圾回收策略,但在內存分配策略上更 適合多處理器的物理機器。建議在 16 個或以上處理器的機器上使用此策略提高應用程序的性能。此策略僅適 用於 IBM pSeries 和 zSeries 的機器。
在實驗室的理想情況下,我們使用相同的樣例應用程序對以上四種不同的內存回收策略進行了評估。在硬 件條件、樣例、測試方法相同的情況下,得到以下一組數據:
圖 5. 使用不同垃圾回收策略 的實驗結果
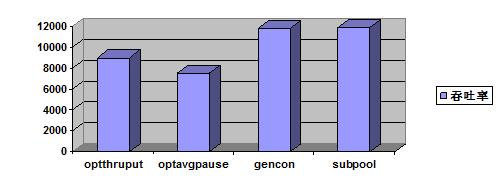
根據實驗結果不難看出,使用 gencon 和 subpool 內存回收策略對樣例應用程序進行壓力測試會得到較高的吞吐率。但 subpool 策略在使 用中一定的局限性。請根據自身應用程序的特點選擇適合的策略。
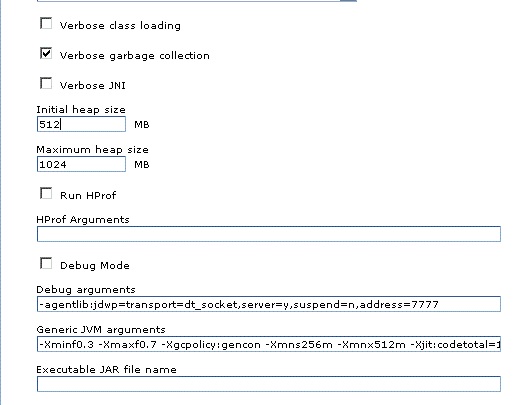
參數位置: 應用程序服務器 > server1 > 進程定義 > Java 虛擬機
圖 6. JVM 虛擬機的參數設置
IBM gencon 策略的主要原理是將內存區域劃分成兩部分,一部分是 Nursery 空間用來存放臨時對象,另一部分是 Tenured 空間用來存放持久對象。存放在 Nursery 空間的對象大多數只被使用很短的時間,收集 Nursery 空 間有利於回收 JVM 的內存空間。如果某一對象保留時間較長就會被轉移到 Tenured 空間,Tenured 空間用來 存放經常被調用的對象。如果決定采用 gencon 策略管理堆空間,需要考慮如何對堆進行合理分段。Commerce 持久數據對象存放在 Tenure 空間,因此當這部分占用越多空間,JVM 就會相應的去壓縮 Nursery 空間,導 致程序運行過程中頻繁發生垃圾回收。因此推薦根據實際需要設置一個固定大小 Nursery 空間(將最大值和 最小值設置為相同值),如果此時垃圾回收負擔仍然較高就要考慮增大堆空間大小。
如上圖所示,在 JVM 一般參數裡 -Xmns256m – Xmn512m 設置堆預留給 Nursery 的最大值和最小值。如果需要為 Nursery 設 置一個固定的值,則可以只使用 -Xmn 這個參數。根據 JVM 的最大值和 Nursery 所占用的內存空間計算出 Tenured 可以使用的內存空間大小。
Tenured 占用的內存空間 >= JVM 堆的最大值 – Nursery 的最大值
使用 gencon 作為垃圾回收策略的好處是垃圾回收時只需要檢查 Nursery 區 域,需要檢查的內存區域變小,使得回收的速度更快,JVM 處理垃圾回收而掛起的時間縮短了,因此對應用程 序的響應速度自然更快。
需要特別注意: 當 WebSphere Commerce 應用程序使用動態緩存 (DynaCache)機制時,緩存的條目都是存放在 Tenured 空間的。因為使用動態緩存機制所緩存的條目本身就 是被應用程序頻繁調用的部分。Nursery 和 Tenured 的空間分配可以根據動態緩存對象的需求做具體的調整 。
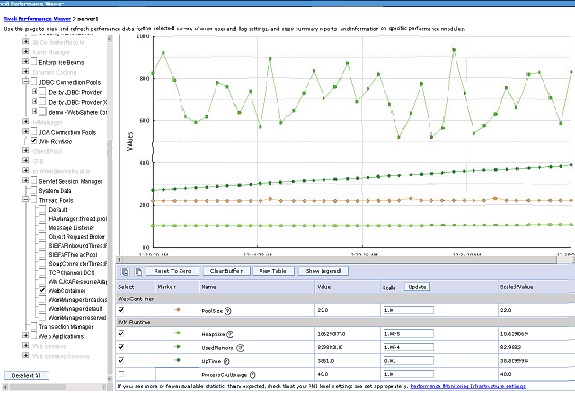
使用 Tivoli Performance Viewer 來幫助監控 JVM 垃圾回收情況和查找內存洩漏問題
圖 7. JVM 監控圖
數據庫連接池
應用程序通過數據源訪問數據庫的過程中,建立數據庫初始連 接是一個相當消耗資源的過程,數據庫連接池的最小值如果是個不為零的正數,則代表 WebSphere 應用程序 服務器啟動過程中同時創建數據庫連接。但是創建連接的過程將會延長 WebSphere 應用程序服務器的啟動時 間。將數據庫連接池的最小值設置為零或是不為零的正數,取決於客戶對應用程序的具體需求。JDBC 連接池 作為中間媒介幫助客戶更有效的使用和管理數據庫資源。在實際生產環境中,數據庫資源往往是系統性能的瓶 頸資源,如果沒有足夠的數據庫資源處理客戶請求,系統就會癱瘓。所以,數據庫連接池的作用之一是通過定 義數據庫連接池的大小限制應用程序對數據庫資源的訪問。同樣可以利用 PMI 監控其實際使用情況來確定數 據庫連接池所需最大值。
