HashMap也是我們使用非常多的Collection,它是基於哈希表的 Map 接口的實現,以key-value的形式存在。在HashMap中,key-value總是會當做一個整體來處理,系統會根據hash算法來來計算key-value的存儲位置,我們總是可以通過key快速地存、取value。下面就來分析HashMap的存取。
HashMap實現了Map接口,繼承AbstractMap。其中Map接口定義了鍵映射到值的規則,而AbstractMap類提供 Map 接口的骨干實現,以最大限度地減少實現此接口所需的工作,其實AbstractMap類已經實現了Map,這裡標注Map LZ覺得應該是更加清晰吧!
public class HashMap<K,V>
extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable
HashMap提供了三個構造函數:
HashMap():構造一個具有默認初始容量 (16) 和默認加載因子 (0.75) 的空 HashMap。
HashMap(int initialCapacity):構造一個帶指定初始容量和默認加載因子 (0.75) 的空 HashMap。
HashMap(int initialCapacity, float loadFactor):構造一個帶指定初始容量和加載因子的空 HashMap。
在這裡提到了兩個參數:初始容量,加載因子。這兩個參數是影響HashMap性能的重要參數,其中容量表示哈希表中桶的數量,初始容量是創建哈希表時的容量,加載因子是哈希表在其容量自動增加之前可以達到多滿的一種尺度,它衡量的是一個散列表的空間的使用程度,負載因子越大表示散列表的裝填程度越高,反之愈小。對於使用鏈表法的散列表來說,查找一個元素的平均時間是O(1+a),因此如果負載因子越大,對空間的利用更充分,然而後果是查找效率的降低;如果負載因子太小,那麼散列表的數據將過於稀疏,對空間造成嚴重浪費。系統默認負載因子為0.75,一般情況下我們是無需修改的。
HashMap是一種支持快速存取的數據結構,要了解它的性能必須要了解它的數據結構。
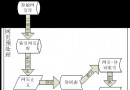
我們知道在Java中最常用的兩種結構是數組和模擬指針(引用),幾乎所有的數據結構都可以利用這兩種來組合實現,HashMap也是如此。實際上HashMap是一個“鏈表散列”,如下是它數據結構:

從上圖我們可以看出HashMap底層實現還是數組,只是數組的每一項都是一條鏈。其中參數initialCapacity就代表了該數組的長度。下面為HashMap構造函數的源碼:
public HashMap(int initialCapacity, float loadFactor) {
//初始容量不能<0
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: "
+ initialCapacity);
//初始容量不能 > 最大容量值,HashMap的最大容量值為2^30
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
//負載因子不能 < 0
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: "
+ loadFactor);
// 計算出大於 initialCapacity 的最小的 2 的 n 次方值。
int capacity = 1;
while (capacity < initialCapacity)
capacity <<= 1;
this.loadFactor = loadFactor;
//設置HashMap的容量極限,當HashMap的容量達到該極限時就會進行擴容操作
threshold = (int) (capacity * loadFactor);
//初始化table數組
table = new Entry[capacity];
init();
}
從源碼中可以看出,每次新建一個HashMap時,都會初始化一個table數組。table數組的元素為Entry節點。
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;
final int hash;
/**
* Creates new entry.
*/
Entry(int h, K k, V v, Entry<K,V> n) {
value = v;
next = n;
key = k;
hash = h;
}
.......
}
其中Entry為HashMap的內部類,它包含了鍵key、值value、下一個節點next,以及hash值,這是非常重要的,正是由於Entry才構成了table數組的項為鏈表。
上面簡單分析了HashMap的數據結構,下面將探討HashMap是如何實現快速存取的。
首先我們先看源碼
public V put(K key, V value) {
//當key為null,調用putForNullKey方法,保存null與table第一個位置中,這是HashMap允許為null的原因
if (key == null)
return putForNullKey(value);
//計算key的hash值
int hash = hash(key.hashCode()); ------(1)
//計算key hash 值在 table 數組中的位置
int i = indexFor(hash, table.length); ------(2)
//從i出開始迭代 e,找到 key 保存的位置
for (Entry<K, V> e = table[i]; e != null; e = e.next) {
Object k;
//判斷該條鏈上是否有hash值相同的(key相同)
//若存在相同,則直接覆蓋value,返回舊value
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value; //舊值 = 新值
e.value = value;
e.recordAccess(this);
return oldValue; //返回舊值
}
}
//修改次數增加1
modCount++;
//將key、value添加至i位置處
addEntry(hash, key, value, i);
return null;
}
通過源碼我們可以清晰看到HashMap保存數據的過程為:首先判斷key是否為null,若為null,則直接調用putForNullKey方法。若不為空則先計算key的hash值,然後根據hash值搜索在table數組中的索引位置,如果table數組在該位置處有元素,則通過比較是否存在相同的key,若存在則覆蓋原來key的value,否則將該元素保存在鏈頭(最先保存的元素放在鏈尾)。若table在該處沒有元素,則直接保存。這個過程看似比較簡單,其實深有內幕。有如下幾點:
1、 先看迭代處。此處迭代原因就是為了防止存在相同的key值,若發現兩個hash值(key)相同時,HashMap的處理方式是用新value替換舊value,這裡並沒有處理key,這就解釋了HashMap中沒有兩個相同的key。
2、 在看(1)、(2)處。這裡是HashMap的精華所在。首先是hash方法,該方法為一個純粹的數學計算,就是計算h的hash值。
static int hash(int h) {
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
我們知道對於HashMap的table而言,數據分布需要均勻(最好每項都只有一個元素,這樣就可以直接找到),不能太緊也不能太松,太緊會導致查詢速度慢,太松則浪費空間。計算hash值後,怎麼才能保證table元素分布均與呢?我們會想到取模,但是由於取模的消耗較大,HashMap是這樣處理的:調用indexFor方法。
static int indexFor(int h, int length) {
return h & (length-1);
}
HashMap的底層數組長度總是2的n次方,在構造函數中存在:capacity <<= 1;這樣做總是能夠保證HashMap的底層數組長度為2的n次方。當length為2的n次方時,h&(length – 1)就相當於對length取模,而且速度比直接取模快得多,這是HashMap在速度上的一個優化。至於為什麼是2的n次方下面解釋。
我們回到indexFor方法,該方法僅有一條語句:h&(length – 1),這句話除了上面的取模運算外還有一個非常重要的責任:均勻分布table數據和充分利用空間。
這裡我們假設length為16(2^n)和15,h為5、6、7。

