在這篇文章裡我將教會你如何分析JVM的線程堆棧以及如何從堆棧信息中找出問題的根因。在我看來線程堆棧分析技術是Java EE產品支持工程師所必須掌握的一門技術。在線程堆棧中存儲的信息,通常遠超出你的想象,我們可以在工作中善加利用這些信息。
我的目標是分享我過去十幾年來在線程分析中積累的知識和經驗。這些知識和經驗是在各種版本的JVM以及各廠商的JVM供應商的深入分析中獲得的,在這個過程中我也總結出大量的通用問題模板。
那麼,准備好了麼,現在就把這篇文章加入書簽,在後續幾周中我會給大家帶來這一系列的專題文章。還等什麼,請趕緊給你的同事和朋友分享這個線程分析培訓計劃吧。
聽上去是不錯,我確實是應該提升我的線程堆棧分析技能…但我要從哪裡開始呢?
我的建議是跟隨我來完成這個線程分析培訓計劃。下面是我們會覆蓋到的培訓內容。同時,我會把我處理過的實際案例分享給大家,以便與大家學習和理解。
1) 線程堆棧概述及基礎知識
2) 線程堆棧的生成原理以及相關工具
3) 不同JVM線程堆棧的格式的差異(Sun HotSpot、IBM JRE、Oracal JRockit)
4) 線程堆棧日志介紹以及解析方法
5) 線程堆棧的分析和相關的技術
6) 常見的問題模板(線程竟態、死鎖、IO調用掛死、垃圾回收/OutOfMemoryError問題、死循環等)
7) 線程堆棧問題實例分析
我希望這一系列的培訓能給你帶來確實的幫助,所以請持續關注每周的文章更新。
但是如果我在學習過程中有疑問或者無法理解文章中的內容該怎麼辦?
不用擔心,把我當做你的導師就好。任何關於線程堆棧的問題都可以咨詢我(前提是問題不能太low)。請隨意選擇下面的幾種方式與我取得聯系:
1) 直接本文下面發表評論(不好意思的話可以匿名)
2) 將你的線程堆棧數據提交到Root Cause Analysis forum
3) 發Email給我,地址是 @phcharbonneau@hotmail.com
能幫我分析我們產品上遇到的問題麼?
當然可以,如果你願意的話可以把你的堆棧現場數據通過郵件或論壇 Root Cause Analysis forum發給我。處理實際問題是才是學習提升技能的王道。
我真心期望大家能夠喜歡這個培訓。所以我會盡我所能去為你提供高質量的材料,並回答大家的各種問題。
在介紹線程堆棧分析技術和問題模式之前,先要給大家講講基礎的內容。所以在這篇帖子裡,我將先覆蓋到最基本的內容,這樣大家就能更好的去理解JVM、中間件、以及Java EE容器之間的交互。
Java VM 概述
Java虛擬機是Jave EE 平台的基礎。它是中間件和應用程序被部署和運行的地方。
JVM向中間件軟件和你的Java/Java EE程序提供了下面這些東西:
– (二進制形式的)Java / Java EE 程序運行環境
– 一些程序功能特性和工具 (IO 基礎設施,數據結構,線程管理,安全,監控 等等.)
– 借助垃圾回收的動態內存分配與管理
你的JVM可以駐留在許多的操作系統 (Solaris, AIX, Windows 等等.)之上,並且能根據你的物理服務器配置,你可以在每台物理/虛擬服務器上安裝1到多個JVM進程.
JVM與中間件之間的交互
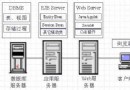
下面這張圖展示了JVM、中間件和應用程序之間的高層交互模型。
圖中展示的JVM、中間件和應用程序件之間的一些簡單和典型的交互。如你所見,標准Java EE應用程序的線程的分配實在中間件內核與JVM之間完成的。(當然也有例外,應用程序可以直接調用API來創建線程,這種做法並不常見,而且在使用的過程中也要特別的小心)
同時,請注意一些線程是由JVM內部來進行管理的,典型的例子就是垃圾回收線程,JVM內部使用這個線程來做並行的垃圾回收處理。
因為大多數的線程分配都是由Java EE容器完成的,所以能夠理解和認識線程堆棧跟蹤,並能從線程堆棧數據中識別出它來,對你而言很重要. 這可以讓你能夠快速的知道Java EE容器正要執行的是什麼類型的請求.
從一個線程轉儲堆棧的分析角度來看,你將能了解從JVM發現的線程池之間的不同,並識別出請求的類型.
最後一節會向你提供對於HotSop VM而言什麼是JVM線程堆棧的一個概述,還有你將會遇到的各種不同的線程. 而對 IBM VM 線程堆棧形式詳細內容將會在第四節向你提供.
請注意你可以從根本原因分析論壇獲得針對本文的線程堆棧示例.
JVM 線程堆棧——它是什麼?
JVM線程堆棧是一個給定時間的快照,它能向你提供所有被創建出來的Java線程的完整清單.