數據庫連接池大小可以按如下規則計算:
數據庫連接池最小值 = Web 容器線程池最大值 +後台計劃工作+ 1
動態緩存調優 (Dynamic Cache)
動態緩存調優主要考慮這樣幾個方面:內存占用,緩存對象大小,磁盤占用情況及 I/O 等等。其復雜之處在於緩存調優和實現代碼,緩存策略等其他方面相關,具體調整需要根據具體情況考慮 ,本文僅就上面提到的基本內容一一介紹,具體請參考第四部分 緩存設計建議,將主要介紹 WebSphere Commerce 產品中所提供的高速緩存以及最佳實踐 。
緩存對象大小計算,可以根據如下公式:
緩存對象大小 = o + c + (k × (dp + tm + 128))
- o 代表緩存數據對象大小,比如對 HTML 頁面緩存,就是 HTML 頁面內容作為字符串對象的大小。
- c 代表緩存對象 ID 的大小。動態緩存本身相當哈希表,這個 ID 相當於哈希表中的 KEY 對象。
- k 是 JVM 中存放對象引用的空間大小,對於 32 位系統為 4,對於 64 位系統為 8
- dp 表示與該緩存條目有關的 DependencyID 的數量
- tm 表示與該緩存條目有關的模板數量
動態緩存的每個實例,可以將緩存數據分別放在內存和磁盤中,磁盤作為內存中數據的擴展存儲。當一條 緩存被命中但是存放在磁盤時,會被調入內存。同樣一條緩存上時間沒有被訪問到,會被從內存調出寫入磁盤 。因此為提升緩存性能,需要考慮將緩存用到磁盤空間放置到性能良好的高速存儲中。具體調整可以打開應用 服務器控制台,在“服務器”-> “服務器類型”-> “WebSphere 應用服務器”-> 選擇指定的服務 器實例 -> “容器服務”-> “動態緩存服務”頁面。找到“磁盤緩存設置項”,這裡可以設置磁盤緩 存位置及可用空間大小。
數據庫調優建議
對於數據庫密集型的應用,數據 庫服務器的性能優劣關系到整個系統的處理能力。改善數據庫服務器的性能通常需要同時考慮硬件配置和軟件 調優兩個方面。為了提高數據庫服務器的讀寫能力,避免磁盤頻繁讀寫引起的 IO 瓶頸問題,硬件配置方面通 常將數據庫的數據文件和日志文件分別存放在不同的磁盤上。
軟件參數優化方面以 DB2 v9.7 為例對 重點參數進行介紹
內存調整
在 DB2 v9.7 上創建單分區數據庫時 會自動啟用內存自調節功能 (SELF_TUNING_MEM)。在內存自調節功能啟用的同時數據庫共享內存大小 (DATABASE_MEMORY) 、 鎖定列表的最大存儲量參數 (LOCKLIST)、 每個應用程序的鎖定百分比列表參數 (MAXLOCKS)、 程序包高速緩存大小參數 (PCKCACHESZ) 和 排序列表堆參數 (SORTHEAP) 都被設置成了 AUTOMATIC,這表明數據庫對程序包高速緩存、鎖定內存、排序內存和數據庫共享內存等參數默認啟動了自動 自調整內存功能。但是如果數據庫是從 DB2 v8 遷移到 DB2 v9 版本,自動調節功能默認是關閉的,需要手工 修改為 ON 啟動此功能。如果需要關閉內存自動調節功能可以通過設置 SELF_TUNING_MEM 為 OFF 關閉此功能 。
BUFFPAGE:數據庫中對不同的表空間和表大小,各自有對應的緩沖池,一般為使數據庫有較好性能 ,緩沖池命中率要在 95% 以上。同樣可以根據數據庫快照來計算命中率:
1 - (緩沖池物理讀次 數 / 緩沖池總讀次數)× 100%
當命中率較低時,需要增大對應緩沖池的空間。對於一個緩沖池 ,如果其參數 NPAGE 為 -1,則其大小就會有數據庫 BUFFPAGE 確定。
在環境中可以通過數據庫快照 工具來監控緩沖池命中率,建議同時打開時間戳,便於以後的日志分析和比較。
清單 1. DB2 監控命令
db2 -v update monitor switches using bufferpool on timestamp on
db2 -v reset monitor all
db2 -v get snapshot for bufferpool on {DB_NAME} > {OUTPUT_FILE_NAME}
