Java的中文字符亂碼問題一直很讓人頭疼。特別是在WEB應用中。網上的分析文章和解決方案都很多,但總是針對某些特定情況的。很多次遇到亂碼問題後, 經過極為辛苦的調試和搜索資料後終於解決,滿以為自己已經掌握了對付這些字符亂碼怪獸的訣竅。可當過段時間,換了個應用或換了個環境,又會碰到那討厭的火 星文,並再次無所適從。於是下決心好好整理一下中文字符編碼問題,以方便自己記憶,也為其他程序員兄弟們提供一份參考。
首先要了解JAVA處理字符的塬理。Java使用UNICODE來存儲字符數據,處理字符時通常有三個步驟:
- 按指定的字符編碼形式,從源輸入流中讀取字符數據
- 以UNICODE編碼形式將字符數據存儲在內存中
- 按指定的字符編碼形式,將字符數據編碼並寫入目的輸出流中。
所以Java處理字符時總是經過了兩次編碼轉換,一次是從指定編碼轉換為UNICODE編碼,一次是從UNICODE編碼轉換為指定編碼。如果在讀入時用 錯誤的形式解碼字符,則內存存儲的是錯誤的UNICODE字符。而從最初文件中讀出的字符數據,到最終在屏幕終端顯示這些字符,期間經過了應用程序的多次 轉換。如果中間某次字符處理,用錯誤的編碼方式解碼了從輸入流讀取的字符數據,或用錯誤的編碼方式將字符寫入輸出流,則下一個字符數據的接收者就會編解碼 出錯,從而導致最終顯示亂碼。
這一點,是我們分析字符編碼問題以及解決問題的指導思想。
好,現在我們開始一只只的解決這些亂碼怪獸。
一、在Java文件中硬編碼中文字符,在eclipse中運行,控制台輸出了亂碼。
例如,我們在Java文件中寫入以下代碼:
String text = “大家好”;
System.out.println(text);
如果我們是在eclipse裡編譯運行,可能看到的結果是類似這樣的亂碼:????。那麼,這是為什麼呢?
我們先來看看整個字符的轉換過程。
1. 在eclipse窗口中輸入中文字符,並保存成UTF-8的JAVA文件。這裡發生了多次字符編碼轉換。不過因為我們相信eclipse的正確性,所以我們不用分析其中的過程,只需要相信保存下的Java文件確實是UTF-8格式。
2. 在eclipse中編譯運行此Java文件。這裡有必要詳細分析一下編譯和運行時的字符編碼轉換。
- 編譯:我們用javac編譯JAVA文件時,javac不會智能到猜出你所要編譯的文件是什麼編碼類型的,所以它需要指定讀取文件所用的編碼類型。默認 javac使用平台缺省的字符編碼類型來解析JAVA文件。平台缺省編碼是操作系統決定的,我們使用的是中文操作系統,語言區域設置通常都是中國大陸,所 以平台缺省編碼類型通常是GBK。這個編碼類型我們可以在JAVA中使用System.getProperty(“file.encoding”)來查 看。所以javac會默認使用GBK來解析JAVA文件。如果我們要改變javac所用的編碼類型,就要加上-encoding參數,如javac -encoding utf-8 Test.Java。
這裡要另外提一下的是eclipse使用的是內置的編譯器,並不能添加參數,如果要為javac添加參數則建議使用ANT來編譯。不過這並非出現亂碼的塬因,因為eclipse可以為每個JAVA文件設置字符編碼類型,而內置編譯器會根據此設置來編譯Java文件。
- 運行:編譯後字符數據會以UNICODE格式存入字節碼文件中。然後eclipse會調用java命令來運行此字節碼文件。因為字節碼中的字符總是 UNICODE格式,所以Java讀取字節碼文件並沒有編碼轉換過程。虛擬機讀取文件後,字符數據便以UNICODE格式存儲在內存中了。
3. 調用System.out.println來輸出字符。這裡又發生了字符編碼轉換。
