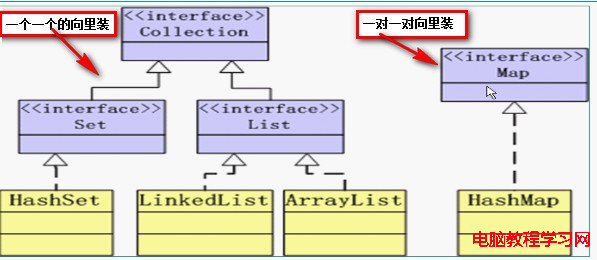
內容:
初識高速緩存和連接池
Cache(高速緩存)和Connection Pool(連接池)的概念和機制
高速緩存的參數設定
連接池的設置和應用
性能問題的深遠思索
解決性能問題的幾條經驗
初識高速緩存和連接池
設想這樣一種情形:你突然口渴,需要一杯水來緩解,從心情上來講,當然是越快越好了。通常,一杯水的產生包括從水源(井水、河水或江水、甚至海水等)抽取,通過管道傳輸和設備淨化,才到達你飲水的容器中。上述過程是必須的,但並不是每一杯水的產生都必須把上述過程重復一次。你可以用一個大一點的容器(例如缸或罐等)來盛大量的水,喝水之前分到杯子小部分中即可,你的代價只是把水從缸轉移到杯子;你還可以在大量用水(例如洗澡或洗衣服等)時,只需打開水閥,而不必臨時鋪設通往水源的管道和購買淨化水的設備。因為水是人們生活不可缺少的東西,每時每刻都在被大量地使用,而且物理本質也完全相同,所以政府會鋪設管道和建設水處理站,完成那些比較困難的工作,達到資源共享的目的,而你也可針對自己的需求,用容器來盛那些具有特定用途的水。本文將要和你討論的高速緩存和連接池與上述特定容器和傳輸管道有很多相似之處,它們都達到了同一個目的:在滿足用戶意願的前提下,盡可能地共享資源,以提高整個系統的性能。
高速緩存和連接池是數據訪問中的重要技術,某些情況下的應用對訪問數據庫(數據庫培訓 數據庫認證 )的性能有巨大的提高,而且都得到了數據庫業界的普遍支持。前者由DBMS廠商針對自己的數據庫實現,提供可供用戶配置的方案;後者是JDBC的一個標准接口,由支持J2EE技術的應用服務器廠商提供具體的實現,而你的Java程序代碼無需更改。本文將向你簡單介紹高速緩存和連接池的概念和機制,並以PointBase數據庫為例向你展示高速緩存的應用,而一個簡單的連接池應用場景將向你描述應用的條件和提高的性能。
Cache(高速緩存)和Connection Pool(連接池)的概念和機制
它們不是數據庫獨有的技術,但卻得到數據庫業界的普遍支持,並在其它數據存取和對象復用領域有很多類似的應用。
Cache(高速緩存)
作為個人計算機的日常使用者,你肯定聽說過這些名詞:Cache(高速緩存)、Memory(內存)、Hard disk(硬盤)。它們都是數據存取單元,但存取速度卻有很大差異,呈依次遞減的順序。對於CPU來說,它可以從距離自己最近的Cache高速地存取數據,而不是從內存和硬盤以低幾個數量級的速度來存取數據。而Cache中所存儲的數據,往往是CPU要反復存取的數據,有特定的機制(或程序)來保證Cache內數據的命中率(Hit Rate)。因此,CPU存取數據的速度在應用高速緩存後得到了巨大的提高。
對於數據庫來說,廠商的做法往往是在內存中開辟相應的區域來存儲可能被多次存取的數據和可能被多次執行的語句,以使這些數據在下次被訪問時不必再次提交對DBMS的請求和那些語句在下次執行時不必再次編譯。
因為將數據寫入高速緩存的任務由Cache Manager負責,所以對用戶來說高速緩存的內容肯定是只讀的。需要你做的工作很少,程序中的SQL語句和直接訪問DBMS時沒有分別,返回的結果也看不出有什麼差別。而數據庫廠商往往會在DB Server的配置文件中提供與Cache相關的參數,通過修改它們,可針對我們的應用優化Cache的管理。下圖是在Win2K中配置MS Access數據源的界面,在"驅動程序"部分你可設置的頁超時和緩沖區大小就是和Cache有關的參數。在後面的討論中,我將展示一個更復雜的數據庫,向你解釋Cache對訪問數據庫性能的影響和如何尋找最優的配置方案。
Connection Pool(連接池)
池是一個很普遍的概念,和緩沖存儲有機制相近的地方,都是縮減了訪問的環節,但它更注重於資源的共享。下圖展示了建立"調制解調器池"以共享調制解調器資源的VPN撥號方案:
對於訪問數據庫來說,建立連接的代價比較昂貴,因此,我們有必要建立"連接池"以提高訪問的性能。我們可以把連接當作對象或者設備,池中又有許多已經建立的連接,訪問本來需要與數據庫的連接的地方,都改為和池相連,池臨時分配連接供訪問使用,結果返回後,訪問將連接交還。
