近來試著FTP搜索,遇到編碼問題,研究了下。
Java內部的String為Unicode編碼,每個字符占兩個字節。
Java編解碼方法如下:
- String str = "hi好啊me";
- byte[] gbkBytes=str.getBytes("GBK");//將String的Unicode編碼轉為GBK編碼,輸出到字節中
- String string=new String(gbkBytes,"GBK");//gbkBytes中的字節流以GBK方案解碼成Unicode形式的Java字符串
1、表單數據的編碼
現在的問題是,在網絡中,不知道客戶端發過來的字節流的編碼方案(發送前浏覽器會對數據編碼!!!各個浏覽器還不一樣!!!)
解決方案如下:
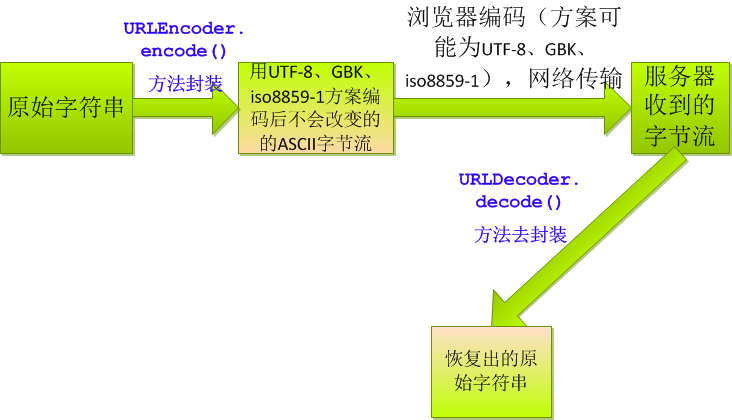
當然URLEncoder.encode(str, "utf-8")和URLDecoder.decode(strReceive,"utf-8")方法中的編碼方案要一致。
2、網址的編碼
但以上方法只適合表單數據的提交;對於URL則不行!!!原因是URLEncoder把'/'也編碼了,浏覽器發送時報錯!!!那麼,只要http://IP/子目錄把http://IP/這部分原封不動(當然這部分不要有中文),之後的數據以'/'分割後分段編碼即可。
代碼如下:
- /**
- * 對{@link URLEncoder#encode(String, String)}的封裝,但不編碼'/'字符,對其他字符分段編碼
- *
- * @param str
- * 要編碼的URL
- * @param encoding
- * 編碼格式
- * @return 字符串以字符'/'隔開,對每一段單獨編碼以encoding編碼格式編碼
- * @version: 2012_01_10
- * <p>
- * 注意:未考慮':',如直接對http://編解碼,會產生錯誤!!!請在使用前將其分離出來,可以使用
- * {@link #encodeURLAfterHost(String, String)}方法解決此問題
- * <p>
- * 注意:對字符/一起編碼,導致URL請求異常!!
- */
- public static String encodeURL(String str, String encoding) {
- final char splitter = '/';
- try {
- StringBuilder sb = new StringBuilder(2 * str.length());
- int start = 0;
- for (int i = 0; i < str.length(); i++) {
- if (str.charAt(i) == splitter) {
- sb.append(URLEncoder.encode(str.substring(start, i),
- encoding));
- sb.append(splitter);
- start = i + 1;
- }
- }
- if (start < str.length())
- sb.append(URLEncoder.encode(str.substring(start), encoding));
- return sb.toString();
- } catch (UnsupportedEncodingException e) {
- e.printStackTrace();
- }
- return null;
- }
- /**
- * 對IP地址後的URL通過'/'分割後進行分段編碼.
- * <p>
- * 對{@link URLEncoder#encode(String, String)}
- * 的封裝,但不編碼'/'字符,也不編碼網站部分(如FTP://a.b.c.d/部分,檢測方法為對三個'/'字符的檢測,且要求前兩個連續),
- * 對其他字符分段編碼
- *
- * @param str
- * 要編碼的URL
- * @param encoding
- * 編碼格式
- * @return IP地址後字符串以字符'/'隔開,對每一段單獨編碼以encoding編碼格式編碼,其他部分不變
- * @version: 2012_01_10
- * <p>
- * 注意:對字符/一起編碼,導致URL請求異常!!
- */
- public static String encodeURLAfterHost(String str, String encoding) {
- final char splitter = '/';
- int index = str.indexOf(splitter);//第一個'/'的位置
- index++;//移到下一位置!!