System.out.println使用了PrintStream類來輸出字符數據至控制台。PrintStream會使用平台缺省的編碼方式來輸出字 符。我們的中文系統上缺省方式為GBK,所以內存中的UNICODE字符被轉碼成了GBK格式,並送到了操作系統的輸出服務中。因為我們操作系統是中文系 統,所以往終端顯示設備上打印字符時使用的也是GBK編碼。如果到這一步,我們的字符其實不再是GBK編碼的話,終端就會顯示出亂碼。
那麼,在eclipse運行帶中文字符的Java文件,控制台顯示了亂碼,是在哪一步轉換錯誤呢?我們一步步來分析。
- 保存Java文件成UTF-8後,如果再次打開你沒有看到亂碼,說明這步是正確的。
- 用eclipse本身來編譯運行Java文件,應該沒有問題。
- System.out.println會把內存中正確的UNICODE字符編碼成GBK,然後發到eclipse的控制台去。等等,我們看到在Run Configuration對話框的Common標簽裡,控制台的字符編碼被設置成了UTF-8!問題就在這裡。System.out.println已經把字符編碼成了GBK,而控制台仍然以UTF-8的格式讀取字符,自然會出現亂碼。
將控制台的字符編碼設置為GBK,亂碼問題解決。
(這裡補充一點:eclipse的控制台編碼是繼承了workspace的設置的,通常控制台編碼裡沒有GBK的選項而且不能輸入。我們可以先在 workspace的編碼設置中輸入GBK,然後在控制台的設置中就可以看到GBK的選項了,設置好後再把workspace的字符編碼設置改回utf- 8就是。)
二、JSP文件中硬編碼中文字符,在浏覽器上顯示亂碼。
我們用eclipse編寫一個JSP頁面,使用tomcat浏覽這個頁面時,整個頁面的中文字符都是亂碼。這是什麼塬因呢?
JSP頁面從編寫到在浏覽器上浏覽,總共有四次字符編解碼。
1. 以某種字符編碼保存JSP文件
2. Tomcat以指定編碼來讀取JSP文件並編譯
3. Tomcat向浏覽器以指定編碼來發送Html內容
4. 浏覽器以指定編碼解析Html內容
這裡的四次字符編解碼,有一次發生錯誤最終顯示的就會是亂碼。我們依次來分析各次的字符編碼是如何設置的。
- 保存JSP文件,這是在編輯器中設置的,比如eclipse中,設置文件字符類型為utf-8。
- JSP文件開頭的《%@ page language=“Java” contentType=“text/Html; charset=utf-8” pageEncoding=“utf-8”%》,其中pageEncoding用來告訴tomcat此文件所用的字符編碼。這個編碼應該與eclipse 保存文件用的編碼一致。Tomcat以此編碼方式來讀取JSP文件並編譯。
- page標簽中的contentType用來設置tomcat往浏覽器發送Html內容所使用的編碼。這個編碼會在HTTP響應頭中指定以通知浏覽器。
- 浏覽器根據HTTP響應頭中指定的字符編碼來解析Html內容。如:
HTTP/1.1 200 OK
Date: Mon, 01 Sep 2008 23:13:31 GMT
Server: apache/2.2.4 (Win32) mod_jk/1.2.26
Vary: Host,Accept-Encoding
Set-CookIE: JAVA2000_STYLE_ID=1; Domain=www.Java2000.Net; Expires=Thu, 03-Nov-2011 09:00:10 GMT; Path=/
Content-Encoding: gzip
Transfer-Encoding: chunked
Content-Type: text/Html;charset=UTF-8
另外,HTML中有個標簽《meta http-equiv=“Content-Type” content=“text/html; charset=UTF-8”》中也指定了charset。不過這個字符編碼只有在當網頁保存在本地作為靜態網頁時有效,因為沒有HTTP頭,所以浏覽器根據此標簽來識別Html內容的編碼方式。