每一個被發現的Java線程都會給你如下信息:
– 線程的名稱;經常被中間件廠商用來識別線程的標識,一般還會帶上被分配的線程池名稱以及狀態 (運行,阻塞等等.)
– 線程類型 & 優先級,例如 : daemon prio=3 ** 中間件程序一般以後台守護的形式創建他們的線程,這意味著這些線程是在後台運行的;它們會向它們的用戶提供服務,例如:向你的Java EE應用程序 **
– Java線程ID,例如 : tid=0x000000011e52a800 ** 這是通過 java.lang.Thread.getId() 獲得的Java線程ID,它常常用自增長的長整形 1..n** 實現
– 原生線程ID,例如 : nid=0x251c** ,之所以關鍵是因為原生線程ID可以讓你獲得諸如從操作系統的角度來看那個線程在你的JVM中使用了大部分的CPU時間等這樣的相關信息. **
– Java線程狀態和詳細信息,例如: waiting for monitor entry [0xfffffffea5afb000] java.lang.Thread.State: BLOCKED (on object monitor)
** 可以快速的了解到線程狀態極其當前阻塞的可能原因 **
– Java線程棧跟蹤;這是目前為止你能從線程堆棧中找到的最重要的數據. 這也是你花費最多分析時間的地方,因為Java棧跟蹤向提供了你將會在稍後的練習環節了解到的導致諸多類型的問題的根本原因,所需要的90%的信息。
– Java 堆內存分解; 從HotSpot VM 1.6版本開始,在線程堆棧的末尾處可以看到HotSpot的內存使用情況,比如說Java的堆內存(YoungGen, OldGen) & PermGen 空間。這個信息對分析由於頻繁GC而引起的問題時,是很有用的。你可以使用已知的線程數據或模式做一個快速的定位。
Heap
PSYoungGen total 466944K, used 178734K [0xffffffff45c00000, 0xffffffff70800000, 0xffffffff70800000)
eden space 233472K, 76% used [0xffffffff45c00000,0xffffffff50ab7c50,0xffffffff54000000)
from space 233472K, 0% used [0xffffffff62400000,0xffffffff62400000,0xffffffff70800000)
to space 233472K, 0% used [0xffffffff54000000,0xffffffff54000000,0xffffffff62400000)
PSOldGen total 1400832K, used 1400831K [0xfffffffef0400000, 0xffffffff45c00000, 0xffffffff45c00000)
object space 1400832K, 99% used [0xfffffffef0400000,0xffffffff45bfffb8,0xffffffff45c00000)
PSPermGen total 262144K, used 248475K [0xfffffffed0400000, 0xfffffffee0400000, 0xfffffffef0400000)
object space 262144K, 94% used [0xfffffffed0400000,0xfffffffedf6a6f08,0xfffffffee0400000)
線程堆棧信息大拆解
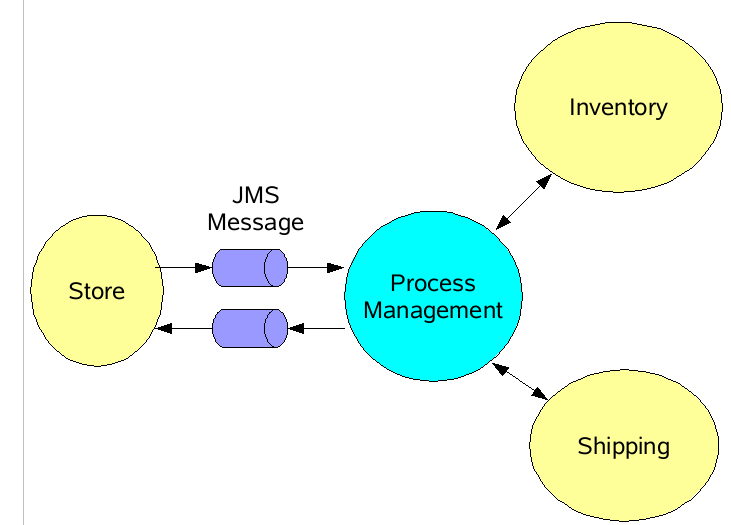
為了讓大家更好的理解,給大家提供了下面的這張圖,在這張圖中將HotSpot VM上的線程堆棧信息和線程池做了詳細的拆解,如下圖所示:
上圖中可以看出線程堆棧是由多個不同部分組成的。這些信息對問題分析都很重要,但對不同的問題模式的分析會使用不同的部分(問題模式會在後面的文章中做模擬和演示。)
現在通過這個分析樣例,給大家詳細解釋一下HoteSpot上線程堆棧信息中的各個組成部分:
# Full thread dump標示符
“Full thread dump”是一個全局唯一的關鍵字,你可以在中間件和單機版本Java的線程堆棧信息的輸出日志中找到它(比如說在UNIX下使用:kill -3 <PID> )。這是線程堆棧快照的開始部分。
Full thread dump Java HotSpot(TM) 64-Bit Server VM (20.0-b11 mixed mode):
# Java EE 中間件,第三方以及自定義應用軟件中的線程
這個部分是整個線程堆棧的核心部分,也是通常需要花費最多分析時間的部分。堆棧中線程的個數取決你使用的中間件,第三方庫(可能會有獨立線程)以及你的應用程序(如果創建自定義線程,這通常不是一個很好的實踐)。
在我們的示例線程堆棧中,WebLogic是我們所使用的中間件。從Weblogic 9.2開始, 會使用一個用“’weblogic.kernel.Default (self-tuning)”唯一標識的能自行管理的線程池
"[STANDBY] ExecuteThread: '414' for queue: 'weblogic.kernel.Default (self-tuning)'" daemon prio=3 tid=0x000000010916a800 nid=0x2613 in Object.wait() [0xfffffffe9edff000]
