IBM WebSphere Application Server V7.0 Feature Pack for Java Persistence API 2.0 新特性介紹
對象 - 關系持久化是 Java EE 應用開發中的一個重要部分。Java Persistence API (JPA) 是對象 - 關系持久化的 Java EE 標准,從 Java EE 5 開始被引入。最新的 JPA 2.0(JSR-317) 規范是 Java EE 6 標准的一部分,它引入了新的對象 - 關系持久化 API,基於 JPA 1.0/1.2 作了更進一步的擴展和提升。Apache OpenJPA 是業界領先的開源 Java 持久化框架。WebSphere Application Server 的 JPA 實現是基於 Apache OpenJPA 的。WebSphere Application Server V7.0 的 JPA 2.0 功能部件包基於 OpenJPA 2.0.0,提供了 IBM 對 JPA 2.0 規范的實現,並增加 IBM 的增強特性,使得其能與 WebSphere Application Server 更好地集成。本文將向您系統的介紹 WebSphere Application Server V7.0 中 JPA 2.0 功能部件包的新特性。
引言
對象 / 關系持久化是很多應用開發場景中非常重要的開發需求。早在 JPA 之前,Java 領域中曾湧現出很多技術方案,旨在解決數據持久化的問題,從最早的序列化(Serialization)、JDBC、關系對象映射(ORM)、對象數據庫(ODB),再到 EJB2.x、Java 數據對象(JDO)。這些方案,除 JDO 之外都有各自的局限性,JPA 很好地克服了這些局限性,是持久化方案中一個不錯的選擇。表 1 中是 JPA 與其它持久化技術的比較。
表 1. JPA 與其它持久化技術的比較
JPA 融合了上面提到的每一種持久化技術的優點。它的優勢是:
簡單易用,簡化編程。通過 JPA 創建實體如同創建序列化類一樣的簡單。與 JDO 和 EJB2.x 的實體 Bean 相比較,JPA 不受現有復雜規范的限制,能夠做到簡單易用。
JPA 支持大數據集、數據一致性、並發性和 JDBC 的查詢能力。
與對象關系軟件和對象數據庫一樣,JPA 允許使用像繼承這樣的高級面向對象技術。
需要說明的是,JPA 並不適用於所有的應用,但對於大多數應用來說,相對於其它的持久化技術,JPA 確實是一個不錯的選擇。
最初,Java™ Persistence API (JPA) 作為 Enterprise JavaBean™ (EJB) 3.0 規范的一部分被引入到了 Java Platform Enterprise Edition (Java EE) 5 中,JPA 吸取了當前 Java 持久化技術的優點,旨在規范、簡化 Java 對象的持久化工作。在 Java EE 6 中,JPA 2.0 (JSR-317) 通過提供一些重要的 API 增強了對象 / 關系映射和持久化的能力。
Apache OpenJPA 是業界領先的開源 Java 持久化框架。WebSphere Application Server 的 JPA 實現是基於 Apache OpenJPA 的。WebSphere Application Serve r 在 V6.1 版本的 EJB 3.0 功能部件包中支持 JPA 1.0 規范。WebSphere Application Server V7.0 中支持 JPA 1.2。WebSphere Application Server V7.0 的 JPA 2.0 功能部件包基於 OpenJPA 2.0.0,提供了 IBM 對 JPA 2.0 規范的實現,並增加 IBM 的增強特性,使得其能與 WebSphere Application Server 更好地集成。WebSphere Application Server 對 JPA 的支持是向前兼容的,也就是說 JPA 2.0 功能部件包同時也支持基於 JPA 1.0 和 JPA 1.2 規范開發的應用。
因為基於 OpenJPA,所以基於 OpenJPA 應用不需要做任何更改就可以運行在 WebSphere Application Server 上。此外,WebSphere Application Server 支持其與 IBM 已有特性更好地集成,包括事務、安全、集群等。您可以在 IBM 提供的 Rational Application Developer 工具中開發自己 JPA 應用。
WebSphere Application Server V7.0 JPA 2.0 功能部件包的新特性
WebSphere Application Server V7.0 的 JPA2.0 功能部件包提供了很多 JPA 2.0 的新特性,包括以下幾個方面:
O/R 映射和域模型
悲觀鎖的引入
運行時 API 的增強,EntityManagerFactory API,EntityManager API 和 Query API
通過 Criterial API 和 Metamodel 來構建基於對象的類型安全的查詢
支持 Bean Validation(JSR 303),在持久化和刪除實體時進行驗證。
下面就對以上這幾方面的新特性,進行詳細的介紹:
O/R 映射和域模型