現在在JSP文件中硬編碼出現亂碼的機會比較小了,因為大家都用了如eclipse的編輯器,基本上可以自動保證這幾個編碼設置的正確性。現在更多碰到的是在JSP文件中從其他數據源中讀取中文字符所產生的亂碼問題。
三、在JSP文件中讀取字符文件並在頁面中顯示,中文字符顯示為亂碼。
比如,我們在JSP文件中使用以下代碼:
《%
BufferedReader reader = new BufferedReader(new FileReader(“D:\\test.txt”));
String content = reader.readLine();
reader.close();
%》
《%=content%》
test.txt裡保存的是中文字符,但在浏覽器上看到的亂碼。這是個經常見到的問題。我們繼續用之前的方法一步步來分析輸入和輸出流
1. test.txt是以某種編碼方式保存中文字符,比如UTF-8。
2. BufferedReader直接讀取test.txt的字節內容並以默認方式構造字符串。分析BufferedReader的代碼,我們可以看到 BufferedReader調用了FileReader的read方法,而FileReader又調用了FileInputStream的native 的read方法。所謂native的方法,就是操作系統底層方法。那麼我們操作系統是中文系統,所以FileInputStream默認用GBK方式讀取 文件。因為我們保存test.txt用的是UTF-8,所以在這裡讀取文件內容使用GBK是錯誤的編碼。
3. 《%=content%》其實就是out.print(content),這裡又用到了HTTP的輸出流JSpWriter,於是字符串content又被以JSP的page標簽中指定的UTF-8方式編碼成字節數組被發送到浏覽器端。
4. 浏覽器以HTTP頭中指定的方式解碼字符,這時無論是用GBK還是UTF-8解碼,顯示的都是亂碼。
可見,我們字符編碼轉換在第二步時出錯了,UTF-8的字符串被當做GBK讀入了內存中。
解決這個亂碼問題有兩種方法,一是把test.txt用GBK保存,則FileInputStream能正確讀入中文字符;二是使用InputStreamReader來轉換字符編碼,如:
InputStreamReader sr = new InputStreamReader(new FileInputStream(“D:\\test.txt”),“utf-8”);
BufferedReader reader = new BufferedReader(sr);
這樣,Java就會用utf-8的方式來從文件中讀取字符數據。
另外,我們可以通過在java命令後帶上Dfile.encoding參數來指定虛擬機讀取文件使用的默認字符編碼,例如java -Dfile.encoding=utf-8 Test,這樣,我們在Java代碼裡用System.getProperty(“file.encoding”)取到的值為utf-8。
四、JSP讀取request.getParameter裡的中文參數後,在頁面顯示為亂碼。
在Java的WEB應用中,對request對象裡的parameters的中文處理一直是常見也最難搞的一只大怪獸。經常是剛搞定了這邊,那邊又出了亂 碼。而導致這種復雜性的,主要是此過程中字符編解碼次數非常多,而且無論是浏覽器還是WEB服務器特別是TOMCAT總是不能給我們一個比較滿意的支持。
首先我們來分析用GET方式上傳參數的亂碼情況。
例如我們在浏覽器地址欄輸入以下URL:http://localhost:8080/test/test.JSP?param=大家好
我們的JSP代碼如此處理param這個參數:
《% String text = request.getParameter(“param”); %》
《%=text%》
而就這麼簡單的兩句代碼,我們很有可能在頁面上看到這樣的亂碼:?ó????
