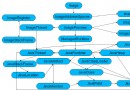
Lucene是一個高性能的Java全文檢索工具包,它使用的是倒排文件索引結構。該結構及相應的生成算法如下:
0)設有兩篇文章1和2
文章1的內容為:Tom lives in Guangzhou,I live in Guangzhou too.
文章2的內容為:He once lived in Shanghai.
1)由於lucene是基於關鍵詞索引和查詢的,首先我們要取得這兩篇文章的關鍵詞,通常我們需要如下處理措施
a.我們現在有的是文章內容,即一個字符串,我們先要找出字符串中的所有單詞,即分詞。英文單詞由於用空格分隔,比較好處理。中文單詞間是連在一起的需要特殊的分詞處理。
b.文章中的”in”, “once” “too”等詞沒有什麼實際意義,中文中的“的”“是”等字通常也無具體含義,這些不代表概念的詞可以過濾掉
c.用戶通常希望查“He”時能把含“he”,“HE”的文章也找出來,所以所有單詞需要統一大小寫。
d.用戶通常希望查“live”時能把含“lives”,“lived”的文章也找出來,所以需要把“lives”,“lived”還原成“live”
e.文章中的標點符號通常不表示某種概念,也可以過濾掉
在lucene中以上措施由Analyzer類完成
經過上面處理後
文章1的所有關鍵詞為:[tom] [live] [guangzhou] [i] [live] [guangzhou]
文章2的所有關鍵詞為:[he] [live] [shanghai]
2) 有了關鍵詞後,我們就可以建立倒排索引了。上面的對應關系是:“文章號”對“文章中所有關鍵詞”。倒排索引把這個關系倒過來,變成:“關鍵詞”對“擁有該關鍵詞的所有文章號”。文章1,2經過倒排後變成
關鍵詞 文章號
guangzhou 1
he 2
i 1
live 1,2
shanghai 2
tom 1
通常僅知道關鍵詞在哪些文章中出現還不夠,我們還需要知道關鍵詞在文章中出現次數和出現的位置,通常有兩種位置:a)字符位置,即記錄該詞是文章中第幾個字符(優點是關鍵詞亮顯時定位快);b)關鍵詞位置,即記錄該詞是文章中第幾個關鍵詞(優點是節約索引空間、詞組(phase)查詢快),lucene中記錄的就是這種位置。
加上“出現頻率”和“出現位置”信息後,我們的索引結構變為:
關鍵詞 文章號[出現頻率] 出現位置
guangzhou 1 3,6
he 2 1
i 1 4
live 1,2 2,5,2
shanghai 2 3
tom 1 1
以live 這行為例我們說明一下該結構:live在文章1中出現了2次,文章2中出現了一次,它的出現位置為“2,5,2”這表示什麼呢?我們需要結合文章號和出現頻率來分析,文章1中出現了2次,那麼“2,5”就表示live在文章1中出現的兩個位置,文章2中出現了一次,剩下的“2”就表示live是文章2中第 2個關鍵字。
以上就是lucene索引結構中最核心的部分。我們注意到關鍵字是按字符順序排列的(lucene沒有使用B樹結構),因此lucene可以用二元搜索算法快速定位關鍵詞。
實現時 lucene將上面三列分別作為詞典文件(Term Dictionary)、頻率文件(frequencIEs)、位置文件 (positions)保存。其中詞典文件不僅保存有每個關鍵詞,還保留了指向頻率文件和位置文件的指針,通過指針可以找到該關鍵字的頻率信息和位置信息。
Lucene中使用了field的概念,用於表達信息所在位置(如標題中,文章中,url中),在建索引中,該field信息也記錄在詞典文件中,每個關鍵詞都有一個field信息(因為每個關鍵字一定屬於一個或多個fIEld)。
為了減小索引文件的大小,Lucene對索引還使用了壓縮技術。首先,對詞典文件中的關鍵詞進行了壓縮,關鍵詞壓縮為<前綴長度,後綴>,例如:當前詞為“阿拉伯語”,上一個詞為“阿拉伯”,那麼“阿拉伯語”壓縮為<3,語>。其次大量用到的是對數字的壓縮,數字只保存與上一個值的差值(這樣可以減小數字的長度,進而減少保存該數字需要的字節數)。例如當前文章號是16389(不壓縮要用3個字節保存),上一文章號是16382,壓縮後保存7(只用一個字節)。
下面我們可以通過對該索引的查詢來解釋一下為什麼要建立索引。
假設要查詢單詞 “live”,lucene先對詞典二元查找、找到該詞,通過指向頻率文件的指針讀出所有文章號,然後返回結果。詞典通常非常小,因而,整個過程的時間是毫秒級的。
而用普通的順序匹配算法,不建索引,而是對所有文章的內容進行字符串匹配,這個過程將會相當緩慢,當文章數目很大時,時間往往是無法忍受的。