Access Type(@Access):在 JPA1.0 中,只能在可持久化類型(實體、embeddables、MappedSuperclass)上使用 field 訪問或 propery 訪問。當使用 field 訪問時,Persistence Provider 通過反射的方式直接訪問實體的屬性。當使用 property 訪問時,Persistence Provider 能過 getter/setter 方法來訪問實體的屬性。Access 類型在 JPA2.0 中進行了擴展,它可以在每一個持久化類型上或者單獨的屬性上使用,這為實體的定義以及使用實體的相關應用都來了很大的靈活性。
清單 1. Access 舉例
Empoyee.java
@Access(FIELD)
@Entity public class Employee {
@Id
public int id;
String name;
@Access(PROPERTY)
public String getName()
…}
在 JPA1.0 中就已經有 Embeddables 類了,JPA2.0 中 Embeddables 的定義和用法在得到了擴展,使其包含了 embeddables 集合、嵌套式 embeddables 和包含與其他實體關系的 embeddables;
下面是一個 embeddables 集合的舉例。因為在數據庫表中,不可能將多個值存儲在同一行中,所以需要另外一個叫做集合表的單獨的表來存儲這些集合元素。為此,引入了 CollectionTable 注釋,每一個集合表中都有一個聯合列指向包含 embeddables 的實體表,集合表的其它列就用來存儲 embeddables 的其它屬性值。
清單 2. embeddables 集合
Address.java
@Embeddable
public class Address {
@Basic
private String street;
@Basic
private String city;
@Basic
private String state;
@Basic
private Integer zip;
public Address(){
}
//...
}
User.java
@Entity
public class User {
@Id
@GeneratedValue(strategy=GenerationType.IDENTITY)
private int id;
@ElementCollection
@CollectionTable(name="user_address")
private Set<Address> addresses = new HashSet<Address>();
public User(){
}
//...
}
JPA2.0 中新增加了嵌套式 embeddables,即某一個 Embbedable 類用來表示另一個 Embbedable 類的狀態。
清單 3. 嵌套式 embeddables
Address.java
@Embeddable
public class Address {
@Basic
private String street;
@Basic
private String city;
@Basic
private String state;
@Basic
private Integer zip;
public Address(){
}
//...
}
Phone.java
@Embeddable
public class Phone {
@Basic
private String phone_number;
@Basic
private String phone_type;
//...
}
ContactInfo.java
@Embeddable
public class ContactInfo {
public ContactInfo(){
}
@Embedded
Address homeAddress;
@Embedded
Phone homePhone;
//...
}
User.java
@Entity
public class User {
@Id
@GeneratedValue(strategy=GenerationType.IDENTITY)
private int id;
@Embedded
ContactInfo contactInfo;
public User(){
}
//...
}
包含與其它實體關系的 embeddables,因為 embeddable 類的實例本身沒有持久化標識,與引用實體的關系是與包含 embeddable 類的實體,而不是 embeddable 類本身。
清單 4. 包含與其它實體關系的 embeddables
Address.java
@Embeddable
public class Address {
@Basic
private String street;
@Basic
private String city;
@Basic
private String state;
@Basic
private Integer zip;
@ManyToOne(cascade=CascadeType.ALL)
Coordinates coordinates;
public Address(){
}
//...
}
Coordinates .java
@Entity
public class Coordinates {
@Id
@GeneratedValue(strategy=GenerationType.IDENTITY)
int id;
@Basic
double longitude;
@Basic
double latitude;
public Coordinates(){
}
public Coordinates(double lon, double lat){
longitude=lon;
latitude=lat;
}
//...