JDBC 1.0標准及其擴展中沒有定義連接池,而在JDBC 2.0標准的擴展中定義了與連接池相關的接口。與接口對應的類由應用服務器廠商實現,你可在對服務器的管理過程中調節某個數據庫連接池的參數。下圖簡略地描述了連接池的運行機制:
高速緩存的參數設定
在PointBase數據庫DB Server的配置參數列表中,我們可以找到這幾個參數:cache.checkpointinterval、cache.size、SQLCaching.size等。下表是對各個參數的描述:
參數名 參數描述
cache.checkpointinterval 檢查點的時間間隔
cache.size 高速緩存的最大頁數(素數時,性能最好)
SQLCaching.size 高速緩存中SQL語句的個數
對於cache.checkpointinterval來說,和前面Access界面中的頁超時是一個概念,它指定了頁面內容更新的時間間隔,這取決於你的應用對時效性的要求程度。
對於cache.size來說,指定了頁面的個數,一般應設定為符合你查詢結果的需求。至於為何是素數,我也納悶,不過還是遵照廠商的指示吧。
對於SQLCaching.size來說,指定了存儲的經過編譯的SQL語句的個數,你可以把它設定為0,從而取消這個選項。
使用Cache後,性能到底有多大提高?我打開PointBase的Console通過JDBC驅動訪問Server,將SQL菜單下的Timing Mode選上,以顯示各個步驟的耗費時間。執行語句是:
SELECT * FROM PRODUCT_TBL
第一次訪問,總計耗時1082毫秒,而編譯耗時771毫秒。
緊接著的第二次訪問,總計耗時僅為160毫秒,而編譯耗時為0。
再接著的第三次訪問,總計耗時僅為91毫秒,編譯耗時也為0。
關閉Console,等待超過30秒之後,重新開啟Console,執行相同的語句,總計耗時210毫秒,編譯耗時為20毫秒。
自等待超過30秒之後,執行語句,總計耗時101毫秒,編譯耗時為0。
由此可以看出,高速緩存的應用大大提高了訪問數據庫的性能,而其參數的設定則要依據前面對它們的描述來進行,需要你仔細閱讀數據庫的配置文檔。
連接池的設置和應用
我選擇IBM公司的應用服務器平台WebSphere來給大家演示連接池的設置,使你面對友好的Web界面,可以體驗到非常簡易的操作場景。
首先,我們進入WebSphere的管理控制台,這是一個非常漂亮的Web界面:
緊接著,我選定一個數據源:Session Persistence datasource,就可看到這個數據源的屬性配置了。在這兒,僅僅列舉和連接池有關的屬性:
Minimum Pool Size 池中保持的連接的最小數目;有新的請求,且沒有激活連接可供使用時,池中連接數將增大,到最大連接數為止
Maximum Pool Size 池中保持的連接的最大數目;當這個數目達到,且沒有激活連接可供使用時,新的請求將等待
Connection Timeout 當連接數達到最大值,且激活連接都在被使用時,新的請求等待的時間
Idle Timeout 連接可在池中閒置的時間;超過將釋放資源,到最小連接數為止
Orphan Timeout 連接在被應用控制時,可閒置的時間;超過將返回池中
你可以根據需要來修改這些數值,以滿足你的應用需要。接下來,我們討論一下連接池的應用。
EJB訪問數據庫(場景1,使用JDBC 1.0) import Java.sql.*;
import Javax.sql.*;
...
public class AccountBean implements EntityBean {
...
public Collection ejbFindByLastName(String lName) {
try {
String dbdriver = new initialContext().lookup("Java:comp/env/DBDRIVER").toString();
Class.forName(dbdriver).newInstance();
Connection conn = null;
conn = DriverManager.getConnection("Java:comp/env/DBURL", "userID", "passWord");
...
conn.close();
}
...
