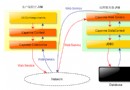
DOM的全稱是Document ObjectModel,也即文檔對象模型。在應用程序中,基於DOM的XML分析器將一個XML文檔轉換成一個對象模型的集合(通常稱DOM樹),應用程序正是通過對這個對象模型的操作,來實現對XML文檔數據的操作。通過DOM接口,應用程序可以在任何時候訪問XML文檔中的任何一部分數據,因此,這種利用DOM接口的機制也被稱作隨機訪問機制。
DOM接口提供了一種通過分層對象模型來訪問XML文檔信息的方式,這些分層對象模型依據XML的文檔結構形成了一棵節點樹。無論XML文檔中所描述的是什麼類型的信息,即便是制表數據、項目列表或一個文檔,利用DOM所生成的模型都是節點樹的形式。也就是說,DOM強制使用樹模型來訪問XML文檔中的信息。由於XML本質上就是一種分層結構,所以這種描述方法是相當有效的。
DOM樹所提供的隨機訪問方式給應用程序的開發帶來了很大的靈活性,它可以任意地控制整個XML文檔中的內容。然而,由於DOM分析器把整個XML文檔轉化成DOM樹放在了內存中,因此,當文檔比較大或者結構比較復雜時,對內存的需求就比較高。而且,對於結構復雜的樹的遍歷也是一項耗時的操作。所以,DOM分析器對機器性能的要求比較高,實現效率不十分理想。不過,由於DOM分析器所采用的樹結構的思想與XML文檔的結構相吻合,同時鑒於隨機訪問所帶來的方便,因此,DOM分析器還是有很廣泛的使用價值的。
Java代碼
1. import Java.io.File;
2.
3. import Javax.XML.parsers.DocumentBuilder;
4. import Javax.XML.parsers.DocumentBuilderFactory;
5.
6. import org.w3c.dom.Document;
7. import org.w3c.dom.Element;
8. import org.w3c.dom.NodeList;
9.
10. public class DomTest1
11. {
12. public static void main(String[] args) throws Exception
13. {
14. // step 1: 獲得dom解析器工廠(工作的作用是用於創建具體的解析器)
15. DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
16.
17. // System.out.println("class name: " + dbf.getClass().getName());
18.
19. // step 2:獲得具體的dom解析器
20. DocumentBuilder db = dbf.newDocumentBuilder();
21.
22. // System.out.println("class name: " + db.getClass().getName());
23.
24. // step3: 解析一個XML文檔,獲得Document對象(根結點)
25. Document document = db.parse(new File("candidate.XML"));
26.
27. NodeList list = document.getElementsByTagName("PERSON");
28.
29. for(int i = 0; i < list.getLength(); i++)
30. {
31. Element element = (Element)list.item(i);
32.
33. String content = element.getElementsByTagName("NAME").item(0).getFirstChild().getNodeValue();
34.
35. System.out.println("name:" + content);
36.
37. content = element.getElementsByTagName("ADDRESS").item(0).getFirstChild().getNodeValue();
38.
39. System.out.println("address:" + content);
40.
41. content = element.getElementsByTagName("TEL").item(0).getFirstChild().getNodeValue();
42.
43. System.out.println("tel:" + content);
44.
45. content = element.getElementsByTagName("FAX").item(0).getFirstChild().getNodeValue();
46.
47. System.out.println("fax:" + content);
48.
49. content = element.getElementsByTagName("EMAIL").item(0).getFirstChild().getNodeValue();
50.
51. System.out.println("email:" + content);
52.
53. System.out.println("--------------------------------------");
54. }
55. }
56. }
Java代碼
1. import Java.io.File;
2.
3. import Javax.XML.parsers.DocumentBuilder;
4. import Javax.XML.parsers.DocumentBuilderFactory;
5.
6. import org.w3c.dom.Attr;
7. import org.w3c.dom.Comment;
8. import org.w3c.dom.Document;
9. import org.w3c.dom.Element;
10. import org.w3c.dom.NamedNodeMap;
11. import org.w3c.dom.Node;
12. import org.w3c.dom.NodeList;
13.
14. /**
15. * 使用遞歸解析給定的任意一個XML文檔並且將其內容輸出到命令行上
16. * @author zhanglong
17. *
18. */
19. public class DomTest3
20. {
21. public static void main(String[] args) throws Exception
22. {
23. DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
24. DocumentBuilder db = dbf.newDocumentBuilder();
25.