}
在 JPA1.0 中,Map 只能用來表示實體之間的關聯關系(即表之間的關系),如 @ManyToOne,@ManyToMany,而且鍵值必須是實體的屬性值。在 JPA2.0 中,Map 的鍵值還可以支持基本類型,embeddables 類,以及實體。同時引入了 @MapKeyColumn、@MapKeyClass 和 @MapKeyJoinColumn 來支持這一增強特性。
如果映射鍵值是基本類型,通過 MapKeyColumn 來指定用來映射的鍵值列。
清單 5. MapKeyColumn 舉例
@Entity
public class Employee {
@Id private int id;
private String name;
private long salary;
@ElementCollection
@CollectionTable(name="EMP_PHONE")
@MapKeyColumn(name="PHONE_TYPE")
@Column(name="PHONE_NUM")
private Map<String, String> phoneNumbers;
// ...
}
如果映射鍵值是實體,通過 MapKeyJoinColumn 來指定用來映射的鍵值列。
清單 6. MapKeyJoinColumn 舉例
@Entiy
Public class Employee{
@Id private int id;
private String name;
…
}
@Entity
public class Department {
@Id private int id;
private String name;
// ...
@ElementCollection
@CollectionTable(name="EMP_SENIORITY")
@MapKeyJoinColumn(name="EMP_ID")
@Column(name="SENIORITY")
private Map<Employee, Integer> seniorities;
// ...
}
如果在定義映射時沒有指定 Java 泛型類型,就必須使用 MapKeyClass 來指定映射鍵值的類型
清單 7. MapKeyClass 舉例
@Entity
public class Employee {
@Id private int id;
private String name;
private long salary;
@ElementCollection(targetClass=String.class)
@CollectionTable(name="EMP_PHONE")
@MapKeyColumn(name="PHONE_TYPE")
@MapKeyClass(String.class)
@Column(name="PHONE_NUM")
private Map phoneNumbers;
// ...
}
Derived Identities( 派生身份 ),它使得一個實體的 ID 能從其它實體派生出來,這提供了一種 parent-to-dependent 關系。
在下面的例子中,實體 Band 的 ID 來自於 Employee,Employee 實體就是 Parent,Band 就是 dependent。
清單 8. Derived Identities 舉例
@Entity
public class Employee {
@Id long empId;
String empName;
...
}
@Entity
Public class Band{
@Id Employee emp
…
}
Java Persistence Query language (JPQL) 擴展與增強
JPA1.0 定義了一個豐富的 Java 持久化查詢語言,可以用來查詢實體以及實體的持久化狀態。JPA2.0 又對 JPQL 進行了一些擴展,例如,可以在查詢中使用 case 表達示,在下面的例子中,使用 case 表達示來對增加員工的薪水,如果員工級別為 1. 薪水乘以 1.1,如果員工級別為 2,薪水乘以 1.05,如果員工級別為 1 和 2 以外的其它級別,. 薪水乘以 1.01。
清單 9. CASE 表達示代碼示例
UPDATE Employee e
SET e.salary =
CASE WHEN e.rating = 1 THEN e.salary * 1.1
WHEN e.rating = 2 THEN e.salary * 1.05
ELSE e.salary * 1.01
END
JPA2.0 還對 JPQL 增加了一系列新的運算符,如 NULLIF 和 COALESCE。當數據庫使用使用其它非 null 數據解碼時,NULLIF 是十分有用的。使用 NULLIF,可以在查詢語句中輕松的將非 null 值轉換成 null,如查參數與 NULLIF 相等,NULLIF 就返回 null,否則返回第一個參數的值。
清單 10. NULLIF 舉例
SELECT AVG(NULLIF(e.salary, -1))
FROM Employee e
在上面的清單中,假定員工表中薪水是一個整型數值,如果沒有薪水值,就用 -1 替代。這個查詢返回薪水的平均值。值用 NULLIF 就可通過將 -1 轉變成 null 值,來正確的忽掉不存在的薪水值。
COALESCE 運算符用返回一系列參數中第一個非 null 的值。