在收集到的快照報 告文件中,查看關於緩沖池的部分。在報告文件開始部分包括緩沖池的總結部分,如下,這部分可以關注發生 數據物理讀取和邏輯讀取的比例,可以根據上面的共識計算緩沖數據命中率,如果物理讀取比例很高就說明緩 沖池數據命中率偏低,影響性能。理想的命中率應在 95% 以上。
清單 2. DB2 快照樣例 1
Buffer pool data logical reads = 5424570 Buffer pool data physical reads = 0 Buffer pool temporary data logical reads = 31477 Buffer pool temporary data physical reads = 0 Asynchronous pool data page reads = 0 Buffer pool data writes = 0 Asynchronous pool data page writes = 0 Buffer pool index logical reads = 7175690 Buffer pool index physical reads = 0 Buffer pool temporary index logical reads = 0 Buffer pool temporary index physical reads = 0 Asynchronous pool index page reads = 0 Buffer pool index writes = 0 Asynchronous pool index page writes = 0 Buffer pool xda logical reads = 0 Buffer pool xda physical reads = 0 Buffer pool temporary xda logical reads = 0 Buffer pool temporary xda physical reads = 0 Buffer pool xda writes = 0
日志讀寫調優
LOGFILSIZ:日志文件分為主日志文件 (LOGPRIMARY) 和輔助日志文件 (LOGSECOND),LOGFILSIZ 參數定義了每個主日志文件和輔助日志文件的大小。據此可以計算總的日志文件所 需空間:
日志文件大小×(主日志文件數 + 輔助日志文件數)
需要注意的是,當數 據庫啟動時,會按照上面計算所得值分配日志磁盤空間,如果空間不足,啟動將失敗。
DBHEAP: 數據 庫堆空間。日志緩沖和目錄緩存放置在這部分空間中,因此要保證該值大於 LOGBUFSZ,並預留足夠空間。其 中 LOGBUFSZ 是日志緩沖空間大小。因為每個數據庫業務都會有相應日志操作,將日志文件寫到緩沖區可以減 少日志文件寫磁盤的頻率,從而減輕其對 I/O 的壓力。可以通過監控日志存儲的 I/O 狀況來調整。當調整 LOGBUFSZ 的時候需要考慮 DBHEAP 的大小,因為 LOGBUFSZ 的空間是通過 DBHEAP 控制。
同樣可以在 前面得到的 DB2 快照工具報告中查看數據庫日志情況。主要關注日志空間使用情況,以及發生日志讀寫次數 和時間。如果讀寫頻繁並且從操作系統層面觀察到 I/O 設備繁忙,需要考慮具體原因,並適當調整 LOGBUFSZ 和 DBHEAP 參數增大日志 I/O 緩沖大小。
清單 3. DB2 快照樣例 2