網上對處理request.getParamter中的亂碼有很多文章和方法,也都是正確的,只是方法太多讓人一直不明白到底是為什麼。這裡給大家分析一下到底是怎麼一回事。
首先,我們來看看與request對象有哪些相關的編碼設置:
1. JSP文件的字符編碼
2. 請求這個帶參數URL的源頁面的字符編碼
3. IE的高級設置中的選項“總以utf-8方式發送URL地址”
4. TOMCAT的server.XML中配置URIEncoding
5. 函數request.setCharacterEncoding()
6. JS的encodeURIComponent函數與Java的URLDecoder類
這麼多條相關編碼設置,也難怪大家被搞得頭暈了。這裡給大家根據各種情況給大家一一分析一下。見下表:
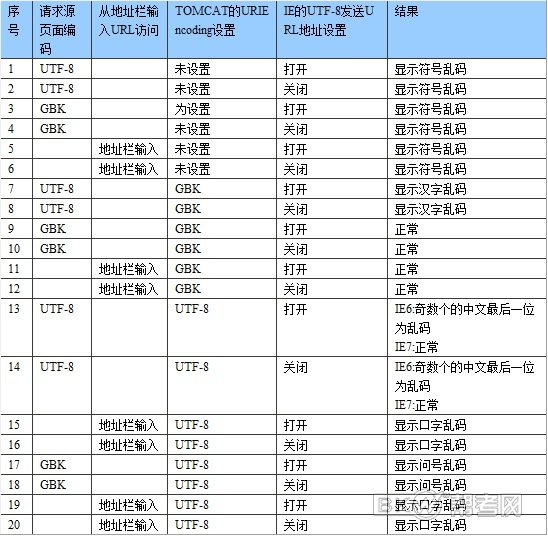
以上表格裡的現象,除了指名在IE7上,其他全是在IE6上測試的結果。
由這個表我們可以看到,IE的“總以utf-8方式發送URL地址”設置並不影響對parameter的解析,而從頁面請求URL和從地址欄輸入URL居然也有不同的表現。
根據這個表列出的現象,大家只要用smartSniff抓幾個網絡包,並稍稍調查一下TOMCAT的源代碼,就可以得出以下結論:
1. IE設置中的“總以utf-8方式發送URL地址”只對URL的PATH部分起作用,對查詢字符串是不起作用的。也就是說,如果勾選了這個選項,那麼類似 http://localhost:8080/test/大家好.JSP?param=大家好這種URL,前一個“大家好”將被轉化成utf-8形式,而後一個並沒有變化。這裡所說的utf-8形式,其實應該叫utf-8+escape形式,即%B4%F3%BC%D2%BA%C3這種形式。
那麼,查詢字符串中的中文字符,到底是用什麼編碼傳送到服務器的呢?答案是系統默認編碼,即GBK。也就是說,在我們中文操作系統上,傳送給WEB服務器的查詢字符串,總是以GBK來編碼的。
2. 在頁面中通過鏈接或location重定向或open新窗口的方式來請求一個URL,這個URL裡面的中文字符是用什麼編碼的?答:是用該頁面的編碼類型。也就是說,如果我們從某個源JSP頁面上的鏈接來訪問http://localhost:8080/test/test.JSp?param=大家好這個URL,如果源JSP頁面的編碼是UTF-8,則大家好這幾個字的編碼就是UTF-8。
而在地址欄上直接輸入URL地址,或者從系統剪貼板粘貼到地址欄上,這個輸入並非從頁面中發起的,而是由操作系統發起的,所以這個編碼只可能是系統的默認 編碼,與任何頁面無關。我們還發現,在不同的浏覽器上,用鏈接方式打開的頁面,如果在地址欄上再敲個回車,顯示的結果也會不同。IE上敲回車後顯示不變 化,而傲游上可能就會有亂碼或亂碼消失的變化。說明IE上敲回車,實際發送的是之前記憶下來的內存中的URL,而傲游上發送的從當前地址欄重新獲取的 URL。
3. TOMCAT的URIEncoding如果不加以設置,則默認使用ISO-8859-1來解碼URL,設置後便用設置了的編碼方式來解碼。這個解碼同時包 括PATH部分和查詢字符串部分。可見,這個參數是對用GET方式傳遞的中文參數最關鍵的設置。不過,這個參數只對GET方式傳遞的參數有效,對POST 的無效。分析TOMCAT的源代碼我們可以看到,在請求一個頁面時,TOMCAT會嘗試構造一個Request對象,在這個對象裡,會從 Server.XML裡讀取URIEncoding的值,並賦值給Parameters類的queryStringEncoding變量,而這個變量將在 解析request.getParameter中的GET參數時用來指導字符解碼。
4. request.setCharacterEncoding函數只對POST的參數有效,對GET的參數無效。且這個函數必須是在第一次調用 request.getParameter之前使用。這是因為Parameters類有兩個字符編碼參數,一個是encoding,另一個是 queryStringEncoding,而setCharacterEncoding設置的是encoding,這個是在解析POST的參數是才用到 的。
所以,這就導致了我們通常都要分開處理POST和GET的字符編碼,用TOMCAT自帶的filter只能處理POST的,另外要設置URIEncoding來設置GET的。這樣很麻煩而且URIEncoding無法根據內容來動態區分編碼,總還是一個問題。
在調查TOMCAT的代碼時發現了另一個在server.XML裡的參數useBodyEncodingForURI,可以解決這個問題。這個參數設成 true後,TOMCAT就會用request.setCharacterEncoding所設置的字符編碼來同樣解析GET參數了。這樣,那個 SetCharacterEncodingFilter就可以同時處理GET和POST參數了。
知道了以上知識後,我們再來分析一下前面表格中列出的幾個典型現象。
第一條,請求源頁面的編碼為UTF-8,而TOMCAT的URIEncoding未指定,則TOMCAT用ISO8859-1方式來解碼參數,所以從request中讀出來後,內存中存儲的為錯誤的UNICODE數據,導致之後到屏幕顯示的所有轉換全部出錯。
第九條,請求源頁面編碼為GBK,而TOMCAT的URIEncoding也為GBK,TOMCAT用GBK方式去解碼塬本用GBK編碼的字符,解碼正確,內存中的UNICODE值正確,最終顯示正確的中文。
第十三條,請求源頁面編碼為UTF-8,TOMCAT的URIEncoding也為UTF-8,而在IE6中最終顯示的中文字符,如果是奇數個數,則最後一個會顯示為亂碼。這是為什麼呢?