清單 11. COALESCE 舉例
SELECT Name, COALESCE(e.work_phone, e.home_phone) phone
FROM Employee e
在上面的清單中,假定員工表中有一列單位電話、一列家庭電話,沒有的電話號碼用 null 來表示。上面查詢返回員工姓名和員工的電話。COALESCE 運算符指定返回單位電話,如果單位電話為 null,則返回家庭電話。如果兩者都為 null,則返回 null。
JPA2.0 還增加了其它的運算符 INDEX,TYPE,KEY,VALUE 和 ENTRY。INDEX 運算符是在指定在有序列表進行有序查詢。TYPE 運算符選擇實體類型,並且可以將查詢限制到一個或多個實體類型。KEY,VALUE 和 ENTRY 運算符是 JPA2.0 泛化映射功能的一部分,可以用 KEY 來抽取映射的鍵值,VALUE 來抽取映射的值,ENTRY 就來選取映射的元素。
除此之外,JPA2.0 還為選擇列表,集合參數值以及非多態查詢增加了運算符。
悲觀鎖的引入
JPA2.0 的另外一個亮點,就是引入了 pessimistic LockManager。JPA1.0 只支持樂觀鎖,可以通過 EntityManager 類的 lock()方法指定鎖模式的值,可以是 READ 或 WRITE。樂觀讀鎖,確保在實體的狀態從數據庫中讀出來之後,只在沒有中間插入的其它事務更改了與這個實體對應的數據庫記錄的情況下,才把更新後的實體狀態寫回數據庫。它確保對數據的更新和刪除與數據庫的當前裝態保持一致,並且不會丟失中間的修改。樂觀寫鎖就是在樂觀讀鎖的基礎上必須強制對實體的版本字斷做一個更新(增量)。
JPA2.0 有 6 種新的鎖模式,其中 3 種是悲觀鎖,2 種是樂觀鎖,還有一種鎖模式是無鎖。
新增的 3 個悲觀鎖模式:
PESSIMISTIC_READ:只要事務讀實體,實體管理器就鎖定實體,直到事務完成鎖才會解開,當想保證數據在連續的讀之間不被修改時,就可以使用這種鎖模式,即這種鎖模式不會阻礙其它事務讀取數據。
PESSIMISTIC_WRITE:只要事務更新實體,實體管理器就會鎖定實體,這種鎖模式強制嘗試修改實體數據的事務串行化,當多個並發更新事務出現更新失敗幾率較高時使用這種鎖模式。
PESSIMISTIC_FORCE_INCREMENT:當事務讀實體時,實體管理器就鎖定實體,當事務結束時會增加實體的版本屬性,即使實體沒有修改。
JPA 2.0 也提供了多種方法為實體指定鎖模式,可以使用 EntityManager 的 lock() 和 find() 方法指定鎖模式。此外,EntityManager.refresh() 方法可以恢復實體實例的狀態。
清單 12. 悲觀鎖示例
// read
Part p = em.find(Part.class, pId);
// lock and refresh before update
em.refresh(p, PESSIMISTIC_WRITE);
int pAmount = p.getAmount();
p.setAmount(pAmount - uCount);
上面示例代碼裡,首先讀一些數據,然後在更新數據之前,通過調用 EntityManager.refresh() 方法來使用 PESSIMISTIC_WRITE 鎖。PESSIMISTIC_WRITE 在事務更新數據時鎖定實體,這樣其它的事務在初始事務提交之前不能更新同一實體。
運行時 API 更新
EntitiyManagerFactory API,增加了對 L2 緩存,Properties,Criteria API 和 Metamodel AP I 的支持;
EntityManager,新增對 Query API,Query Result API,Hits,Properties,LockModeType,以及 Detach 的支持;
Query API,新增了方法用來獲取 typed query 參數和結果,支持實時 Hints,以及鎖的 getter/setter 方法;
通過 Criteria API 構建查詢
JPA2.0 中一個重大的新特性就是引入 Metamodel 和 Criterial API 的組合。Criterial API 是用來動態構建基於對象的查詢的一套 API。本質上講,Criterial AP I 就是 JPQL 的面象對向的等價物。通過 Criterial API,就可以基於對象的方式來創建查詢,而不是像 JPQL 那樣通過字符串來創建查詢語句。
Criterial API 基於 metamodel,metamodel 為持久化單元所管理的類提供了一個 schema 級的抽象模型。通過 metamodel 可以構建強類型的查詢,可以查詢持久化單元的邏輯結構。
JPA1.0 引入了 JPQL 查詢語言,這在很大程度上推動了 JPA 的流行,但是這種基於符串並使用有限語法的 JPQL 存在一些缺陷。請看下面一段簡單的代碼示例,使用 JPQL 來查詢年薪大於 20 萬元的 Employee 列表
清單 13. 簡單的 JPQL 查詢語句
EntityManager em = ...;
String jpql = "select e from Employee where e.salary > 2000000";
Query query = em.createQuery(jpql);
List result = query.getResultList();