- if (index < str.length() && str.charAt(index) == splitter) {//檢測第一個'/'之後是否還是'/',如FTP://
- index++;//從下一個開始
- index = str.indexOf(splitter, index);//第三個'/';如FTP://anonymous:[email protected]:219.223.168.20/中的最後一個'/'
- if (index > 0) {
- return str.substring(0, index + 1)
- + encodeURL(str.substring(index + 1), encoding);//如FTP://anonymous:[email protected]:219.223.168.20/天空
- } else
- return str;//如FTP://anonymous:[email protected]:219.223.168.20
- }
- return encodeURL(str, encoding);
- }
- /**
- * 對IP地址後的URL通過'/'分割後進行分段編碼.
- * 此方法與{@link #decodeURLAfterHost(String, String)}配對使用
- * @param str
- * 要解碼的URL
- * @param encoding
- * str的編碼格式
- * @return IP地址後字符串以字符'/'隔開,對每一段單獨解碼以encoding編碼格式解碼,其他部分不變
- * @version: 2012_01_10
- *
- * <p>
- * 注意:對字符/一起解碼,將導致URL請求異常!!
- */
- public static String decodeURLAfterHost(String str, String encoding) {
- final char splitter = '/';
- int index = str.indexOf(splitter);//第一個'/'的位置
- index++;//移到下一位置!!
- if (index < str.length() && str.charAt(index) == splitter) {//檢測第一個'/'之後是否還是'/',如FTP://
- index++;//從下一個開始
- index = str.indexOf(splitter, index);//第三個'/';如FTP://anonymous:[email protected]:219.223.168.20/中的最後一個'/'
- if (index > 0) {
- return str.substring(0, index + 1)
- + decodeURL(str.substring(index + 1), encoding);//如FTP://anonymous:[email protected]:219.223.168.20/天空
- } else
- return str;//如FTP://anonymous:[email protected]:219.223.168.20
- }
- return decodeURL(str, encoding);
- }
- /**
- * 此方法與{@link #encodeURL(String, String)}配對使用
- * <p>
- * 對{@link URLDecoder#decode(String, String)}的封裝,但不解碼'/'字符,對其他字符分段解碼
- *
- * @param str
- * 要解碼的URL
- * @param encoding
- * str的編碼格式
- * @return 字符串以字符'/'隔開,對每一段單獨編碼以encoding編碼格式解碼
- * @version: 2012_01_10
- *
- * <p>
- * 注意:對字符/一起編碼,導致URL請求異常!!
- */
- public static String decodeURL(String str, String encoding) {
- final char splitter = '/';
- try {
- StringBuilder sb = new StringBuilder(str.length());
- int start = 0;
- for (int i = 0; i < str.length(); i++) {
- if (str.charAt(i) == splitter) {
- sb.append(URLDecoder.decode(str.substring(start, i),
- encoding));
- sb.append(splitter);
- start = i + 1;
- }
- }
- if (start < str.length())
- sb.append(URLDecoder.decode(str.substring(start), encoding));
- return sb.toString();
- } catch (UnsupportedEncodingException e) {
- e.printStackTrace();
- }
- return null;
- }
3、亂碼了還能恢復?
問題如下:
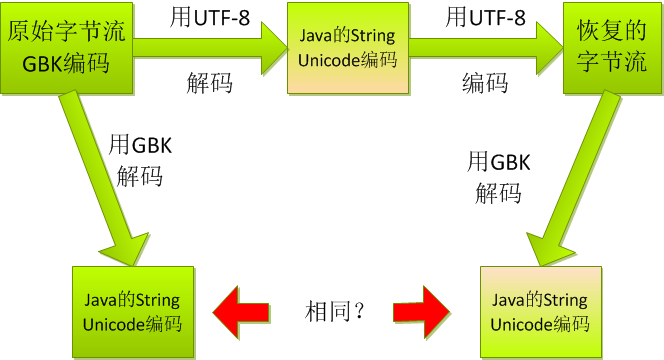
貌似圖中的utf-8改成iso8859-1是可以的,utf-8在字符串中有中文時不行(但英文部分仍可正確解析)!!!畢竟GBK的字節流對於utf-8可能是無效的,碰到無效的字符怎麼解析,是否可逆那可不好說啊。
測試代碼如下:
- package tests;
- import Java.io.UnsupportedEncodingException;
- import Java.Net.URLEncoder;
- /**
- * @author LC
- * @version: 2012_01_12
- */
- public class TestEncoding {
- static String utf8 = "utf-8";
- static String iso = "iso-8859-1";
- static String gbk = "GBK";
- public static void main(String[] args) throws UnsupportedEncodingException {
- String str = "hi好啊me";
- // System.out.println("?的十六進制為:3F");
- // System.err
- // .println("出現中文時,如果編碼方案不支持中文,每個字符都會被替換為?的對應編碼!(如在iso-8859-1中)");
- System.out.println("原始字符串:\t\t\t\t\t\t" + str);
- String utf8_encoded = URLEncoder.encode(str, "utf-8");
- System.out.println("用URLEncoder.encode()方法,並用UTF-8編碼後:\t\t" + utf8_encoded);
- String gbk_encoded = URLEncoder.encode(str, "GBK");
