在執行一個異步任務或並發任務時,往往是通過直接new Thread()方法來創建新的線程,這樣做弊端較多,更好的解決方案是合理地利用線程池,線程池的優勢很明顯,如下:
Java API針對不同需求,利用Executors類提供了4種不同的線程池:newCachedThreadPool, newFixedThreadPool, newScheduledThreadPool, newSingleThreadExecutor,接下來講講線程池的用法。
創建一個可緩存的無界線程池,該方法無參數。當線程池中的線程空閒時間超過60s則會自動回收該線程,當任務超過線程池的線程數則創建新線程。線程池的大小上限為Integer.MAX_VALUE,可看做是無限大。
public void cachedThreadPoolDemo(){
ExecutorService cachedThreadPool = Executors.newCachedThreadPool();
for (int i = 0; i < 5; i++) {
final int index = i;
cachedThreadPool.execute(new Runnable() {
@Override
public void run() {
System.out.println(Thread.currentThread().getName()+", index="+index);
}
});
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
運行結果:
pool-1-thread-1, index=0
pool-1-thread-1, index=1
pool-1-thread-1, index=2
pool-1-thread-1, index=3
pool-1-thread-1, index=4
從運行結果可以看出,整個過程都在同一個線程pool-1-thread-1中運行,後面線程復用前面的線程。
創建一個固定大小的線程池,該方法可指定線程池的固定大小,對於超出的線程會在LinkedBlockingQueue隊列中等待。
public void fixedThreadPoolDemo(){
ExecutorService fixedThreadPool = Executors.newFixedThreadPool(3);
for (int i = 0; i < 6; i++) {
final int index = i;
fixedThreadPool.execute(new Runnable() {
@Override
public void run() {
System.out.println(Thread.currentThread().getName()+", index="+index);
}
});
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
運行結果:
pool-1-thread-1, index=0
pool-1-thread-2, index=1
pool-1-thread-3, index=2
pool-1-thread-1, index=3
pool-1-thread-2, index=4
pool-1-thread-3, index=5
從運行結果可以看出,線程池大小為3,每休眠1s後將任務提交給線程池的各個線程輪番交錯地執行。線程池的大小設置,可參數Runtime.getRuntime().availableProcessors()。
創建一個只有線程的線程池,該方法無參數,所有任務都保存隊列LinkedBlockingQueue中,等待唯一的單線程來執行任務,並保證所有任務按照指定順序(FIFO或優先級)執行。
public void singleThreadExecutorDemo(){
ExecutorService singleThreadExecutor = Executors.newSingleThreadExecutor();
for (int i = 0; i < 3; i++) {
final int index = i;
singleThreadExecutor.execute(new Runnable() {
@Override
public void run() {
System.out.println(Thread.currentThread().getName()+", index="+index);
}
});
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
運行結果:
pool-1-thread-1, index=0
pool-1-thread-1, index=1
pool-1-thread-1, index=2
從運行結果可以看出,所有任務都是在單一線程運行的。
創建一個可定時執行或周期執行任務的線程池,該方法可指定線程池的核心線程個數。
public void scheduledThreadPoolDemo(){
ScheduledExecutorService scheduledThreadPool = Executors.newScheduledThreadPool(3);
//定時執行一次的任務,延遲1s後執行
scheduledThreadPool.schedule(new Runnable() {
@Override
public void run() {
System.out.println(Thread.currentThread().getName()+", delay 1s");
}
}, 1, TimeUnit.SECONDS);
//周期性地執行任務,延遲2s後,每3s一次地周期性執行任務
scheduledThreadPool.scheduleAtFixedRate(new Runnable() {
@Override
public void run() {
System.out.println(Thread.currentThread().getName()+", every 3s");
}
}, 2, 3, TimeUnit.SECONDS);
}
運行結果:
pool-1-thread-1, delay 1s
pool-1-thread-1, every 3s
pool-1-thread-2, every 3s
pool-1-thread-2, every 3s
...