JPQL 查詢被指定為一個字符串,EntityManager 構建一個包含 JPQL 字符串的查詢實例,然後查詢結果是一個無類型的 java.util.List。
但是這個例子中有一個驗證錯誤,該代碼能夠通過編譯,但是運行時會失敗,因為 JPQL 查詢字符串中有語法錯誤。
清單 14. 正確的查詢語
String jpql = "select e from Employee e where e.salary > 2000000";
使用 Criteria API 可以避免這種構造查詢語句時的語法錯誤。
清單 15. 使用 Criteria API 的查詢
EntityManager em = ...
QueryBuilder qb = em.getQueryBuilder();
CriteriaQuery<Employee> c = qb.createQuery(Employee.class);
Root< Employee> e = c.from(Employee.class);
Predicate condition = qb.gt(e.get(Employee_.salary), 2000000);
c.where(condition);
TypedQuery< Employee> q = em.createQuery(c);
List< Employee> result = q.getResultList();
上面的代碼展示了 Criteria API 的核心構造和基本使用。首先獲取一個 EntityManager 實例,然後創建一個 QueryBuilder 的實例。QueryBuilder 是 CrtieriaQuery 的工廠,它用來構建 CrtieriaQuery 實例,在 CrtieriaQuery 實例上設置查詢表達式。Root<Employee> 是泛型的,類型參數是表達示要計算的值的類型。QueryBuilder 還用來構建查詢表達示 Predicate condition = qb.gt(e.get(Employee_.salary), 2000000),這個方法顯示了使用強類型語言定義能檢查正確性的 API 的一個不錯的例子。因為每個查詢表達款都是泛型的,並且 API 中類型安全繼承,編譯器會對無意的比較拋出錯誤,比如:Predicate condition = qb.gt(p.get(Employee_.salary, "xyz"));TypedQuery 結果具有相同的 Employee.class 類型,因些最終查詢結果也是帶有類型 Employee 的列表,這可以省去開發人員在遍歷生成的元素時進行強制轉換的操作,減少了 ClassCastException 運行時錯誤的產生。
在清單 7 中,有一個 Employee_.salary 這樣的構造,它是表示 Employee 的持久化屬性 salary。Employee_.salary 是 Employee_ 類中的公共靜態字段,Employee_ 是靜態、已實例化的規范 metamodel 類,對應於原來的 Employee 實體類。
Metamodel 描述持久化類的元數據。如果一個類按著 JPA2.0 規范精確地描述持久化實體的數據,這個元模型就是規范的,規范的元模型類是靜態的,因些它所有的成員變理都被聲明成靜態的。
清單 16. 持久化實體示例
@Entity
public class Employee {
@Id
private long ssn;
private string name;
private int age;
private float salary;
// public gettter/setter methods
public String getName() {...}
}
清單 17. Employee 對應的靜態規范 metamodel 類
import javax.persistence.metamodel.SingularAttribute;
@javax.persistence.metamodel.StaticMetamodel(Employee.class)
public class Employee_ {
public static volatile SingularAttribute< Employee,Long> ssn;
public static volatile SingularAttribute< Employee,String> name;
public static volatile SingularAttribute< Employee,Integer> age;
public static volatile SingularAttribute< Employee,Float> salary;
}
前面提到 Criteria API 是強類型的,Criteria API 也是一種動態創建查詢的機制。它可以通過以下幾種方式來動態創建查詢 :
以弱類型的方式動態構建查詢;
以數據庫內置的函數作為查詢表達式擴展語法;
在結果集中再查詢;
根據模板進行查詢。
接下來分別舉例說明:
以弱類型的方式動態構建查詢
Criteria API 的強類型檢查要求實列化元模型,這通常只能在開發階段實現。但是有些時候,實體是在運行時被動態選定的。Criteria API 還提供了另外一種方式,也就是通過屬性的名字來訪問實體的屬性。
清單 18. 弱類型查詢舉例
Class<Employee> cls =Class.forName("Employee");