java.lang.Thread.State: WAITING (on object monitor)
at java.lang.Object.wait(Native Method)
- waiting on <0xffffffff27d44de0> (a weblogic.work.ExecuteThread)
at java.lang.Object.wait(Object.java:485)
at weblogic.work.ExecuteThread.waitForRequest(ExecuteThread.java:160)
- locked <0xffffffff27d44de0> (a weblogic.work.ExecuteThread)
at weblogic.work.ExecuteThread.run(ExecuteThread.java:181)
# HotSpot VM 線程
這是一個有Hotspot VM管理的內部線程,用於執行內部的原生操作。一般你不用對此操太多心,除非你(通過相關的線程堆棧以及 prstat或者原生線程Id)發現很高的CPU占用率.
"VM Periodic Task Thread" prio=3 tid=0x0000000101238800 nid=0x19 waiting on condition
# HotSpot GC 線程
當使用 HotSpot 進行並行 GC (如今在使用多個物理核心的環境下很常見), 默認創建的HotSpot VM 或者每個JVM管理一個有特定標識的GC線程時. 這些GC線程可以讓VM以並行的方式執行其周期性的GC清理, 這會導致GC時間的總體減少;與此同時的代價是CPU的使用時間會增加.
"GC task thread#0 (ParallelGC)" prio=3 tid=0x0000000100120000 nid=0x3 runnable
"GC task thread#1 (ParallelGC)" prio=3 tid=0x0000000100131000 nid=0x4 runnable
………………………………………………………………………………………………………………………………………………………………
這事非常關鍵的數據,因為當你遇到跟GC有關的問題,諸如過度GC、內存洩露等問題是,你將可以利用這些線程的原生Id值關聯的操作系統或者Java線程,進而發現任何對CPI時間的高占用. 未來的文章你將會了解到如何識別並診斷這樣的問題.
# JNI 全局引用計數
JNI (Java 本地接口)的全局引用就是從本地代碼到由Java垃圾收集器管理的Java對象的基本的對象引用. 它的角色就是阻止對仍然在被本地代碼使用,但是技術上已經不是Java代碼中的“活動的”引用了的對象的垃圾收集.
同時為了偵測JNI相關的洩露而留意JNI引用也很重要. 如果你的程序直接使用了JNI,或者像監聽器這樣的第三方工具,就容易造成本地的內存洩露.
JNI global references: 1925
# Java 堆棧使用視圖
這些數據被添加回了 JDK 1 .6 ,向你提供有關Hotspot堆棧的一個簡短而快速的視圖. 我發現它在當我處理帶有過高CPU占用的GC相關的問題時非常有用,你可以在一個單獨的快照中同時看到線程堆棧以及Java堆的信息,讓你當時就可以在一個特定的Java堆內存空間中解析(或者排除)出任何的關鍵點. 你如在我們的示例線程堆棧中所見,Java 的堆 OldGen 超出了最大值!
Heap
PSYoungGen total 466944K, used 178734K [0xffffffff45c00000, 0xffffffff70800000, 0xffffffff70800000)
eden space 233472K, 76% used [0xffffffff45c00000,0xffffffff50ab7c50,0xffffffff54000000)
from space 233472K, 0% used [0xffffffff62400000,0xffffffff62400000,0xffffffff70800000)
to space 233472K, 0% used [0xffffffff54000000,0xffffffff54000000,0xffffffff62400000)
PSOldGen total 1400832K, used 1400831K [0xfffffffef0400000, 0xffffffff45c00000, 0xffffffff45c00000)
object space 1400832K, 99% used [0xfffffffef0400000,0xffffffff45bfffb8,0xffffffff45c00000)
PSPermGen total 262144K, used 248475K [0xfffffffed0400000, 0xfffffffee0400000, 0xfffffffef0400000)
object space 262144K, 94% used [0xfffffffed0400000,0xfffffffedf6a6f08,0xfffffffee0400000)
我希望這篇文章能對你理解Hotspot VM線程堆棧的基本信息有所幫助。下一篇文章將會向你提供有關IBM VM的線程堆棧概述和分析