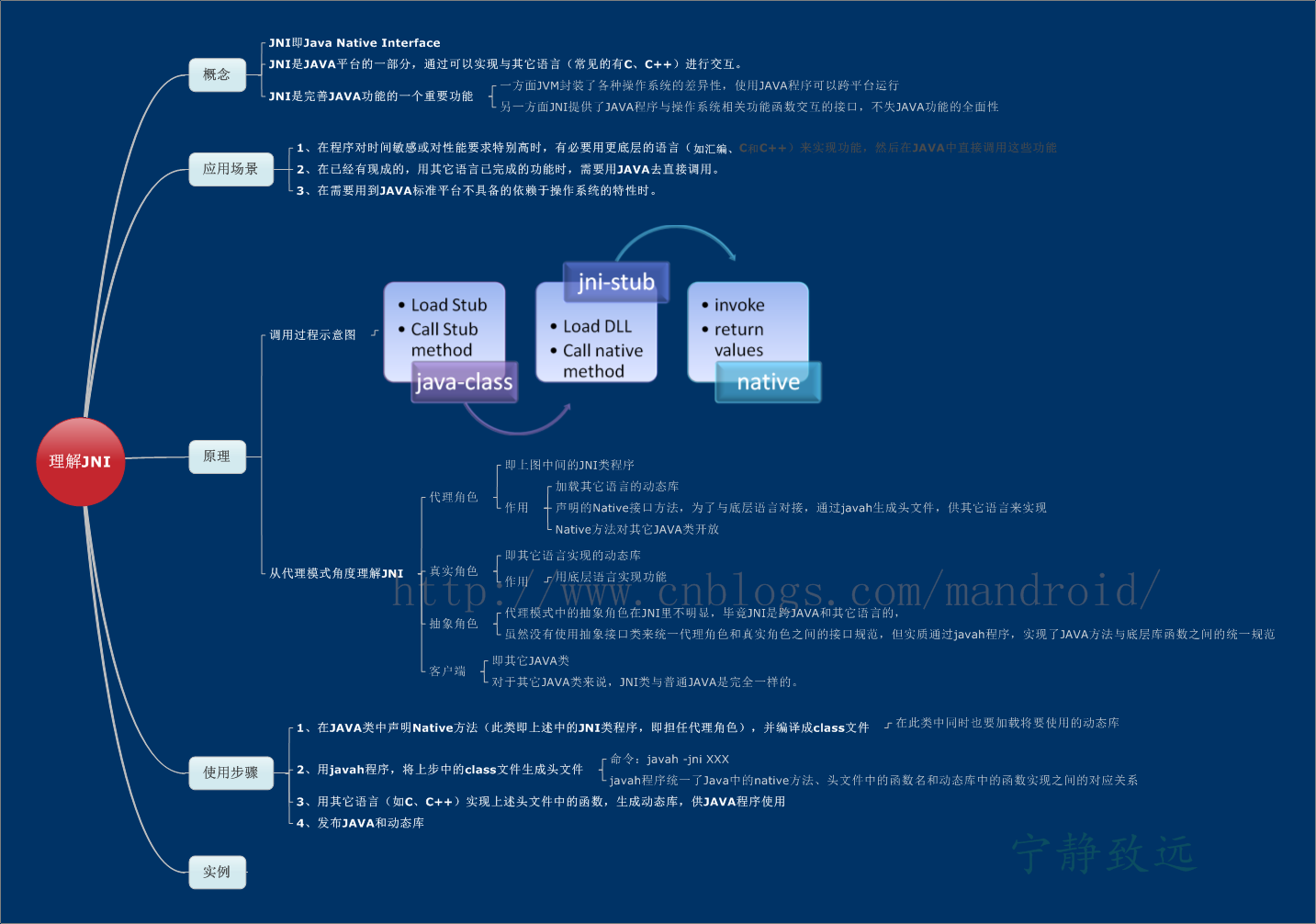
左移操作: x << n
x可以是byte, short, char, int, long基本類型, n(位移量)只能是int型
編譯器的執行步驟:
1) 如果x是byte, short, char類型, 則將x提升為int;
2) 如果x是byte, short, char, int類型, 則n被重新賦值(過程是:取n的補碼的低5位再轉成十進制的int值,相當對n取32模: n=n%32);
如果x是long型, 則n被重新賦值(過程是:取n的補碼的低6位再轉成十進制的int值,相當對n取64模: n=n%64);
(因為int類型為4個字節,即32位,移動32位將沒有任何意義.對於long則是模64)
3) 對x左移n個位數, 整個表達式產生一個新值(x的值不變);
<<是左移符號,列x<<1,就是x的內容左移一位(x的內容並不改變)
>>是帶符號位的右移符號,x>>1就是x的內容右移一位,如果開頭是1則補1,是0責補0,(x的內容並不改變).
>>>是不帶符號位的右移,x>>>1就是x的內容右移一位,開頭補0(x的內容並不改變)
補充說明:
Java代碼
- // 左移: 向左移動,右邊補0
- for (int i = 0;i < 8 ;i++)
- System.out.print( (1 << i) + " ");
output
1 2 4 8 16 32 64 128
- // 右移: 向右移動,如果符號位(int型為32位)為0,左邊補0,符號位為1,左邊補1
- // 符號位為1的右移
- for (int i = 0;i < 8 ;i++)
- System.out.print( Integer.toHexString(0x40000000 >> i) + " ");
output
40000000 20000000 10000000 8000000 4000000 2000000 1000000 800000
- // 符號位為1的右移
- // 最高4位為1000, 右移1位,變成1100也就是c,
- for (int i = 0;i < 8 ;i++)
- System.out.print( Integer.toHexString(0x80000000 >> i) + " ");
output
80000000 c0000000 e0000000 f0000000 f8000000 fc000000 fe000000 ff000000
上面的通用法則沒有錯,但是有一個限制,對int型,移位的位數不超過32,對long型,移位的位數不超過64。現在進行如下測試:
Java代碼
- System.out.println(Integer.toHexString(0x80000000 >> 31));
- // output: ffffffff
- System.out.println(Integer.toHexString(0x80000000 >> 32));
- // output: 80000000
0x80000000在右移31位後,每個位都成了1(也就是-1),按照這個想法,右移32位理所當然的還是-1,可是右移32位後,得到的結果卻又這個數本身。
通過對int,long類型數據左右移進行測試,發現:
Java對移位運算"a <<||>> b"的處理,首先做 b mod 32||64運算, 如果a是int型,取mod 32,如果a是double型,取mod 64,然後再使用上面提到的通用移位運算規則進行移位。
到這裡,就可以理解為什麼在BitSet類中是
- 1L << bitIndex
這條語句,因為熟悉jdk的Programer知道,再寫 1L << (bitIndex % 64) 對jdk來說是多余的。