Metamodel model = em.getMetamodel();
EntityType<Employee> entity = model.entity(cls);
CriteriaQuery<Employee> c = cb.createQuery(cls);
Root<Employee> emp = c.from(entity);
Path<Integer> age = account.<Integer>get("age");
c.where(cb.gt(age),50);
以數據庫內置的函數作為查詢表達式擴展語法
動態查詢機制的一個亮點就是其語法可以擴展。通過使用 QueryBuilder 接口的 function() 方法來創建數據庫支持的表達式。
<T> Expression<T> function(String name, Class<T> type, Expression<?>...args);
訪函數用於創建一個給定名稱帶有零個或多個表達式參數的表達式。應用可以通這個表達式來調用數據庫函數來進行查詢。例如 CURRENT_USER() 這是一個 MySQL 的內置函數用來返回用戶名和主機名的 UTF-8 字符串。
清單 19. CriteriaQuery 中使用數據庫內置於函數
CriteriaQuery<Tuple> q = cb.createTupleQuery();
Root<Employee> c = q.from(Employee.class);
Expression<String> currentUser =
cb.function("CURRENT_USER", String.class, (Expression<?>[])null);
q.multiselect(currentUser, c.get(Employee_.Name));
在結果集中再查詢
CrtiteriaQuery 可以以編程的方式來編輯。像選擇條件,WHERE 子句中的選擇謂詞,以及 OrderBy 子句的排序條件等都可通被編輯,以達到在結果集中進行搜索功能。
清單 20. 結果集再查詢舉例
CriteriaQuery<Employee> c = cb.createQuery(Employee.class);
Root<Employee> p = c.from(Employee.class);
c.orderBy(cb.asc(p.get(Employee_.name)));
List<Employee> result = em.createQuery(c).getResultList();
// start editing
List<Order> orders = c.getOrderList();
List<Order> newOrders = new ArrayList<Order>(orders);
newOrders.add(cb.desc(p.get(Employee_.zipcode)));
c.orderBy(newOrders);
List<Employee> result2 = em.createQuery(c).getResultList();
根據模板進行查詢
Criteria API 通過創建模板,並根據模板來進行查詢。有了給定的模板實例之後,將創建一個聯合謂詞,其中每個謂詞都是模板實例的非 null 和非默認屬性值。執行該查詢將計算謂詞以查找所有與模板實例匹配的實例。
清單 21. 模板查詢舉例
CriteriaQuery<Employee> q = cb.createQuery(Employee.class);
Employee example = new Employee();
example.setSalary(10000);
example.setRating(1);
q.where(cb.qbe(q.from(Employee.class), example);
如上面例子所示,OpenJPA 的 QueryBuilder 接口擴展支持以下表達式:
public <T> Predicate qbe(From<?, T> from, T template);
如這這個表達式根據給定模板實例的屬性值生成一個聯合謂詞。例如,這個查詢將查詢所有薪水為 10000 評級為 1 的 Employee。
Bean Validation
JPA2.0 引入 Bean Validation,Bean Validation 是由 JSR 303 規范來定義的。JPA2.0 支持通過 JSR 303 的實現在實體持久化和刪除操作之前來對實體進行驗證。
清單 22. Bean Validation 舉例
@Embeddable
public class Author {
private String firstName;
@NotEmpty(message="lastname must not be null")
private String lastName;
@Size(max=30)
private String company;
...
}
@Entity
public class Book {
@NotEmpty(groups={FirstLevelCheck.class, Default.class})
private String title;
@Valid
@NotNull
@Embedded
private Author author;
...