- System.out.println("用URLEncoder.encode()方法,並用GBK編碼後:\t\t" + gbk_encoded);
- testEncoding(str, utf8, gbk);
- testEncoding(str, gbk, utf8);
- testEncoding(str, gbk, iso);
- printBytesInDifferentEncoding(str);
- printBytesInDifferentEncoding(utf8_encoded);
- printBytesInDifferentEncoding(gbk_encoded);
- }
- /**
- * 測試用錯誤的編碼方案解碼後再編碼,是否對原始數據有影響
- *
- * @param str
- * 輸入字符串,Java的String類型即可
- * @param encodingTrue
- * 編碼方案1,用於模擬原始數據的編碼
- * @param encondingMidian
- * 編碼方案2,用於模擬中間的編碼方案
- * @throws UnsupportedEncodingException
- */
- public static void testEncoding(String str, String encodingTrue,
- String encondingMidian) throws UnsupportedEncodingException {
- System.out.println();
- System.out
- .printf("%s編碼的字節數據->用%s解碼並轉為Unicode編碼的JavaString->用%s解碼變為字節流->讀入Java(用%s解碼)後變為Java的String\n",
- encodingTrue, encondingMidian, encondingMidian,
- encodingTrue);
- System.out.println("原始字符串:\t\t" + str);
- byte[] trueEncodingBytes = str.getBytes(encodingTrue);
- System.out.println("原始字節流:\t\t" + bytesToHexString(trueEncodingBytes)
- + "\t\t//即用" + encodingTrue + "編碼後的字節流");
- String encodeUseMedianEncoding = new String(trueEncodingBytes,
- encondingMidian);
- System.out.println("中間字符串:\t\t" + encodeUseMedianEncoding + "\t\t//即用"
- + encondingMidian + "解碼原始字節流後的字符串");
- byte[] midianBytes = encodeUseMedianEncoding.getBytes("Unicode");
- System.out.println("中間字節流:\t\t" + bytesToHexString(midianBytes)
- + "\t\t//即中間字符串對應的Unicode字節流(和Java內存數據一致)");
- byte[] redecodedBytes = encodeUseMedianEncoding
- .getBytes(encondingMidian);
- System.out.println("解碼字節流:\t\t" + bytesToHexString(redecodedBytes)
- + "\t\t//即用" + encodingTrue + "解碼中間字符串(流)後的字符串");
- String restored = new String(redecodedBytes, encodingTrue);
- System.out.println("解碼字符串:\t\t" + restored + "\t\t和原始數據相同? "
- + restored.endsWith(str));
- }
- /**
- * 將字符串分別編碼為GBK、UTF-8、iso-8859-1的字節流並輸出
- *
- * @param str
- * @throws UnsupportedEncodingException
- */
- public static void printBytesInDifferentEncoding(String str)
- throws UnsupportedEncodingException {
- System.out.println("");
- System.out.println("原始String:\t\t" + str + "\t\t長度為:" + str.length());
- String unicodeBytes = bytesToHexString(str.getBytes("unicode"));
- System.out.println("Unicode bytes:\t\t" + unicodeBytes);
- String gbkBytes = bytesToHexString(str.getBytes("GBK"));
- System.out.println("GBK bytes:\t\t" + gbkBytes);
- String utf8Bytes = bytesToHexString(str.getBytes("utf-8"));
- System.out.println("UTF-8 bytes:\t\t" + utf8Bytes);
- String iso8859Bytes = bytesToHexString(str.getBytes("iso-8859-1"));
- System.out.println("iso8859-1 bytes:\t" + iso8859Bytes + "\t\t長度為:"
- + iso8859Bytes.length() / 3);
- System.out.println("可見Unicode在之前加了兩個字節FE FF,之後則每個字符兩字節");
- }
- /**
- * 將該數組轉的每個byte轉為兩位的16進制字符,中間用空格隔開
- *
- * @param bytes
- * 要轉換的byte序列
- * @return 轉換後的字符串
- */
- public static final String bytesToHexString(byte[] bytes) {
- StringBuilder sb = new StringBuilder(bytes.length * 2);
- for (int i = 0; i < bytes.length; i++) {
- String hex = Integer.toHexString(bytes[i] & 0xff);// &0xff是byte小於0時會高位補1,要改回0
- if (hex.length() == 1)
- sb.append('0');
- sb.append(hex);
- sb.append(" ");
- }
- return sb.toString().toUpperCase();
- }
- }