介紹
Java平台在java.net包裡來實現Socket。在這本文中,我們將使用Java.Net包中的下面三個類來工作:
·URLConnection
·Socket
·ServerSocket
在Java.Net包裡包含有更多的類,但是這些是你最經常遇見的,讓我們從URLConnection開始,這個類提供了在你的Java代碼裡使用Socket的方法而無需了解Socket的底層機制。
甚至不用嘗試就可以使用sockets
連接到一個URL包括以下幾個步驟:
·創建一個URLConnection
·用不同的setter方法配置它
·連接到URLConnection
·與不同的getter方法進行交互
下面,我們來用一些例子示范怎樣使用URLConnection從一台服務器上請求一份文檔。
URLClIEnt類
我們將從URLClIEnt類的結構開始講起。
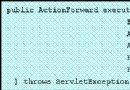
import java.io.*; import Java.Net.*; public class URLClIEnt { protected URLConnection connection; public static void main(String[] args) {} public String getDocumentAt(String urlString) {} }
注意:必須要先導入Java.Net和Java.io包才行
我們給我們的類一個實例變量用於保存一個URLConnection
我們的類包含一個main()方法用於處理浏覽一個文檔的邏輯流(logic flow),我們的類還包含了getDocumentAt()方法用於連接服務器以及請求文檔,下面我們將探究這些方法的細節。
浏覽文檔
main()方法用於處理浏覽一個文檔的邏輯流(logic flow):
public static void main(String[] args) { URLClient client = new URLClient(); String yahoo = clIEnt.getDocumentAt("http://www.yahoo.com"); System.out.println(yahoo); }
我們的main()方法僅僅創建了一個新的URLClIEnt類的實例並使用一個有效的URL String來調用getDocumentAt()方法。當調用返回文檔,我們把它儲存在一個String裡並把這個String輸出到控制台上。然而,實際的工作是getDocumentAt()方法當中完成的。
從服務器上請求一份文檔
getDocumentAt()方法處理在實際工作中如何從web上得到一份文檔:
public String getDocumentAt(String urlString) { StringBuffer document = new StringBuffer(); try { URL url = new URL(urlString); URLConnection conn = url.openConnection(); BufferedReader reader = new BufferedReader(new InputStreamReader(conn.getInputStream())); String line = null; while ((line = reader.readLine()) != null) document.append(line + "\n"); reader.close(); } catch (MalformedURLException e) { System.out.println("Unable to connect to URL: " + urlString); } catch (IOException e) { System.out.println("IOException when connecting to URL: " + urlString); } return document.toString(); }
getDocumentAt()方法有一個String類型的參數包含我們想得到的那份文檔的URL。我們先創建一個StringBuffer用於保存文檔的行。接著,我們用傳進去的參數urlString來創建一個新的URL。然後,我們創建一個URLConnection並打開它:
URLConnection conn = url.openConnection();
一旦有了一個URLConnection,我們就獲得它的InputStream並包裝成InputStreamReader,然後我們又把它進而包裝成BufferedReader以至於我們能夠讀取從服務器獲得的文檔的行,我們在Java代碼中處理socket的時候會經常使用這種包裝技術。在我們繼續學習之前你必須熟悉它:
BufferedReader reader =new BufferedReader(new InputStreamReader(conn.getInputStream()));
有了BufferedReader,我們能夠容易的讀取文檔的內容。我們在一個while...loop循環裡調用reader上的readline()方法:
String line = null;
while ((line = reader.readLine()) != null)
document.append(line + "\n");
調用readLine()方法後從InputStream傳入行終止符(例如換行符)時才產生阻塞。如果沒有得到,它將繼續等待,當連接關閉時它才會返回null,既然這樣,一旦我們獲得一個行,我們連同一個換行符把它追加到一個調用的文檔的StringBuffer上。這樣就保留了從服務器上原文檔的格式。
當我們讀取所有行以後,我們應該關閉BufferedReader:
reader.close();
如果提供給urlString的URL構造器無效,則將會拋出一個MalformedUR特拉LException異常。同樣如果產生了其他的錯誤,例如從連接獲取InputStream時,將會拋出IOException。
總結
1.用一個你想連接的資源的有效的url String來實例化URL
2.連接到指定URL
3.包裝InputStream為連接在BufferedReader以至於你可以讀取行
4.用你的BufferedReader讀取文檔內容
5.關閉BufferedReader