}
性能增強
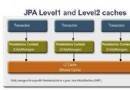
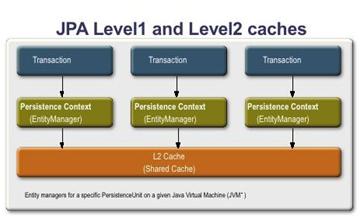
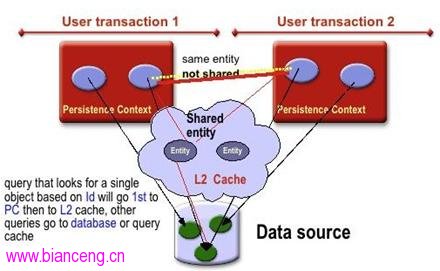
JPA2.0 的另一更新就是引入的 L2 緩存。JPA 中有兩個級別的緩存:第一級是持久化上下文,在一個持久化上下文中,Entity Manager 會確保唯一的實體實例對應一個特定的數據庫行。第二級緩存(L2)是在多個上下文之間共享實體的狀態。在 JPA1.0 中,並沒定義支持第二級的緩存。
如果啟用 L2 緩存的話,在持久化上下文中找不到的實體,就會從 L2 緩存中找,如果找到,就會從 L2 緩存中裝載。這一行為,通過 CacheModes 和緩存元素來控制。
圖 1. JPA 的第一級與第二級緩存
使用 JPA2.0 的 L2 緩存的好處:
對於已經裝載的實體,可以避免對數據庫的再次訪問;
可以快速讀取頻繁訪問的未改變的實體。
就像一枚硬幣有正面,也有反正一樣,L2 緩存存在著缺點:
大量的實體對象會帶來內存的消耗;
更新對象後會來陳舊的數據;
可會出現同時寫操作;
對於頻繁同時更新的實體會帶來擴展性方面的問題
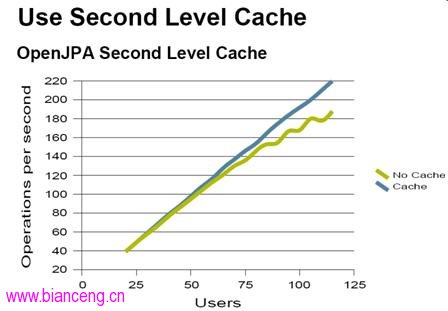
但是緩存卻是 Java EE 方面有效的提高性能的設計模式,下面的圖表明,隨著用戶的增加,L2 緩存所帶來的性能的提高。
圖 2. L2 緩存性能提示例
WebSpehere Application Server 對 OpenJPA 的擴展與增強
WebSphere 的 JPA 解決方案基於 OpenJPA,但是同時還對 OpenJAP 進行了擴展,包括了與 IBM Data Studio Pure Query 的集成和 WebSphere eXtreme Scale 集成。
圖 3. WebSphere JPA 架構

JPA2.0 功能部件包與 IBM Data Studio Pure Query 的集成
IBM pureQuery 是一個高性能的 Java 數據訪問平台,可以簡化數據訪問的開發,優化,保護和管理。PureQuery 提供一可以用來替代 JDBC 的 API 來訪問數據庫。
JPA 使用 pureQuery 的靜態 SQL,SQL 監視和問題診斷以及異構環境下批處理更新操作。
與 JPA 功能部件集成在一起的 pureQury,允許其它數據庫(如 Oracle)使用 wsdb2gen 功能,使用 pureQuery 的 sql 監控和問題診斷功能,這樣可像 DB2 用戶一樣來調優應用的 SQL 使用。同時它也允許其它的 DBRA 數據庫(如 Informix)用戶使 heterogeneous batching support,這使得他們體驗到像 DB2 用戶一樣性能特性。
JPA2.0 功能部件包與 WebSphere eXtreme Scale 的集成
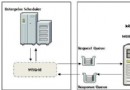
在了解 IBM WebSphere eXtreme Scale 之前,我們簡單介紹下延遲寫緩存系統。緩存系統是位於數據庫和應用數據訪問之間的中間系統,對於一個延遲寫緩存,寫操作不會立即反應到存儲庫中,緩存會將被更新的數據標記為髒數據,只有在數據因為某些原因(如更新機制)被從緩存中移除的時候,寫操作才會在存儲庫上執行。因此,如果在一個延遲寫緩存上產生一個讀取失敗時,會激發兩個動作:一個線程到存儲庫獲取數據,一個線程將緩存中的髒數據更新到存儲庫(用於釋放空間留給新的數據)。當然,可以顯式的要求緩存將髒數據更新到存儲庫。下圖顯示了延遲寫緩存系統所處的地位和工作流程。