ScheduledExecutorService功能強大,對於定時執行的任務,建議多采用該方法。
上述4個方法的參數對比,如下:
其他參數都相同,其中線程工廠的默認類為DefaultThreadFactory,線程飽和的默認策略為ThreadPoolExecutor.AbortPolicy。
Executors類提供4個靜態工廠方法:newCachedThreadPool()、newFixedThreadPool(int)、newSingleThreadExecutor和newScheduledThreadPool(int)。這些方法最終都是通過ThreadPoolExecutor類來完成的,這裡強烈建議大家直接使用Executors類提供的便捷的工廠方法,能完成絕大多數的用戶場景,當需要更細節地調整配置,需要先了解每一項參數的意義。
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
Executors.defaultThreadFactory(), defaultHandler);
}
創建線程池,在構造一個新的線程池時,必須滿足下面的條件:
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}
參數說明:
corePoolSize(線程池基本大小):當向線程池提交一個任務時,若線程池已創建的線程數小於corePoolSize,即便此時存在空閒線程,也會通過創建一個新線程來執行該任務,直到已創建的線程數大於或等於corePoolSize時,才會根據是否存在空閒線程,來決定是否需要創建新的線程。除了利用提交新任務來創建和啟動線程(按需構造),也可以通過 prestartCoreThread() 或 prestartAllCoreThreads() 方法來提前啟動線程池中的基本線程。
maximumPoolSize(線程池最大大小):線程池所允許的最大線程個數。當隊列滿了,且已創建的線程數小於maximumPoolSize,則線程池會創建新的線程來執行任務。另外,對於無界隊列,可忽略該參數。
keepAliveTime(線程存活保持時間):默認情況下,當線程池的線程個數多於corePoolSize時,線程的空閒時間超過keepAliveTime則會終止。但只要keepAliveTime大於0,allowCoreThreadTimeOut(boolean) 方法也可將此超時策略應用於核心線程。另外,也可以使用setKeepAliveTime()動態地更改參數。
unit(存活時間的單位):時間單位,分為7類,從細到粗順序:NANOSECONDS(納秒),MICROSECONDS(微妙),MILLISECONDS(毫秒),SECONDS(秒),MINUTES(分),HOURS(小時),DAYS(天);
threadFactory(線程工廠):用於創建新線程。由同一個threadFactory創建的線程,屬於同一個ThreadGroup,創建的線程優先級都為Thread.NORM_PRIORITY,以及是非守護進程狀態。threadFactory創建的線程也是采用new Thread()方式,threadFactory創建的線程名都具有統一的風格:pool-m-thread-n(m為線程池的編號,n為線程池內的線程編號);
排隊有三種通用策略:
BlockingQueue的插入/移除/檢查這些方法,對於不能立即滿足但可能在將來某一時刻可以滿足的操作,共有4種不同的處理方式:第一種是拋出一個異常,第二種是返回一個特殊值(null 或 false,具體取決於操作),第三種是在操作可以成功前,無限期地阻塞當前線程,第四種是在放棄前只在給定的最大時間限制內阻塞。如下表格:
實現BlockingQueue接口的常見類如下:
ArrayBlockingQueue:基於數組的有界阻塞隊列。隊列按FIFO原則對元素進行排序,隊列頭部是在隊列中存活時間最長的元素,隊尾則是存在時間最短的元素。新元素插入到隊列的尾部,隊列獲取操作則是從隊列頭部開始獲得元素。 這是一個典型的“有界緩存區”,固定大小的數組在其中保持生產者插入的元素和使用者提取的元素。一旦創建了這樣的緩存區,就不能再增加其容量。試圖向已滿隊列中放入元素會導致操作受阻塞;試圖從空隊列中提取元素將導致類似阻塞。ArrayBlockingQueue構造方法可通過設置fairness參數來選擇是否采用公平策略,公平性通常會降低吞吐量,但也減少了可變性和避免了“不平衡性”,可根據情況來決策。
LinkedBlockingQueue:基於鏈表的無界阻塞隊列。與ArrayBlockingQueue一樣采用FIFO原則對元素進行排序。基於鏈表的隊列吞吐量通常要高於基於數組的隊列。
SynchronousQueue:同步的阻塞隊列。其中每個插入操作必須等待另一個線程的對應移除操作,等待過程一直處於阻塞狀態,同理,每一個移除操作必須等到另一個線程的對應插入操作。SynchronousQueue沒有任何容量。不能在同步隊列上進行 peek,因為僅在試圖要移除元素時,該元素才存在;除非另一個線程試圖移除某個元素,否則也不能(使用任何方法)插入元素;也不能迭代隊列,因為其中沒有元素可用於迭代。Executors.newCachedThreadPool使用了該隊列。
PriorityBlockingQueue:基於優先級的無界阻塞隊列。優先級隊列的元素按照其自然順序進行排序,或者根據構造隊列時提供的 Comparator 進行排序,具體取決於所使用的構造方法。優先級隊列不允許使用 null 元素。依靠自然順序的優先級隊列還不允許插入不可比較的對象(這樣做可能導致 ClassCastException)。雖然此隊列邏輯上是無界的,但是資源被耗盡時試圖執行 add 操作也將失敗(導致 OutOfMemoryError)。
調用線程池的shutdown()或shutdownNow()方法來關閉線程池
中斷采用interrupt方法,所以無法響應中斷的任務可能永遠無法終止。但調用上述的兩個關閉之一,isShutdown()方法返回值為true,當所有任務都已關閉,表示線程池關閉完成,則isTerminated()方法返回值為true。當需要立刻中斷所有的線程,不一定需要執行完任務,可直接調用shutdownNow()方法。
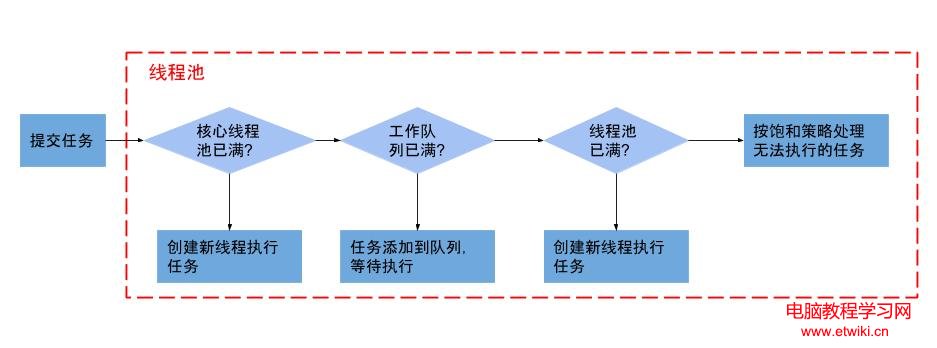
需要針對具體情況而具體處理,不同的任務類別應采用不同規模的線程池,任務類別可劃分為CPU密集型任務、IO密集型任務和混合型任務。
利用線程池提供的參數進行監控,參數如下:
通過擴展線程池進行監控:繼承線程池並重寫線程池的beforeExecute(),afterExecute()和terminated()方法,可以在任務執行前、後和線程池關閉前自定義行為。如監控任務的平均執行時間,最大執行時間和最小執行時間等。