二、 改進異常處理能力
在JDBC API 4.0以前的版本中,異常處理功能極其有限。對於所有類型的錯誤都會籠統地拋出一個SQLException異常-根本不存在異常的詳細分類,且沒有相應的層次定義。所以這時,你唯一能夠得到一些有意義的信息的辦法是檢索和分析SQLState值。另一方面,SQLState值及其相應的含義會因不同的數據源而有所改變;因此,要想追蹤到問題的"根部"並且有效地處理異常是一件非常乏味的任務。
JDBC 4.0改進了異常處理能力,同時也緩解了一些前面提到的問題。其中的關鍵改進有:
· 把SQLException分成短暫異常和非短暫異常兩種類型
· 支持鏈式異常
· 實現Iterable接口
當一個以前失敗的操作檢索成功時,將會拋出SQLTransientException異常;而在檢索不成功時將會拋出SQLNonTransIEntException異常-除非導致SQLException的原因得到糾正。
圖1展示了子類SQLTransientException和SQLNonTransIEntException。
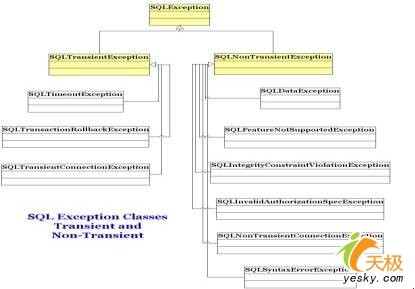
圖1.SQL異常類型:短暫型和非短暫型
另一方面,在新的API中,加入了對鏈式異常的支持。新的異常基類構造器中添加了額外參數以捕獲異常的可能原因。例如,在一個循環中可能存在SQLException遍歷;這時,開發人員可以調用getCause()來決定異常的可能原因。如果獲取的結果的確是產生這些異常的原因,那麼getCause()方法能夠返回一個非SQLException。
現在,SQLException類實現了Iterable接口並且支持J2SE 5.0的for each循環。
列表2描述了新的for-each-loop結構的用法:
列表2.For each循環結構
catch(SQLException ex) {
for(Throwable t : ex) {
System.out.println("exception:" + t);
}
}
三、 支持XML數據類型
如今,大量的數據行以XML格式存在。通過在SQL 2003規范中定義了一種標准XML類型,現在大多數數據庫都已提供對XML數據類型的支持。通過加入這樣一種數據類型,一個XML數據集或文檔可能成為一個數據庫表中的一行的一個字段或列值。在JDBC 4.0以前,也許在JDBC框架內操作這樣的數據的最好的方法是使用來自於驅動程序供應商的專利擴展產品或作為一種CLOB類型來存取它。
現在,JDBC 4.0把SQLXML定義為映射數據庫SQL XML類型的Java數據類型。這種API支持把一個XML類型作為一個字符串或作為一個StAX流進行處理。Streaming API for XML(在JSR 173規范中確立)基於Iterator模式,它與基於Observer模式的Simple API for XML Processing(SAX)形成對照。
調用Connection對象的createSQLXML()方法就能夠創建一個SQLXML對象。開始時這是一個空對象;因此,通過使用setString()方法或createXMLStreamWriter()方法把一個XML流關聯到該對象可以把數據依附到其上。同樣,XML數據可以從一個SQLXML對象中進行檢索,這是通過使用getString()或createXMLStreamReader()方法把一個XML流與該對象關聯實現的。
ResultSet,PreparedStatement和CallableStatement接口中都提供了getSQLXML()方法用於檢索SQLXML數據類型。另外,PreparedStatement和CallableStatement中還引入了setSQLXML()方法用於把SQLXML對象作為參數添加。
當對象在長時間運行的事務中保持有效時,可以通過調用上面這些接口的free()方法來釋放SQLXML資源;事實證明這是一種比較適當的方法。另外,開發者可以在一個數據源上調用DatabaseMetaData的getTypeInfo()方法來檢查數據庫是否支持SQLXML數據類型,因為這個方法能夠返回它支持的所有數據類型。
四、 改進Connection接口
Connection接口定義也得到了增強,用於更高效地分析連接狀態。