圖 5. 延遲寫緩存系統所處的地位和工作流程
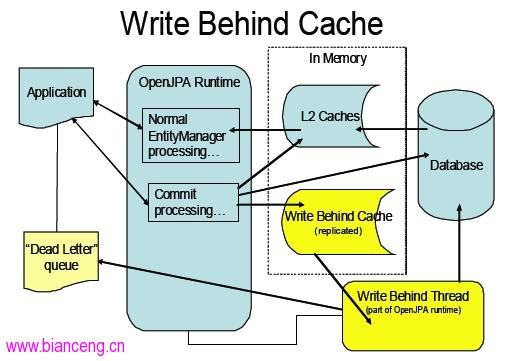
緩存系統的優點是能夠顯著提高系統事務率(Transactions Per Second, TPS),同時數據庫負載降低,但對於 server 而言,需要增加額外的內存消耗,並且需要增加額外線程。
使用外部的數據緩存系統能夠給 JPA 數據訪問操作性能帶來大幅度提升,下面我們以 IBM WebSphere eXtreme Scale(以下簡稱 WXS) 為例,介紹如何配置 OpenJPA 上的外部緩存。
OpenJPA 提供多種緩存機制,如 DataCache 和 QueryCache,DataCache 表示對數據進行緩存,QueryCach e 表示對查詢結果進行緩存,它們都可以通過在 persistence.xml 中的配置進行啟用 / 停止,可選值為 true、false 或第三方實現類路徑,同時可以設置相應參數。簡單的情況下,可以使用
<property name="openjpa.DataCache" value="true"/>
表示啟用數據緩存。
還可以在 value 處配置相應參數,如
<property name="openjpa.DataCache" value="true(CacheSize=10000)"/>
用於指定緩存數據量大小。
WXS 提供了專門支持 OpenJPA DataCache 和 QueryCache 的實現,在 persistence.xml 中使用如下配置,即可啟用 WXS 針對 OpenJPA 的 QueryCache 緩存實現
<property name="openjpa.QueryCache" value="com.ibm.websphere.objectgrid.openjpa.ObjectGridQueryCache()"/>
對於一般情況而言,只需做出上述配置,即可滿足系統需求,但在一些需要特殊定制的環境中,WXS 也提供了增強的擴展配置方式,即在 META-INF 目錄下,使用自定義的 OpenJPA ObjectGrid XML 豐富擴展配置。有以下三類配置文件類型可以供用戶使用:openjpa-objectGrid.xml ( ObjectGrid 配置文件 ), openjpa-objectGridDeployment.xml ( 部署策略配置 ),和 openjpa-objectGrid-client-override.xml ( 客戶端的 ObjectGrid 覆蓋配置 ),用戶可以根據需求使用任何一個或全部配置文件。
對於 EMBEDDED 和 EMBEDDED_PARTITION 類型,可以根據需求使用任何一個或全部配置文件
對於 REMOTE ObjectGrid 緩存而言,ObjectGrid cache 不會創建動態 ObjectGrid,而是從 catalog service 獲取客戶端的 ObjectGrid,因此此時用戶只能配置 openjpa-objectGrid-client-override.xml 來覆蓋原有配置。如果希望進一步了解 WebSphere eXtreme Scale 的詳細信息,請參考 WebSphere eXtreme Scale 相關文章。
結束語
JPA2.0 規范使得 EJB 中實體 bean 的開發變得更加簡單,靈活。本文介紹了 JPA2.0 功能部件的最主要的幾個新特性。需要注意的是 JPA 2.0 功能部件包是同 OSGi 應用功能部部件包一起發布的並且可以同時安裝的,但是二者之間沒有必然的聯系,也可以進行單獨安裝。