26. Document doc = db.parse(new File("student.XML"));
27. //獲得根元素結點
28. Element root = doc.getDocumentElement();
29.
30. parseElement(root);
31. }
32.
33. private static void parseElement(Element element)
34. {
35. String tagName = element.getNodeName();
36.
37. NodeList children = element.getChildNodes();
38.
39. System.out.print("<" + tagName);
40.
41. //element元素的所有屬性所構成的NamedNodeMap對象,需要對其進行判斷
42. NamedNodeMap map = element.getAttributes();
43.
44. //如果該元素存在屬性
45. if(null != map)
46. {
47. for(int i = 0; i < map.getLength(); i++)
48. {
49. //獲得該元素的每一個屬性
50. Attr attr = (Attr)map.item(i);
51.
52. String attrName = attr.getName();
53. String attrValue = attr.getValue();
54.
55. System.out.print(" " + attrName + "=\"" + attrValue + "\"");
56. }
57. }
58.
59. System.out.print(">");
60.
61. for(int i = 0; i < children.getLength(); i++)
62. {
63. Node node = children.item(i);
64. //獲得結點的類型
65. short nodeType = node.getNodeType();
66.
67. if(nodeType == Node.ELEMENT_NODE)
68. {
69. //是元素,繼續遞歸
70. parseElement((Element)node);
71. }
72. else if(nodeType == Node.TEXT_NODE)
73. {
74. //遞歸出口
75. System.out.print(node.getNodeValue());
76. }
77. else if(nodeType == Node.COMMENT_NODE)
78. {
79. System.out.print("<!--");
80.
81. Comment comment = (Comment)node;
82.
83. //注釋內容
84. String data = comment.getData();
85.
86. System.out.print(data);
87.
88. System.out.print("-->");
89. }
90. }
91.
92. System.out.print("</" + tagName + ">");
93. }
94. }
SAX:
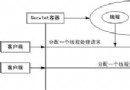
SAX的全稱是Simple APIs for XML,也即XML簡單應用程序接口。與DOM不同,SAX提供的訪問模式是一種順序模式,這是一種快速讀寫XML數據的方式。當使用SAX分析器對XML文檔進行分析時,會觸發一系列事件,並激活相應的事件處理函數,應用程序通過這些事件處理函數實現對XML文檔的訪問,因而SAX接口也被稱作事件驅動接口。
SAX 解析器采用了基於事件的模型,它在解析 XML 文檔的時候可以觸發一系列的事件,當發現給定的tag的時候,它可以激活一個回調方法,告訴該方法制定的標簽已經找到。SAX 對內存的要求通常會比較低,因為它讓開發人員自己來決定所要處理的tag。特別是當開發人員只需要處理文檔中所包含的部分數據時,SAX 這種擴展能力得到了更好的體現。但用 SAX 解析器的時候編碼工作會比較困難,而且很難同時訪問同一個文檔中的多處不同數據
Java代碼
1. import Java.io.File;
2.
3. import Javax.XML.parsers.SAXParser;
4. import Javax.XML.parsers.SAXParserFactory;
5.
6. import org.XML.sax.Attributes;
7. import org.XML.sax.SAXException;
8. import org.XML.sax.helpers.DefaultHandler;
9.
10. public class SaxTest1
11. {
12. public static void main(String[] args) throws Exception
13. {
14. //step1: 獲得SAX解析器工廠實例
15. SAXParserFactory factory = SAXParserFactory.newInstance();
16.
17. //step2: 獲得SAX解析器實例
18. SAXParser parser = factory.newSAXParser();
19.
20. //step3: 開始進行解析
21. parser.parse(new File("student.XML"), new MyHandler());
22.
23. }
24. }
25.
26. class MyHandler extends DefaultHandler
27. {
28. @Override
29. public void startDocument() throws SAXException
30. {
31. System.out.println("parse began");
32. }
33.
34. @Override
35. public void endDocument() throws SAXException
36. {
37. System.out.println("parse finished");
38. }
39.
40. @Override
41. public void startElement(String uri, String localName, String qName,
42. Attributes attributes) throws SAXException
43. {
44. System.out.println("start element");
45. }
46.
47. @Override
48. public void endElement(String uri, String localName, String qName)
49. throws SAXException
50. {
51. System.out.println("finish element");
52. }
53. }
Java代碼
1. import Java.io.File;
2. import Java.util.Stack;
3.