有時數據庫連接是不可用的,盡管可能不必關閉這些連接並對之進行垃圾回收。處於這樣的情況下,數據庫常常表現出速度緩慢且不具有響應性。此時,在大多數情況下,重新初始化該連接也許是解決這種問題的唯一方法。在JDBC 4.0以前版本時,沒有辦法來區分一個舊連接和一個已經關閉的連接;而新式API則在Connection接口中添加了一個isValid()方法用來查詢是否連接仍然有效。
另外,數據庫連接經常在客戶端被共享;並且有時,一些客戶使用的資源比另一些客戶多,這可能會導致一種"饑餓"現象。為此,Connection接口中定義了一個setClIEntInfo()方法以定義客戶端特定的屬性,這可以被客戶端用於分析和監控資源利用情況。
五、 有關RowId方面的改進
在許多數據庫中,RowId都被用作唯一標識一個表中行的方法。在查詢條件中使用RowId往往是檢索數據的最快方法,特別是在Oracle和DB2數據庫情況下。現在,既然java.sql.RowId是一種內嵌的Java類型;那麼,你就可以充分利用與其用法相關的性能優點。當表中存在重復的數據並且一些行數據相同時,RowId是標識唯一行的最有效的方法。然而,還要注意到,RowId在一個表中是唯一的,而對於整個數據庫來說並非如此;它們可能發生變化並且不為所有數據庫所支持。典型情況下,RowId不是跨數據源可移植的;因此,當使用多種數據源時應該慎重。
在數據源定義的生命周期內,只要一行未被刪除,那麼該行相應的RowId就一直保持有效。我們可以調用DatabaseMetadata.getRowIdLifetime()方法來決定RowId的生命周期。這個方法的返回類型是一個枚舉類型。現在,把所有這些枚舉類型總結到如下的表格中。
RowIdLifetime枚舉類型
定義
ROWID_UNSUPPORTED
數據源不支持RowId類型
ROWID_VALID_OTHER
實現依賴的生命周期
ROWID_VALID_TRANSACTION
生命周期至少包含事務
ROWID_VALID_SESSION
生命周期至少包含會話
ROWID_VALID_FOREVER
無限制生命周期
其中,只要沒有刪除行,那麼ROWID_VALID_TRANSACTION,ROWID_VALID_SESSION和ROWID_VALID_FOREVER都定義為true。還要注意的是,如果一個行被刪除和重新插入,那麼RowId會被重新調整(這有可能在數據源中透明實現)。作為一個例子,在Oracle中,如果在一個分區表上設置"enable row movement"語句,並且分區鍵的一個更新導致該行從一個分區移動到另一個分區,那麼RowId將改變。即使在沒有設置"enable row movement"標志並且"alter table table_name"發生改變時,RowId也能夠改變。
ResultSet和CallableStatement接口都被更新-都包括了一個返回Javax.sql.RowId類型的方法getRowID()。
列表3展示了如何從一個ResultSet和CallableStatement中檢索RowId。
列表3.得到RowId
//從一個ResultSet檢索RowId的方法簽名:
RowId getRowId (int columnIndex)
RowId getRowId (String columnName)
...
Statement stmt = con.createStatement ();
ResultSet rs = stmt. ExecuteQuery (…);
while (rs.next ()) {
...
Java.sql.RowId rid = rs.getRowId (1);
...
}
//從一個CallableStatement檢索RowId的方法簽名:
RowId getRowId (int parameterIndex)
RowId getRowId (String parameterName)
Connection con;
...
CallableStatement cstmt = con.prepareCall (…);
...
cstmt.registerOutParameter (2, Types.ROWID);
...
cstmt.executeUpdate ();
...