我的猜測是,這是因為IE6將URL地址發送時,對查詢字符串是直接對UTF-8格式的字符使用GBK來編碼,而不是對UNICODE的字符來用 GBK編 碼,所以UTF-8的數據沒有經過UNICODE而直接編碼成了GBK。而到了TOMCAT這邊,GBK的編碼又被當成UTF-8做了解碼。所以這個過程 中經過了UTF-8轉換成GBK,然後又從GBK轉換成UTF-8的過程,而這種轉換,恰好就會出現奇數個中文字符串的最後一位為亂碼的現象。而在IE7 中,估計把這種現象當做BUG已經被解決了,即在發送地址時會先轉成UNICODE再編碼成GBK。那麼估計在IE7的浏覽器+中文操作系統環境下,如果 我們把TOMCAT的URIEncoding設置成GBK,無論JSP編碼成什麼格式,都不會出現亂碼。這個沒測試,請大家自己驗證。
其他幾條就不再做分析了,有興趣的大家自己分析。
五、對URL做Encode和Decode
對於request參數的中文亂碼問題,個人覺得最好的還是用URLEncode/URLDecode,因為如果你的WEB站點要支持國際化,最好就是保證從IE遞送過來的參數永遠是正確的UTF-8編碼。
在IE端,我們可以用JS腳本來對參數編碼:encodeURIComponent(),編碼後中文字符便變成了%B4%F3%BC%D2%BA %C3這 種形式。在JAVA端,可以用Java.Net.URLDecoder.decode來解碼。不過這裡要注意一個問題,就是TOMCAT會自動先對URL 做一次decode,我們可以在TOMCAT的UDecoder類中看到這一點。不過TOMCAT並非使用了URLDecoder.decode,而是自 己編寫了一個decode函數。網上有些文章上介紹過一種處理亂碼的方法便是在JS中對參數做兩次encodeURIComponent,在Java中做 一次decode,可以解決一些沒有設置URIEncoding時發生的亂碼問題。不過個人覺得如果弄懂了整個字符編碼轉換的過程,基本上是用不到這種方 法的。
六、從數據庫中讀取中文字符數據,在頁面上顯示為亂碼。
對於數據庫中讀取中文字符出現亂碼的問題,本人遇到的還比較少,所以暫時沒有總結。如果大家有類似的經驗,歡迎補充說明,我一定注明作者身份。
好了,對各種字符亂碼問題的分析就總結到這裡,相信只要把握“以指定編碼讀取--轉換為UNICODE--以指定編碼輸入”這基本步驟,初學者也可以很快 分析出字符亂碼的根源所在。另外我建議不要隨便使用new String(str.getBytes(enc1),enc2)這種方式來強行轉碼,也不要隨便使用網上的字符轉碼函數,我覺得只會把問題隱藏更深更復 雜化。我們應該清晰地分析整個字符流的編解碼過程,自然可以找出亂碼的根源所在,從而保證整個字符流動中,在內存中的UNICODE始終是正確的。