}
如果EntityBean是一個共享組件,那麼每次客戶請求時,都要建立和釋放與數據庫的連接,這成為影響性能的主要問題。
EJB訪問數據庫(場景2,使用JDBC 2.0) import Java.sql.*;
import Javax.sql.*;
// import here vendor specific JDBC drivers
public ProductPK ejbCreate() {
try {
// initialize JNDI lookup parameters
Context ctx = new InitialContext(parms);
...
ConnectionPoolDataSource cpds = (ConnectionPoolDataSource)ctx.lookup(cpsource);
...
// Following parms could all come from a JNDI look-up
cpds.setDatabaseName("PTDB");
cpds.setUserIF("XYZ");
...
PooledConnection pc = cpds.getPooledConnection();
Connection conn = pc.getConnection();
...
// do business logic
conn.close();
}
...
}
EJB組件利用JNDI的lookup()方法定位數據庫的連接池資源,利用getConnection()方法得到已經打開的數據庫連接,而用close()來釋放連接,放回池中。因此,與場景1相比,少了與數據庫建立物理連接的損耗。對於原本要頻繁打開和關閉物理連接的應用來說,通過這種建立邏輯連接並復用的方法,性能肯定能夠得到大幅度提高。
性能問題的深遠思索
性能問題並不局限於數據庫的應用上,而是存在於每個軟件系統中。我們希望軟件系統付出的最小,而獲得的最大,因而無時無刻不在優化它們。通過《Java程序訪問數據庫的速度瓶頸問題的分析和解決》和本文,我對Java程序訪問數據庫的性能問題做了分析,並提供了優化Java程序的解決方案,希望對你有所幫助。
也許你會關心碰到類似的性能問題時應如何分析和解決,我就針對此次探討"訪問數據庫的速度瓶頸"問題的過程中碰到的難題、網友的意見和自己的體會,作一個關於"方法論"的經驗總結,希望能夠拋磚引玉,更好地解決類似的問題。
解決性能問題的幾條經驗
不要讓硬件的低配置成為軟件正常運行的障礙,後者有升級前者的需求,請立即滿足;經常碰到這樣的問題"P166+64M的機子跑Win2K+MySQL+JBoss,能跑麼?"我在回答"可以"的同時只有對著屏幕發呆了。
盡量使用商業軟件,並享受良好的售後技術支持;如果你沒有黑客精神,請不要使用自由軟件。
分析好自己的問題,也許它的本質和他人的不同;沒有一把鑰匙可打開的任一把鎖。
確定瓶頸環節的位置;解決了瓶頸問題,往往整個的性能問題就解決了,千萬不要抓著邊緣的問題不放。
將瓶頸環節細分為多個順序的流程,用逐個替代的方法來試探瓶頸的核心位置;細分問題使你都問題有更進一步的了解。
做自己能做的和該做的事情,始終面向自己的現實問題;不要嘗試那些應該由廠商解決的問題(例如,自己寫個JDBC驅動)。
他人的方案只供自己參考,解決要靠自己思考;你我應用的情形不同,應用解決方案要在理解他人的方案之後。
觀察新技術,應用新技術;它往往包含了前人對問題解決的思路,只是對你來說不可見。
問題得到解決後,立即罷手,並匯報結果;在現實問題得到解決後,沒有必要花費精力在非核心的問題上,也許它們永遠不會被碰到,不要假想問題讓自己解決。
上述經驗為個人即興的總結,並未有嚴謹的邏輯推導,僅代表我解決技術問題的思路,供你碰到類似問題時參考。