4. import Javax.XML.parsers.SAXParser;
5. import Javax.XML.parsers.SAXParserFactory;
6.
7. import org.XML.sax.Attributes;
8. import org.XML.sax.SAXException;
9. import org.XML.sax.helpers.DefaultHandler;
10.
11. public class SaxTest2
12. {
13. public static void main(String[] args) throws Exception
14. {
15. SAXParserFactory factory = SAXParserFactory.newInstance();
16.
17. SAXParser parser = factory.newSAXParser();
18.
19. parser.parse(new File("student.XML"), new MyHandler2());
20. }
21. }
22.
23. class MyHandler2 extends DefaultHandler
24. {
25. private Stack<String> stack = new Stack<String>();
26.
27. private String name;
28.
29. private String gender;
30.
31. private String age;
32.
33. @Override
34. public void startElement(String uri, String localName, String qName,
35. Attributes attributes) throws SAXException
36. {
37. stack.push(qName);
38.
39. for(int i = 0; i < attributes.getLength(); i++)
40. {
41. String attrName = attributes.getQName(i);
42. String attrValue = attributes.getValue(i);
43.
44. System.out.println(attrName + "=" + attrValue);
45. }
46. }
47.
48. @Override
49. public void characters(char[] ch, int start, int length)
50. throws SAXException
51. {
52. String tag = stack.peek();
53.
54. if("姓名".equals(tag))
55. {
56. name = new String(ch, start,length);
57. }
58. else if("性別".equals(tag))
59. {
60. gender = new String(ch, start, length);
61. }
62. else if("年齡".equals(tag))
63. {
64. age = new String(ch, start, length);
65. }
66. }
67.
68. @Override
69. public void endElement(String uri, String localName, String qName)
70. throws SAXException
71. {
72. stack.pop(); //表示該元素已經解析完畢,需要從棧中彈出
73.
74. if("學生".equals(qName))
75. {
76. System.out.println("姓名:" + name);
77. System.out.println("性別:" + gender);
78. System.out.println("年齡:" + age);
79.
80. System.out.println();
81. }
82.
83. }
84. }
JDOM:
JDOM是一個開源項目,它基於樹型結構,利用純Java的技術對XML文檔實現解析、生成、序列化以及多種操作。(http://jdom.org)
•JDOM 直接為JAVA編程服務。它利用更為強有力的Java語言的諸多特性(方法重載、集合概念等),把SAX和DOM的功能有效地結合起來。
•JDOM是用Java語言讀、寫、操作XML的新API函數。在直接、簡單和高效的前提下,這些API函數被最大限度的優化。
JDOM 與 DOM 主要有兩方面不同。首先,JDOM 僅使用具體類而不使用接口。這在某些方面簡化了 API,但是也限制了靈活性。第二,API 大量使用了 Collections 類,簡化了那些已經熟悉這些類的 Java 開發者的使用。
JDOM 文檔聲明其目的是“使用 20%(或更少)的精力解決 80%(或更多)Java/XML 問題”(根據學習曲線假定為 20%)。JDOM 對於大多數 Java/XML 應用程序來說當然是有用的,並且大多數開發者發現 API 比 DOM 容易理解得多。JDOM 還包括對程序行為的相當廣泛檢查以防止用戶做任何在 XML 中無意義的事。然而,它仍需要您充分理解 XML 以便做一些超出基本的工作(或者甚至理解某些情況下的錯誤)。這也許是比學習 DOM 或 JDOM 接口都更有意義的工作。
JDOM 自身不包含解析器。它通常使用 SAX2 解析器來解析和驗證輸入 XML 文檔(盡管它還可以將以前構造的 DOM 表示作為輸入)。它包含一些轉換器以將 JDOM 表示輸出成 SAX2 事件流、DOM 模型或 XML 文本文檔。JDOM 是在 apache 許可證變體下發布的開放源碼。
jdom創建XML
Java代碼
1. import Java.io.FileWriter;
2.
3. import org.jdom.Attribute;
4. import org.jdom.Comment;
5. import org.jdom.Document;
6. import org.jdom.Element;
7. import org.jdom.output.Format;
8. import org.jdom.output.XMLOutputter;
9.
10. public class JDomTest1
11. {
12. public static void main(String[] args) throws Exception
13. {
14. Document document = new Document();
15.