當n=15時,6和7的結果一樣,這樣表示他們在table存儲的位置是相同的,也就是產生了碰撞,6、7就會在一個位置形成鏈表,這樣就會導致查詢速度降低。誠然這裡只分析三個數字不是很多,那麼我們就看0-15。

從上面的圖表中我們看到總共發生了8此碰撞,同時發現浪費的空間非常大,有1、3、5、7、9、11、13、15處沒有記錄,也就是沒有存放數據。這是因為他們在與14進行&運算時,得到的結果最後一位永遠都是0,即0001、0011、0101、0111、1001、1011、1101、1111位置處是不可能存儲數據的,空間減少,進一步增加碰撞幾率,這樣就會導致查詢速度慢。而當length = 16時,length – 1 = 15 即1111,那麼進行低位&運算時,值總是與原來hash值相同,而進行高位運算時,其值等於其低位值。所以說當length = 2^n時,不同的hash值發生碰撞的概率比較小,這樣就會使得數據在table數組中分布較均勻,查詢速度也較快。
這裡我們再來復習put的流程:當我們想一個HashMap中添加一對key-value時,系統首先會計算key的hash值,然後根據hash值確認在table中存儲的位置。若該位置沒有元素,則直接插入。否則迭代該處元素鏈表並依此比較其key的hash值。如果兩個hash值相等且key值相等(e.hash == hash && ((k = e.key) == key || key.equals(k))),則用新的Entry的value覆蓋原來節點的value。如果兩個hash值相等但key值不等 ,則將該節點插入該鏈表的鏈頭。具體的實現過程見addEntry方法,如下:
void addEntry(int hash, K key, V value, int bucketIndex) {
//獲取bucketIndex處的Entry
Entry<K, V> e = table[bucketIndex];
//將新創建的 Entry 放入 bucketIndex 索引處,並讓新的 Entry 指向原來的 Entry
table[bucketIndex] = new Entry<K, V>(hash, key, value, e);
//若HashMap中元素的個數超過極限了,則容量擴大兩倍
if (size++ >= threshold)
resize(2 * table.length);
}
這個方法中有兩點需要注意:
一是鏈的產生。這是一個非常優雅的設計。系統總是將新的Entry對象添加到bucketIndex處。如果bucketIndex處已經有了對象,那麼新添加的Entry對象將指向原有的Entry對象,形成一條Entry鏈,但是若bucketIndex處沒有Entry對象,也就是e==null,那麼新添加的Entry對象指向null,也就不會產生Entry鏈了。
隨著HashMap中元素的數量越來越多,發生碰撞的概率就越來越大,所產生的鏈表長度就會越來越長,這樣勢必會影響HashMap的速度,為了保證HashMap的效率,系統必須要在某個臨界點進行擴容處理。該臨界點在當HashMap中元素的數量等於table數組長度*加載因子。但是擴容是一個非常耗時的過程,因為它需要重新計算這些數據在新table數組中的位置並進行復制處理。所以如果我們已經預知HashMap中元素的個數,那麼預設元素的個數能夠有效的提高HashMap的性能。
相對於HashMap的存而言,取就顯得比較簡單了。通過key的hash值找到在table數組中的索引處的Entry,然後返回該key對應的value即可。
public V get(Object key) {
// 若為null,調用getForNullKey方法返回相對應的value
if (key == null)
return getForNullKey();
// 根據該 key 的 hashCode 值計算它的 hash 碼
int hash = hash(key.hashCode());
// 取出 table 數組中指定索引處的值
for (Entry<K, V> e = table[indexFor(hash, table.length)]; e != null; e = e.next) {
Object k;
//若搜索的key與查找的key相同,則返回相對應的value
if (e.hash == hash && ((k = e.key) == key || key.equals(k)))
return e.value;
}
return null;
}
在這裡能夠根據key快速的取到value除了和HashMap的數據結構密不可分外,還和Entry有莫大的關系,在前面就提到過,HashMap在存儲過程中並沒有將key,value分開來存儲,而是當做一個整體key-value來處理的,這個整體就是Entry對象。同時value也只相當於key的附屬而已。在存儲的過程中,系統根據key的hashcode來決定Entry在table數組中的存儲位置,在取的過程中同樣根據key的hashcode取出相對應的Entry對象。