Log space available to the database (Bytes)= 2759071394 Log space used by the database (Bytes) = 12608606 Maximum secondary log space used (Bytes) = 0 Maximum total log space used (Bytes) = 101891332 Secondary logs allocated currently = 0 Log pages read = 0 Log read time (sec.ns) = 0.000000000 Log pages written = 68 Log write time (sec.ns) = 0.097756512 Number write log IOs = 26 Number read log IOs = 0 Number partial page log IOs = 19 Number log buffer full = 0 Log data found in buffer = 0 Log to be redone for recovery (Bytes) = 88198974 Log accounted for by dirty pages (Bytes) = 84451194
如果日志空間放滿數據,就會碰到如下 錯誤,此時需要考慮調整日志文件大小 (LOGFILSIZ) 和日志文件個數 (LOGPRIMARY/LOGSECOND)
清單 4. 錯誤日志
QL0964C The transaction log for the database Transaction log is full. SQLSTATE=57011
數據庫鎖調優
DB2 數據庫中,為保證數據在並發訪問下的一致性,完 整性需要用鎖進行控制。每個鎖都是內存中的一個對象,需要占用一定空間。在內存中,數據庫引擎進程將所 有鎖都放到一個類似鏈表的結果中進行管理。鎖對象所能占用的數據庫內存資源是有限的,因此當這部分資源 不夠時,DB2 引擎會將多個鎖對象進行合並,稱之為鎖升級。鎖升級能夠釋放內存空間,但是可能導致更多數 據被鎖而影響並發性能,因此需要合理設置鎖相關的參數。
LOCKLIST:LOCKLIST 是存放鎖的一個列表 結構,其大小可以按如下公式計算:
LOCKLIST = 可能的鎖個數最大值 × 鎖大小 × 數據庫代理進程 數 /4096
32 位系統上鎖大小為 48 或者 96 字節。64 位系統上鎖大小為 64 或者 128 字節。鎖升級 同樣可以在前面提到的數據庫快照工具中查看。
數據庫應用程序連接數調優
MAXAPPLS: 定義可 以連接到數據庫的最大活動應用程序數。連接到數據庫的並發應用程序越多消耗的系統內存就越多。所以參數 設置是即要滿足應用程序的訪問需求,又不能無限制的增大此參數的值。可以通過下面的方法簡單估計一下該 值的大小。
最大活動應用程序 = 應用服務器實例個數×各實例數據庫連接池個數 + 數據庫後端批量 服務個數 + 數據加載工具運行實例數
下面的例子表示 MAXAPPLS 在 40 以內自動調節。
Max number of active applications (MAXAPPLS) = AUTOMATIC(40)
常用工具介紹
常用的系統監控工具:NMON
NMON 是一個實用的監控工具,適用於監控常見的 Unix 和 Linux 系統的運行情況,包括 CPU,內存,磁盤 IO 讀寫,網絡等方面的。NMON 工具是通過命令行 方式運行的。用戶可以制定每次系統信息收集的間隔和 NMON 工具運行的總時間,收集到的系統監控信息可以 轉化為 excel 電子表格,並自動生成相應的圖形,方便讀者閱讀。
常用的性能監控工 具:Tivoli Performance Viewer(TPV)
TPV 是 WebSphere Application Server v5 之 後自帶的性能監控工具,不需要單獨安裝,可以通過 WebSphere Application Server 的管理控制台啟動該監 控工具,並配置需要監控的組件。具體使用方法請參考 WebSphere Application Server 信息中心。
數據庫快照工具:DB2SNAPSHOT
該工具是隨 DB2 數據庫產品發行的一個 獲取當前數據庫統計信息的工具,具體使用方法請參考 DB2 信息中心。
小結
應用程序的性能 優化貫穿系統架構設計,應用程序開發和系統維護的整個生命周期。需要在系統設計階段就將性能優化因素考 慮在內,並將性能優化與程序開發、後期的系統維護緊密的結合起來,才能達到理想的運行結果。