16. Element root = new Element("root");
17.
18. document.addContent(root);
19.
20. Comment comment = new Comment("This is my comments");
21.
22. root.addContent(comment);
23.
24. Element e = new Element("hello");
25.
26. e.setAttribute("sohu", "www.sohu.com");
27.
28. root.addContent(e);
29.
30. Element e2 = new Element("world");
31.
32. Attribute attr = new Attribute("test", "hehe");
33.
34. e2.setAttribute(attr);
35.
36. e.addContent(e2);
37.
38. e2.addContent(new Element("aaa").setAttribute("a", "b")
39. .setAttribute("x", "y").setAttribute("gg", "hh").setText("text content"));
40.
41.
42. Format format = Format.getPrettyFormat();
43.
44. format.setIndent(" ");
45. // format.setEncoding("gbk");
46.
47. XMLOutputter out = new XMLOutputter(format);
48.
49. out.output(document, new FileWriter("jdom.XML"));
50.
51. }
52. }
JDOM解析XML
Java代碼
1. import Java.io.File;
2. import Java.io.FileOutputStream;
3. import Java.util.List;
4.
5. import org.jdom.Attribute;
6. import org.jdom.Document;
7. import org.jdom.Element;
8. import org.jdom.input.SAXBuilder;
9. import org.jdom.output.Format;
10. import org.jdom.output.XMLOutputter;
11.
12. public class JDomTest2
13. {
14. public static void main(String[] args) throws Exception
15. {
16. SAXBuilder builder = new SAXBuilder();
17.
18. Document doc = builder.build(new File("jdom.XML"));
19.
20. Element element = doc.getRootElement();
21.
22. System.out.println(element.getName());
23.
24. Element hello = element.getChild("hello");
25.
26. System.out.println(hello.getText());
27.
28. List list = hello.getAttributes();
29.
30. for(int i = 0 ;i < list.size(); i++)
31. {
32. Attribute attr = (Attribute)list.get(i);
33.
34. String attrName = attr.getName();
35. String attrValue = attr.getValue();
36.
37. System.out.println(attrName + "=" + attrValue);
38. }
39.
40. hello.removeChild("world");
41.
42. XMLOutputter out = new XMLOutputter(Format.getPrettyFormat().setIndent(" "));
43.
44.
45. out.output(doc, new FileOutputStream("jdom2.XML"));
46.
47. }
48. }
Dom4j
官網:DOM4Jhttp://dom4j.sourceforge.Net/
雖然 DOM4J 代表了完全獨立的開發結果,但最初,它是 JDOM 的一種智能分支。它合並了許多超出基本 XML 文檔表示的功能,包括集成的 XPath 支持、XML Schema 支持以及用於大文檔或流化文檔的基於事件的處理。它還提供了構建文檔表示的選項,它通過 DOM4J API 和標准 DOM 接口具有並行訪問功能。從 2000 下半年開始,它就一直處於開發之中。
為支持所有這些功能,DOM4J 使用接口和抽象基本類方法。DOM4J 大量使用了 API 中的 Collections 類,但是在許多情況下,它還提供一些替代方法以允許更好的性能或更直接的編碼方法。直接好處是,雖然 DOM4J 付出了更復雜的 API 的代價,但是它提供了比 JDOM 大得多的靈活性。
在添加靈活性、XPath 集成和對大文檔處理的目標時,DOM4J 的目標與 JDOM 是一樣的:針對 Java 開發者的易用性和直觀操作。它還致力於成為比 JDOM 更完整的解決方案,實現在本質上處理所有 Java/XML 問題的目標。在完成該目標時,它比 JDOM 更少強調防止不正確的應用程序行為。
DOM4J 是一個非常非常優秀的Java XML API,具有性能優異、功能強大和極端易用使用的特點,同時它也是一個開放源代碼的軟件。如今你可以看到越來越多的 Java 軟件都在使用 DOM4J 來讀寫 XML,特別值得一提的是連 Sun 的 JAXM 也在用 DOM4J。
Java代碼
1. import Java.io.FileOutputStream;
2. import Java.io.FileWriter;
3.
4. import org.dom4j.Document;
5. import org.dom4j.DocumentHelper;
6. import org.dom4j.Element;
7. import org.dom4j.io.OutputFormat;
8. import org.dom4j.io.XMLWriter;
9.