Java.sql.RowId rid = cstmt.getRowId (2);
在此,RowId可以用於唯一地參考一行並因此可被用於檢索或更新行數據。當使用RowId參考來存取或更新數據時,理解生命周期的有效性是十分重要的,從而保證結果的連續性。另外,我還建議你同時使用另一個參考,例如主鍵,以避免在能夠透明地改變RowId的情況下出現不連續的結果。
RowId值還可以被設置或更新。在一種可更新的ResultSet情況下,可以針對表中的一個特定的行使用updateRowId()方法來更新RowId。
另外,PreparedStatement和CallableStatement接口都支持setRowId()方法(其形式不一樣),該方法把RowId設置為一個參數值。這個值可以用於針對表中的一個特定的行來參考數據行或更新RowId值。
由上面可知,開發者可以非常容易地設置或更新RowId;這為控制唯一的行標識符並為使這些標識符具有跨表唯一性提供了極大的靈活性。也許,跨表支持的數據源的RowId的可移植性還能夠通過在這些數據源間顯式地設置一致值來實現。然而,因為系統生成的RowId經常是有效的,並且可以通過透明的操作來改變RowId;所以,最好在一個應用程序中把它們用作只讀屬性。
六、 利用非標准供應商實現的資源
新型的JDBC API中定義了一個Java.sql.Wrapper接口。通過檢索代理實例並使用相應的包裝代理實例,這個接口提供了存取數據源供應商特定資源的能力。
這個包裝接口擁有17個子接口,並且包括Connection,ResultSet,Statement,CallableStatement,PreparedStatement,DataSource,DatabaseMetaData和ResultSetMetaData,等等。這是一種優秀的設計,因為它方便了在創建查詢和"結果-設置-檢索"生命周期的幾乎每一個階段使用數據源供應商特定的資源。
unwrap()方法返回實現給定接口的對象,從而允許存取供應商特定的方法。isWrapperFor()方法返回一個Boolean值-如果它實現了該接口則返回true;或者,它也有可能直接或間接地成為對象的一個包裝類。
作為一個例子,當使用Oracle時,Oracle JDBC驅動程序提供了更新批擴展-與標准JDBC批更新機制相比,它具有更好的性能且更為有效。對於早期的JDBC版本來說,這意味著要在代碼中使用Oracle特定的定義,例如OraclePreparedStatement。這樣以來就減弱了代碼的可移植性。而借助於現在新型的API,許多前面這些有效的實現都能夠被包裝和被暴露在標准JDBC定義中。
七、 針對驅動程序加載的服務提供者機制
在JDBC 4.0以前,在一種非托管的或獨立的程序中,你必須顯式地通過調用Class.forName方法來加載JDBC驅動器類,如列表4所示:
列表4.Class.forName方法
Class.forName ("com.driverprovider.jdbc.jdbcDriverImpl");
借助於JDBC 4.0,如果JDBC驅動程序供應商把他們的驅動程序打包為服務(在服務提供者機制下定義為每一種JAR規范),那麼DriverManager代碼將通過在classpath中搜索它來隱式地裝載該驅動程序。這種機制的優點在於,開發者不需要了解這種特定的驅動程序類,並且能夠使用JDBC來編寫較少的代碼實現。另外,既然驅動程序類名不再存在於代碼中,那麼只改變一個名字並不要求重新編譯。如果在classpath中指定了多個驅動程序,那麼DriverManger將試圖使用它在classpath中所找到的第一個驅動程序來創建一種連接,並且在需要時能夠繼續遍歷下一個驅動程序。
八、 結論
在本文中,我們一同探討了JDBC 4.0的一些新的和改進的特征。從中可以看出,許多新特征進一步便利了開發,從而提高了開發者的生產效率。另一方面,該規范並沒有消除對於其它JDBC框架提供的模板化工具和高級異常處理能力的使用。然而,對該規范也存在一些批評。例如,一些人認為注釋的使用會導致在代碼中硬編碼(而這往往導致在代碼維護階段出現問題)。究其實效,還有待於實踐檢驗。