10. public class Test1
11. {
12. public static void main(String[] args) throws Exception
13. {
14. // 創建文檔並設置文檔的根元素節點 :第一種方式
15. // Document document = DocumentHelper.createDocument();
16. //
17. // Element root = DocumentHelper.createElement("student");
18. //
19. // document.setRootElement(root);
20.
21. // 創建文檔並設置文檔的根元素節點 :第二種方式
22. Element root = DocumentHelper.createElement("student");
23. Document document = DocumentHelper.createDocument(root);
24.
25. root.addAttribute("name", "zhangsan");
26.
27. Element helloElement = root.addElement("hello");
28. Element worldElement = root.addElement("world");
29.
30. helloElement.setText("hello");
31. worldElement.setText("world");
32.
33. helloElement.addAttribute("age", "20");
34.
35. XMLWriter xmlWriter = new XMLWriter();
36. XMLWriter.write(document);
37.
38. OutputFormat format = new OutputFormat(" ", true);
39.
40. XMLWriter xmlWriter2 = new XMLWriter(new FileOutputStream("student2.XML"), format);
41. XMLWriter2.write(document);
42.
43. XMLWriter xmlWriter3 = new XMLWriter(new FileWriter("student3.XML"), format);
44.
45. XMLWriter3.write(document);
46. XMLWriter3.close();
47.
48. }
49. }
Java代碼
1. import Java.io.File;
2. import Java.util.Iterator;
3. import Java.util.List;
4.
5. import Javax.XML.parsers.DocumentBuilder;
6. import Javax.XML.parsers.DocumentBuilderFactory;
7.
8. import org.dom4j.Document;
9. import org.dom4j.Element;
10. import org.dom4j.io.DOMReader;
11. import org.dom4j.io.SAXReader;
12.
13. public class Test2
14. {
15. public static void main(String[] args) throws Exception
16. {
17. SAXReader saxReader = new SAXReader();
18.
19. Document doc = saxReader.read(new File("student2.XML"));
20.
21. Element root = doc.getRootElement();
22.
23. System.out.println("root element: " + root.getName());
24.
25. List childList = root.elements();
26.
27. System.out.println(childList.size());
28.
29. List childList2 = root.elements("hello");
30.
31. System.out.println(childList2.size());
32.
33. Element first = root.element("hello");
34.
35. System.out.println(first.attributeValue("age"));
36.
37. for(Iterator iter = root.elementIterator(); iter.hasNext();)
38. {
39. Element e = (Element)iter.next();
40.
41. System.out.println(e.attributeValue("age"));
42. }
43.
44. System.out.println("---------------------------");
45.
46. DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
47. DocumentBuilder db = dbf.newDocumentBuilder();
48. org.w3c.dom.Document document = db.parse(new File("student2.XML"));
49.
50. DOMReader domReader = new DOMReader();
51.
52. //將JAXP的Document轉換為dom4j的Document
53. Document d = domReader.read(document);
54.
55. Element rootElement = d.getRootElement();
56.
57. System.out.println(rootElement.getName());
58.
59. }
60. }
Java代碼
1. import Java.io.FileWriter;
2.
3. import org.jdom.Attribute;
4. import org.jdom.Document;
5. import org.jdom.Element;
6. import org.jdom.output.Format;
7. import org.jdom.output.XMLOutputter;
8.
9. public class Test3
10. {
11. public static void main(String[] args) throws Exception
12. {
13. Document document = new Document();
14.
15. Element root = new Element("聯系人列表").setAttribute(new Attribute("公司",
16. "A集團"));
17.
18. document.addContent(root);
19.
20. Element contactPerson = new Element("聯系人");
21.
22. root.addContent(contactPerson);
23.
24. contactPerson
25. .addContent(new Element("姓名").setText("張三"))
26. .addContent(new Element("公司").setText("A公司"))
27. .addContent(new Element("電話").setText("021-55556666"))
28. .addContent(
29. new Element("地址")
30. .addContent(new Element("街道").setText("5街"))
31. .addContent(new Element("城市").setText("上海"))
32. .addContent(new Element("省份").setText("上海市")));
33.
34. XMLOutputter output = new XMLOutputter(Format.getPrettyFormat()
35. .setIndent(" ").setEncoding("gbk"));
36.
37. output.output(document, new FileWriter("contact.XML"));
38.
39. }
40. }